 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabBuilder: Protocol-Grounded 3D Layout Generation for Interactable and Safe Laboratory
May 04, 2026Automated laboratories hold the promise of accelerating scientific discovery, yet their deployment is bottlenecked by the difficulty of designing safe and executable environments. While simulator-based design offers scalability, existing 3D scene generation methods are primarily tailored for household settings, optimizing for visual plausibility while neglecting the rigorous functional semantics and safety constraints essential for scientific experimentation. We present LabBuilder, an end-to-end system that generates and verifies 3D laboratory layouts from concise textual specifications. It operates through three tightly coupled components: LabForge first curates a meta-dataset of annotated assets and chemical knowledge, translating natural language specifications into structured protocols; building on these protocols, LabGen synthesizes laboratory layouts via an iterative, constraint-aware optimization strategy; finally, LabTouchstone evaluates the resulting layouts as a unified benchmark. Extensive experiments demonstrate that LabBuilder significantly outperforms existing state-of-the-art methods, producing laboratory environments that are not only realistic but also functionally valid and safe for complex experimental workflows.
Position: Intelligent Science Laboratory Requires the Integration of Cognitive and Embodied AI
Jun 24, 2025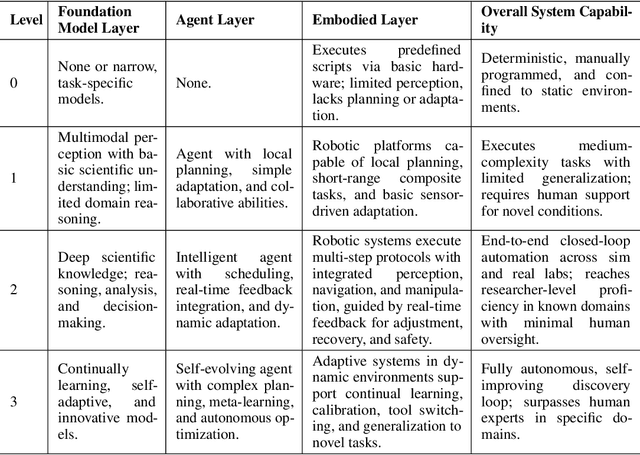
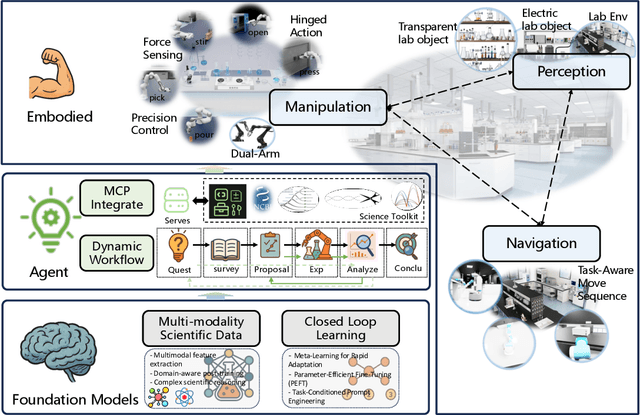
Scientific discovery has long been constrained by human limitations in expertise, physical capability, and sleep cycles. The recent rise of AI scientists and automated laboratories has accelerated both the cognitive and operational aspects of research. However, key limitations persist: AI systems are often confined to virtual environments, while automated laboratories lack the flexibility and autonomy to adaptively test new hypotheses in the physical world. Recent advances in embodied AI, such as generalist robot foundation models, diffusion-based action policies, fine-grained manipulation learning, and sim-to-real transfer, highlight the promise of integrating cognitive and embodied intelligence. This convergence opens the door to closed-loop systems that support iterative, autonomous experimentation and the possibility of serendipitous discovery. In this position paper, we propose the paradigm of Intelligent Science Laboratories (ISLs): a multi-layered, closed-loop framework that deeply integrates cognitive and embodied intelligence. ISLs unify foundation models for scientific reasoning, agent-based workflow orchestration, and embodied agents for robust physical experimentation. We argue that such systems are essential for overcoming the current limitations of scientific discovery and for realizing the full transformative potential of AI-driven science.
Transferable Adversarial Attacks on SAM and Its Downstream Models
Oct 29, 2024The utilization of large foundational models has a dilemma: while fine-tuning downstream tasks from them holds promise for making use of the well-generalized knowledge in practical applications, their open accessibility also poses threats of adverse usage. This paper, for the first time, explores the feasibility of adversarial attacking various downstream models fine-tuned from the segment anything model (SAM), by solely utilizing the information from the open-sourced SAM. In contrast to prevailing transfer-based adversarial attacks, we demonstrate the existence of adversarial dangers even without accessing the downstream task and dataset to train a similar surrogate model. To enhance the effectiveness of the adversarial attack towards models fine-tuned on unknown datasets, we propose a universal meta-initialization (UMI) algorithm to extract the intrinsic vulnerability inherent in the foundation model, which is then utilized as the prior knowledge to guide the generation of adversarial perturbations. Moreover, by formulating the gradient difference in the attacking process between the open-sourced SAM and its fine-tuned downstream models, we theoretically demonstrate that a deviation occurs in the adversarial update direction by directly maximizing the distance of encoded feature embeddings in the open-sourced SAM. Consequently, we propose a gradient robust loss that simulates the associated uncertainty with gradient-based noise augmentation to enhance the robustness of generated adversarial examples (AEs) towards this deviation, thus improving the transferability. Extensive experiments demonstrate the effectiveness of the proposed universal meta-initialized and gradient robust adversarial attack (UMI-GRAT) toward SAMs and their downstream models. Code is available at https://github.com/xiasong0501/GRAT.
Toward Scalable Image Feature Compression: A Content-Adaptive and Diffusion-Based Approach
Oct 08, 2024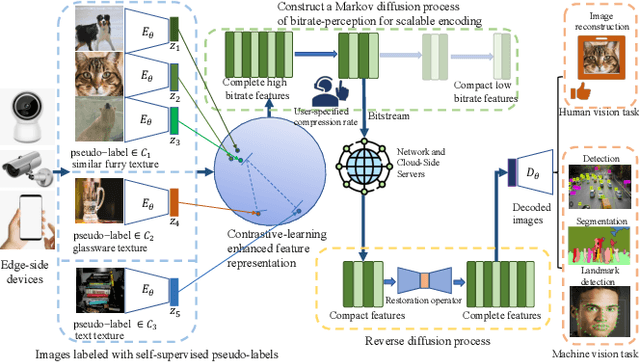
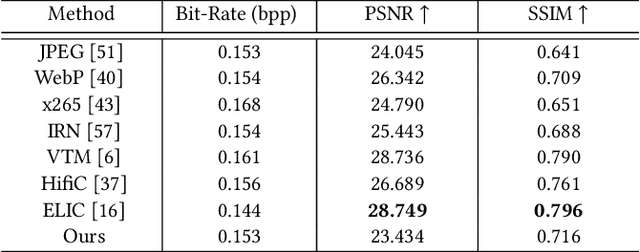

Traditional image codecs emphasize signal fidelity and human perception, often at the expense of machine vision tasks. Deep learning methods have demonstrated promising coding performance by utilizing rich semantic embeddings optimized for both human and machine vision. However, these compact embeddings struggle to capture fine details such as contours and textures, resulting in imperfect reconstructions. Furthermore, existing learning-based codecs lack scalability. To address these limitations, this paper introduces a content-adaptive diffusion model for scalable image compression. The proposed method encodes fine textures through a diffusion process, enhancing perceptual quality while preserving essential features for machine vision tasks. The approach employs a Markov palette diffusion model combined with widely used feature extractors and image generators, enabling efficient data compression. By leveraging collaborative texture-semantic feature extraction and pseudo-label generation, the method accurately captures texture information. A content-adaptive Markov palette diffusion model is then applied to represent both low-level textures and high-level semantic content in a scalable manner. This framework offers flexible control over compression ratios by selecting intermediate diffusion states, eliminating the need for retraining deep learning models at different operating points. Extensive experiments demonstrate the effectiveness of the proposed framework in both image reconstruction and downstream machine vision tasks such as object detection, segmentation, and facial landmark detection, achieving superior perceptual quality compared to state-of-the-art methods.
ShapeMamba-EM: Fine-Tuning Foundation Model with Local Shape Descriptors and Mamba Blocks for 3D EM Image Segmentation
Aug 26, 2024
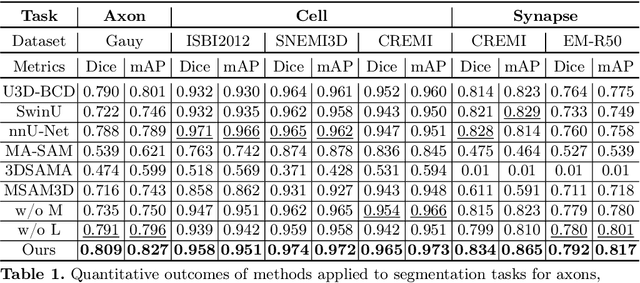
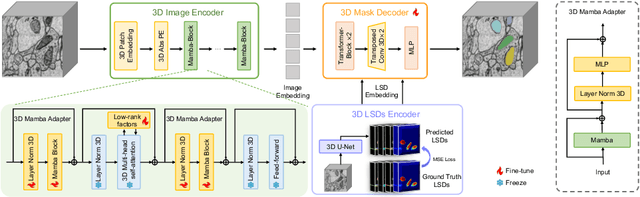
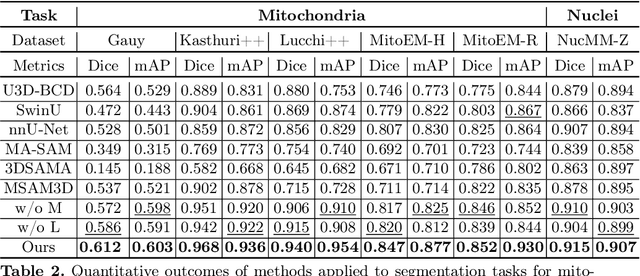
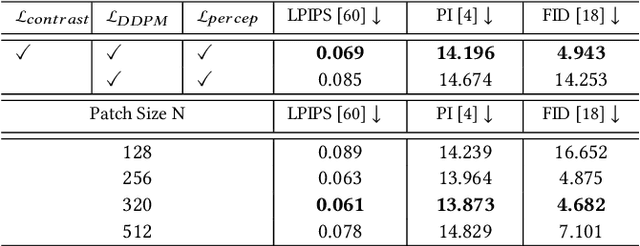
Electron microscopy (EM) imaging offers unparalleled resolution for analyzing neural tissues, crucial for uncovering the intricacies of synaptic connections and neural processes fundamental to understanding behavioral mechanisms. Recently, the foundation models have demonstrated impressive performance across numerous natural and medical image segmentation tasks. However, applying these foundation models to EM segmentation faces significant challenges due to domain disparities. This paper presents ShapeMamba-EM, a specialized fine-tuning method for 3D EM segmentation, which employs adapters for long-range dependency modeling and an encoder for local shape description within the original foundation model. This approach effectively addresses the unique volumetric and morphological complexities of EM data. Tested over a wide range of EM images, covering five segmentation tasks and 10 datasets, ShapeMamba-EM outperforms existing methods, establishing a new standard in EM image segmentation and enhancing the understanding of neural tissue architecture.
Amodal Segmentation for Laparoscopic Surgery Video Instruments
Aug 02, 2024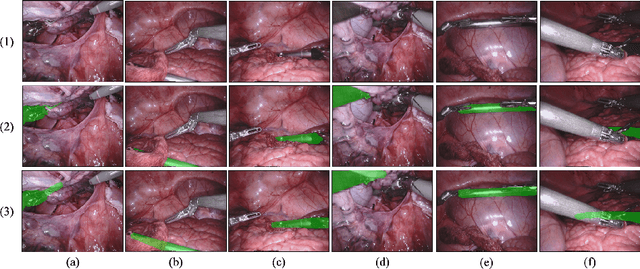
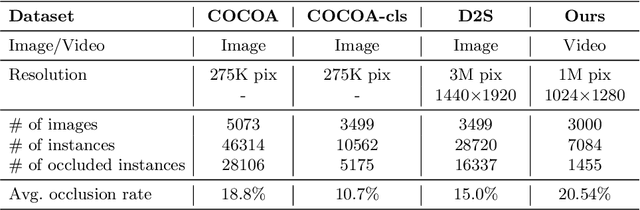
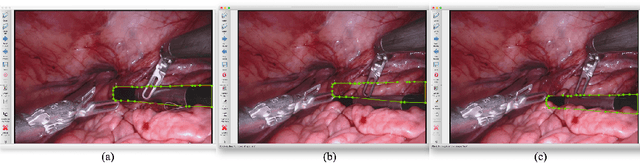

Segmentation of surgical instruments is crucial for enhancing surgeon performance and ensuring patient safety. Conventional techniques such as binary, semantic, and instance segmentation share a common drawback: they do not accommodate the parts of instruments obscured by tissues or other instruments. Precisely predicting the full extent of these occluded instruments can significantly improve laparoscopic surgeries by providing critical guidance during operations and assisting in the analysis of potential surgical errors, as well as serving educational purposes. In this paper, we introduce Amodal Segmentation to the realm of surgical instruments in the medical field. This technique identifies both the visible and occluded parts of an object. To achieve this, we introduce a new Amoal Instruments Segmentation (AIS) dataset, which was developed by reannotating each instrument with its complete mask, utilizing the 2017 MICCAI EndoVis Robotic Instrument Segmentation Challenge dataset. Additionally, we evaluate several leading amodal segmentation methods to establish a benchmark for this new dataset.
Neighborhood Consensus Contrastive Learning for Backward-Compatible Representation
Sep 09, 2021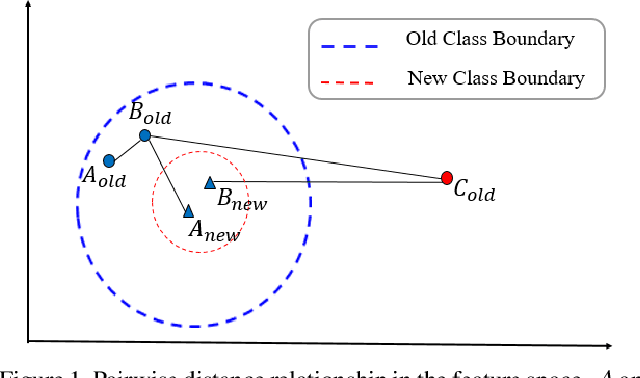
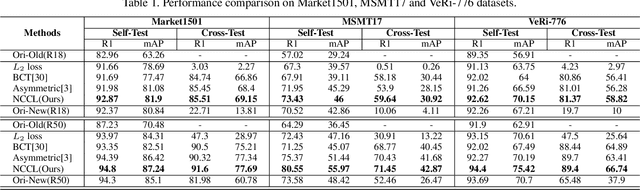
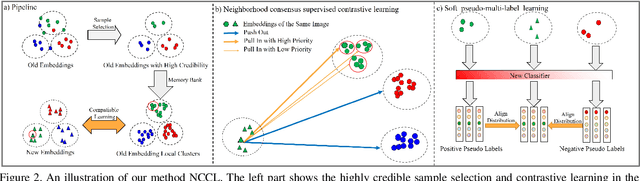
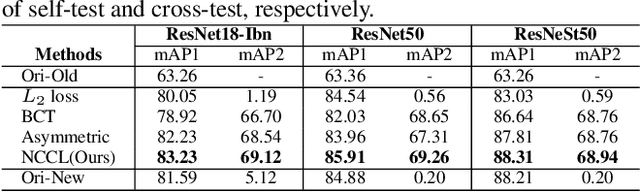
In object re-identification (ReID), the development of deep learning techniques often involves model updates and deployment. It is unbearable to re-embedding and re-index with the system suspended when deploying new models. Therefore, backward-compatible representation is proposed to enable "new" features to be compared with "old" features directly, which means that the database is active when there are both "new" and "old" features in it. Thus we can scroll-refresh the database or even do nothing on the database to update. The existing backward-compatible methods either require a strong overlap between old and new training data or simply conduct constraints at the instance level. Thus they are difficult in handling complicated cluster structures and are limited in eliminating the impact of outliers in old embeddings, resulting in a risk of damaging the discriminative capability of new features. In this work, we propose a Neighborhood Consensus Contrastive Learning (NCCL) method. With no assumptions about the new training data, we estimate the sub-cluster structures of old embeddings. A new embedding is constrained with multiple old embeddings in both embedding space and discrimination space at the sub-class level. The effect of outliers diminished, as the multiple samples serve as "mean teachers". Besides, we also propose a scheme to filter the old embeddings with low credibility, further improving the compatibility robustness. Our method ensures backward compatibility without impairing the accuracy of the new model. And it can even improve the new model's accuracy in most scenarios.
Classes Matter: A Fine-grained Adversarial Approach to Cross-domain Semantic Segmentation
Jul 17, 2020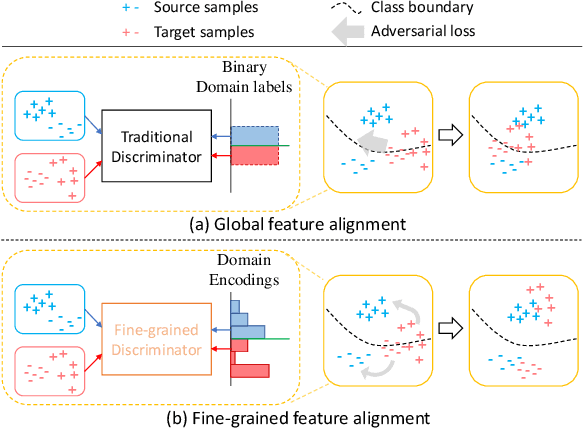
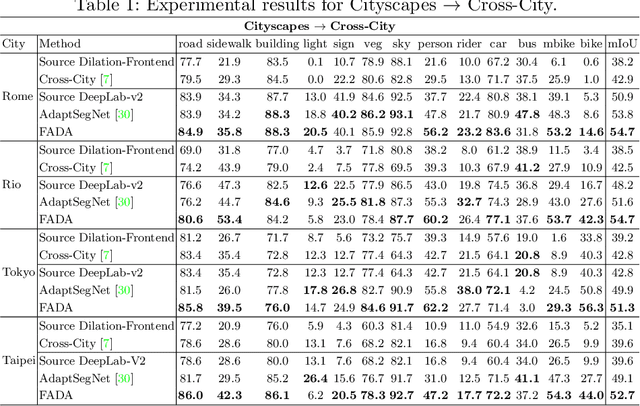
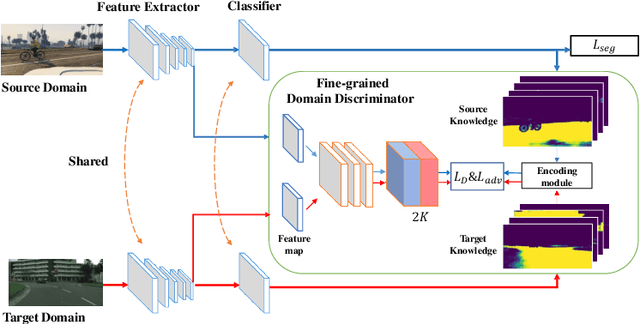
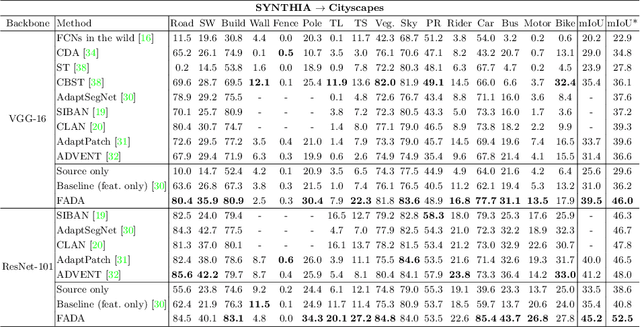
Despite great progress in supervised semantic segmentation,a large performance drop is usually observed when deploying the model in the wild. Domain adaptation methods tackle the issue by aligning the source domain and the target domain. However, most existing methods attempt to perform the alignment from a holistic view, ignoring the underlying class-level data structure in the target domain. To fully exploit the supervision in the source domain, we propose a fine-grained adversarial learning strategy for class-level feature alignment while preserving the internal structure of semantics across domains. We adopt a fine-grained domain discriminator that not only plays as a domain distinguisher, but also differentiates domains at class level. The traditional binary domain labels are also generalized to domain encodings as the supervision signal to guide the fine-grained feature alignment. An analysis with Class Center Distance (CCD) validates that our fine-grained adversarial strategy achieves better class-level alignment compared to other state-of-the-art methods. Our method is easy to implement and its effectiveness is evaluated on three classical domain adaptation tasks, i.e., GTA5 to Cityscapes, SYNTHIA to Cityscapes and Cityscapes to Cross-City. Large performance gains show that our method outperforms other global feature alignment based and class-wise alignment based counterparts. The code is publicly available at https://github.com/JDAI-CV/FADA.
Hard-Aware Fashion Attribute Classification
Jul 25, 2019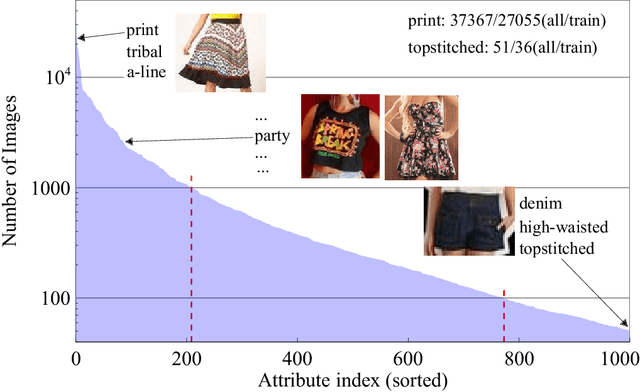
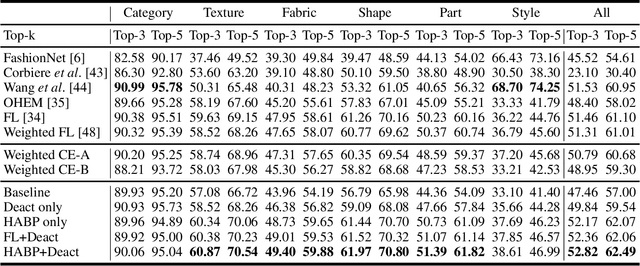
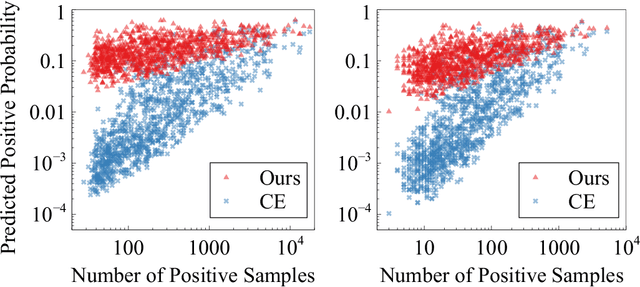
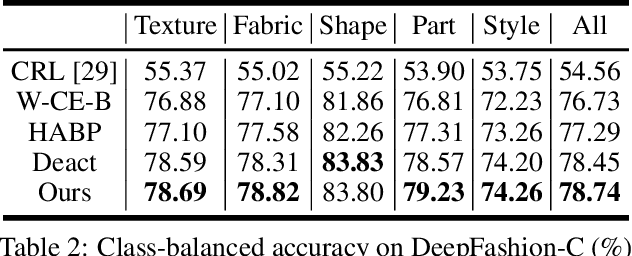
Fashion attribute classification is of great importance to many high-level tasks such as fashion item search, fashion trend analysis, fashion recommendation, etc. The task is challenging due to the extremely imbalanced data distribution, particularly the attributes with only a few positive samples. In this paper, we introduce a hard-aware pipeline to make full use of "hard" samples/attributes. We first propose Hard-Aware BackPropagation (HABP) to efficiently and adaptively focus on training "hard" data. Then for the identified hard labels, we propose to synthesize more complementary samples for training. To stabilize training, we extend semi-supervised GAN by directly deactivating outputs for synthetic complementary samples (Deact). In general, our method is more effective in addressing "hard" cases. HABP weights more on "hard" samples. For "hard" attributes with insufficient training data, Deact brings more stable synthetic samples for training and further improve the performance. Our method is verified on large scale fashion dataset, outperforming other state-of-the-art without any additional supervisions.
Exploring Object Relation in Mean Teacher for Cross-Domain Detection
Apr 25, 2019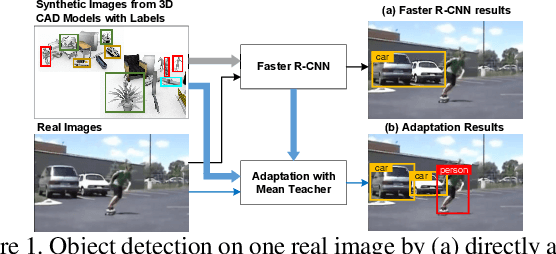
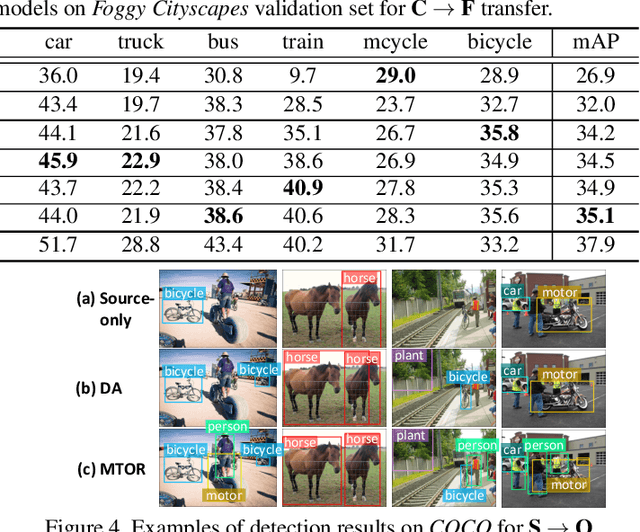
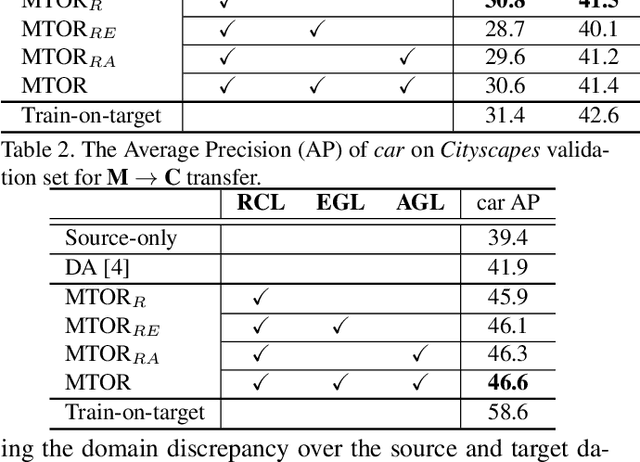
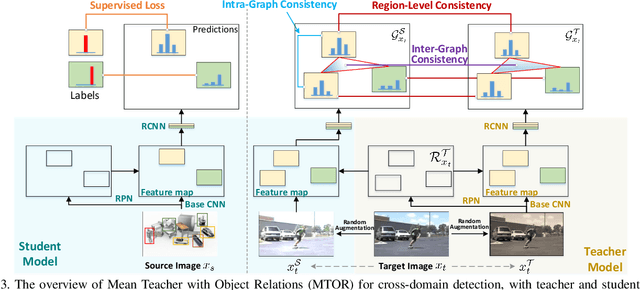
Rendering synthetic data (e.g., 3D CAD-rendered images) to generate annotations for learning deep models in vision tasks has attracted increasing attention in recent years. However, simply applying the models learnt on synthetic images may lead to high generalization error on real images due to domain shift. To address this issue, recent progress in cross-domain recognition has featured the Mean Teacher, which directly simulates unsupervised domain adaptation as semi-supervised learning. The domain gap is thus naturally bridged with consistency regularization in a teacher-student scheme. In this work, we advance this Mean Teacher paradigm to be applicable for cross-domain detection. Specifically, we present Mean Teacher with Object Relations (MTOR) that novelly remolds Mean Teacher under the backbone of Faster R-CNN by integrating the object relations into the measure of consistency cost between teacher and student modules. Technically, MTOR firstly learns relational graphs that capture similarities between pairs of regions for teacher and student respectively. The whole architecture is then optimized with three consistency regularizations: 1) region-level consistency to align the region-level predictions between teacher and student, 2) inter-graph consistency for matching the graph structures between teacher and student, and 3) intra-graph consistency to enhance the similarity between regions of same class within the graph of student. Extensive experiments are conducted on the transfers across Cityscapes, Foggy Cityscapes, and SIM10k, and superior results are reported when comparing to state-of-the-art approaches. More remarkably, we obtain a new record of single model: 22.8% of mAP on Syn2Real detection dataset.