 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unifying Understanding and Generation in the Era of Vision Foundation Models: A Survey from the Autoregression Perspective
Oct 29, 2024


Autoregression in large language models (LLMs) has shown impressive scalability by unifying all language tasks into the next token prediction paradigm. Recently, there is a growing interest in extending this success to vision foundation models. In this survey, we review the recent advances and discuss future directions for autoregressive vision foundation models. First, we present the trend for next generation of vision foundation models, i.e., unifying both understanding and generation in vision tasks. We then analyze the limitations of existing vision foundation models, and present a formal definition of autoregression with its advantages. Later, we categorize autoregressive vision foundation models from their vision tokenizers and autoregression backbones. Finally, we discuss several promising research challenges and directions. To the best of our knowledge, this is the first survey to comprehensively summarize autoregressive vision foundation models under the trend of unifying understanding and generation. A collection of related resources is available at https://github.com/EmmaSRH/ARVFM.
ShapeMamba-EM: Fine-Tuning Foundation Model with Local Shape Descriptors and Mamba Blocks for 3D EM Image Segmentation
Aug 26, 2024
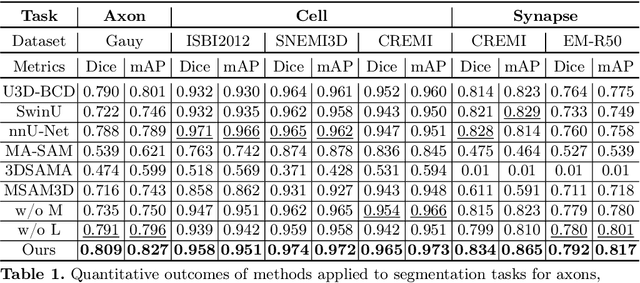
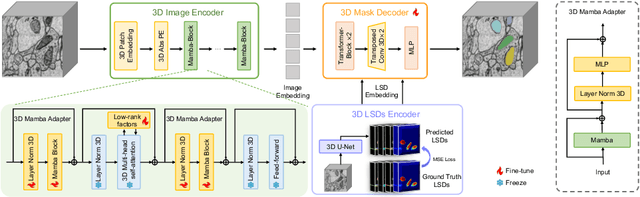
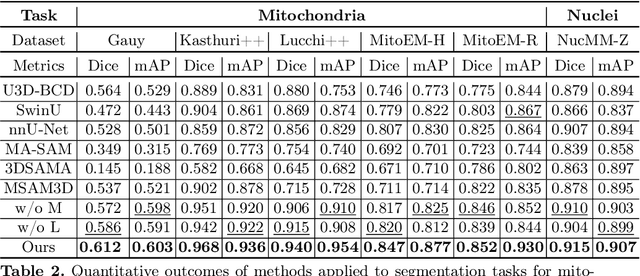
Electron microscopy (EM) imaging offers unparalleled resolution for analyzing neural tissues, crucial for uncovering the intricacies of synaptic connections and neural processes fundamental to understanding behavioral mechanisms. Recently, the foundation models have demonstrated impressive performance across numerous natural and medical image segmentation tasks. However, applying these foundation models to EM segmentation faces significant challenges due to domain disparities. This paper presents ShapeMamba-EM, a specialized fine-tuning method for 3D EM segmentation, which employs adapters for long-range dependency modeling and an encoder for local shape description within the original foundation model. This approach effectively addresses the unique volumetric and morphological complexities of EM data. Tested over a wide range of EM images, covering five segmentation tasks and 10 datasets, ShapeMamba-EM outperforms existing methods, establishing a new standard in EM image segmentation and enhancing the understanding of neural tissue architecture.
Amodal Segmentation for Laparoscopic Surgery Video Instruments
Aug 02, 2024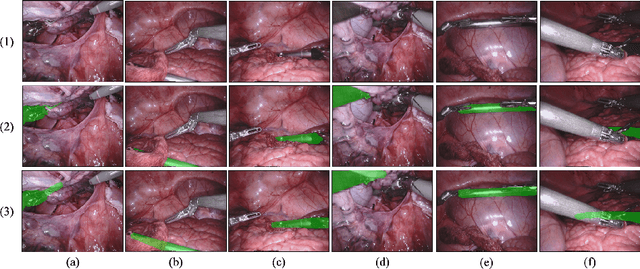
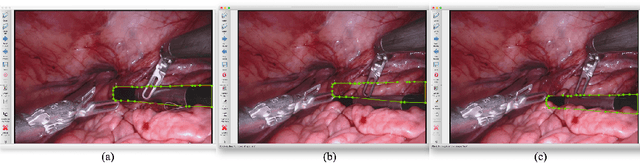

Segmentation of surgical instruments is crucial for enhancing surgeon performance and ensuring patient safety. Conventional techniques such as binary, semantic, and instance segmentation share a common drawback: they do not accommodate the parts of instruments obscured by tissues or other instruments. Precisely predicting the full extent of these occluded instruments can significantly improve laparoscopic surgeries by providing critical guidance during operations and assisting in the analysis of potential surgical errors, as well as serving educational purposes. In this paper, we introduce Amodal Segmentation to the realm of surgical instruments in the medical field. This technique identifies both the visible and occluded parts of an object. To achieve this, we introduce a new Amoal Instruments Segmentation (AIS) dataset, which was developed by reannotating each instrument with its complete mask, utilizing the 2017 MICCAI EndoVis Robotic Instrument Segmentation Challenge dataset. Additionally, we evaluate several leading amodal segmentation methods to establish a benchmark for this new dataset.
Human Perception-based Evaluation Criterion for Ultra-high Resolution Cell Membrane Segmentation
Oct 16, 2020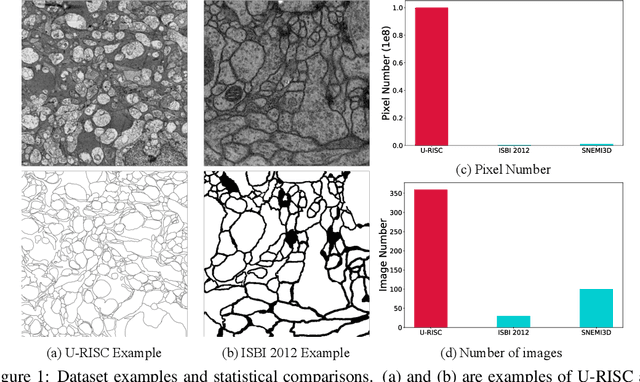

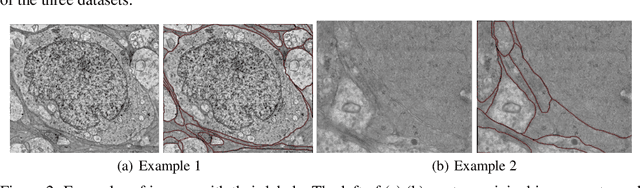

Computer vision technology is widely used in biological and medical data analysis and understanding. However, there are still two major bottlenecks in the field of cell membrane segmentation, which seriously hinder further research: lack of sufficient high-quality data and lack of suitable evaluation criteria. In order to solve these two problems, this paper first proposes an Ultra-high Resolution Image Segmentation dataset for the Cell membrane, called U-RISC, the largest annotated Electron Microscopy (EM) dataset for the Cell membrane with multiple iterative annotations and uncompressed high-resolution raw data. During the analysis process of the U-RISC, we found that the current popular segmentation evaluation criteria are inconsistent with human perception. This interesting phenomenon is confirmed by a subjective experiment involving twenty people. Furthermore, to resolve this inconsistency, we propose a new evaluation criterion called Perceptual Hausdorff Distance (PHD) to measure the quality of cell membrane segmentation results. Detailed performance comparison and discussion of classic segmentation methods along with two iterative manual annotation results under existing evaluation criteria and PHD is given.
Robust Medical Instrument Segmentation Challenge 2019
Mar 23, 2020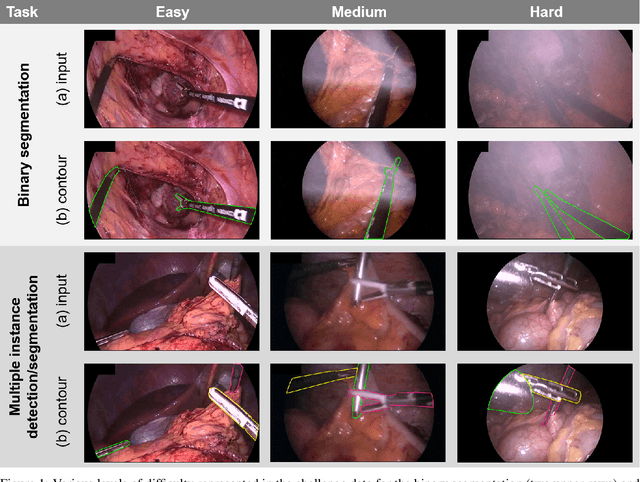
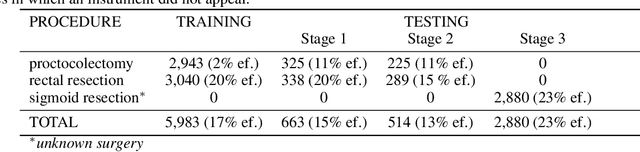
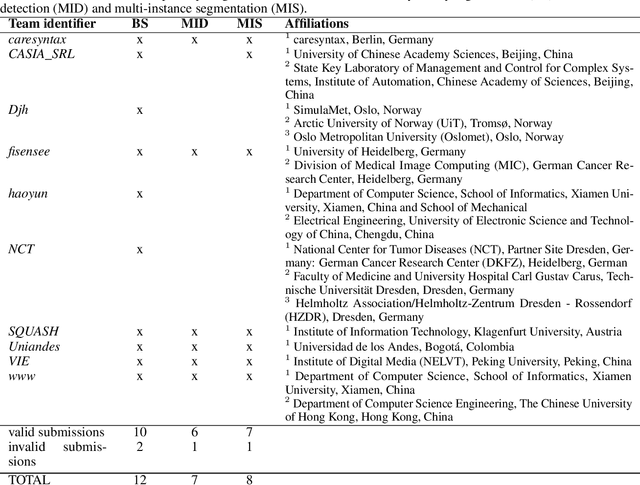
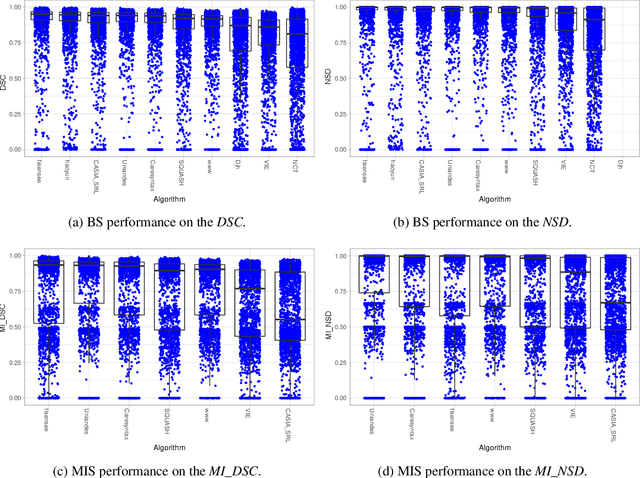
Intraoperative tracking of laparoscopic instruments is often a prerequisite for computer and robotic-assisted interventions. While numerous methods for detecting, segmenting and tracking of medical instruments based on endoscopic video images have been proposed in the literature, key limitations remain to be addressed: Firstly, robustness, that is, the reliable performance of state-of-the-art methods when run on challenging images (e.g. in the presence of blood, smoke or motion artifacts). Secondly, generalization; algorithms trained for a specific intervention in a specific hospital should generalize to other interventions or institutions. In an effort to promote solutions for these limitations, we organized the Robust Medical Instrument Segmentation (ROBUST-MIS) challenge as an international benchmarking competition with a specific focus on the robustness and generalization capabilities of algorithms. For the first time in the field of endoscopic image processing, our challenge included a task on binary segmentation and also addressed multi-instance detection and segmentation. The challenge was based on a surgical data set comprising 10,040 annotated images acquired from a total of 30 surgical procedures from three different types of surgery. The validation of the competing methods for the three tasks (binary segmentation, multi-instance detection and multi-instance segmentation) was performed in three different stages with an increasing domain gap between the training and the test data. The results confirm the initial hypothesis, namely that algorithm performance degrades with an increasing domain gap. While the average detection and segmentation quality of the best-performing algorithms is high, future research should concentrate on detection and segmentation of small, crossing, moving and transparent instrument(s) (parts).