 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape Matters: Detecting Vertebral Fractures Using Differentiable Point-Based Shape Decoding
Dec 08, 2023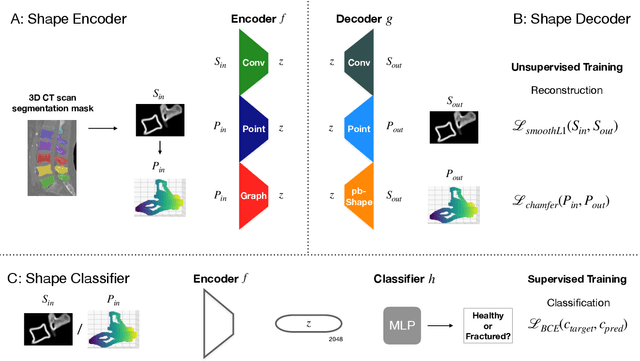
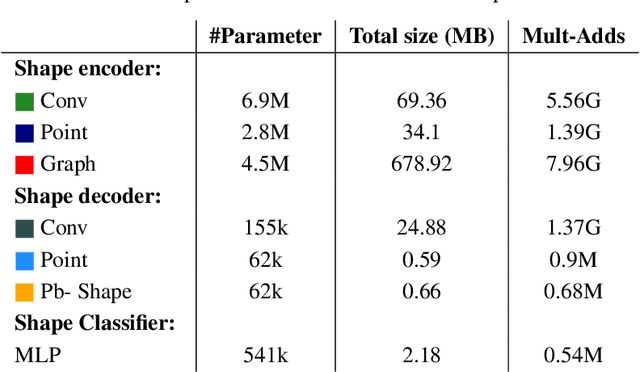
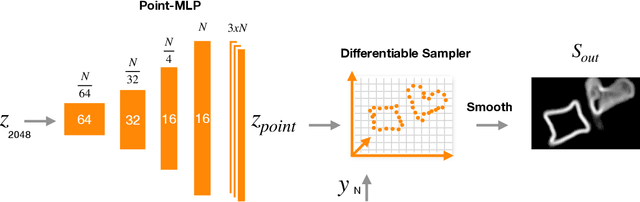
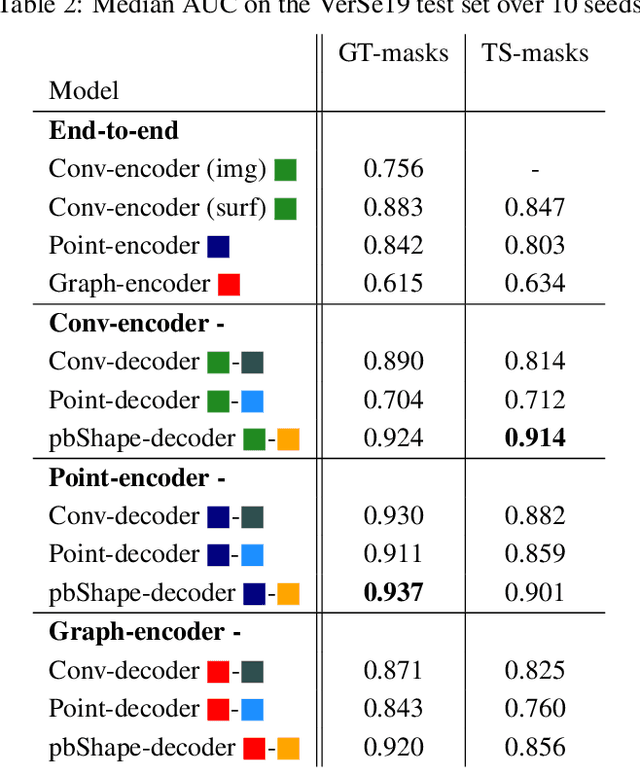
Degenerative spinal pathologies are highly prevalent among the elderly population. Timely diagnosis of osteoporotic fractures and other degenerative deformities facilitates proactive measures to mitigate the risk of severe back pain and disability. In this study, we specifically explore the use of shape auto-encoders for vertebrae, taking advantage of advancements in automated multi-label segmentation and the availability of large datasets for unsupervised learning. Our shape auto-encoders are trained on a large set of vertebrae surface patches, leveraging the vast amount of available data for vertebra segmentation. This addresses the label scarcity problem faced when learning shape information of vertebrae from image intensities. Based on the learned shape features we train an MLP to detect vertebral body fractures. Using segmentation masks that were automatically generated using the TotalSegmentator, our proposed method achieves an AUC of 0.901 on the VerSe19 testset. This outperforms image-based and surface-based end-to-end trained models. Additionally, our results demonstrate that pre-training the models in an unsupervised manner enhances geometric methods like PointNet and DGCNN. Our findings emphasise the advantages of explicitly learning shape features for diagnosing osteoporotic vertebrae fractures. This approach improves the reliability of classification results and reduces the need for annotated labels. This study provides novel insights into the effectiveness of various encoder-decoder models for shape analysis of vertebrae and proposes a new decoder architecture: the point-based shape decoder.
Heidelberg Colorectal Data Set for Surgical Data Science in the Sensor Operating Room
May 28, 2020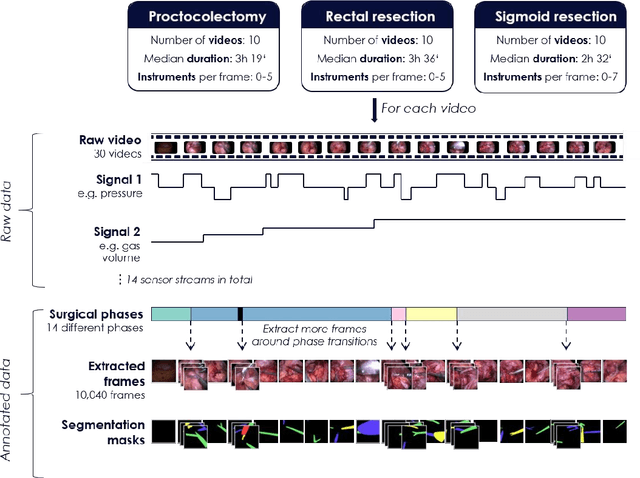
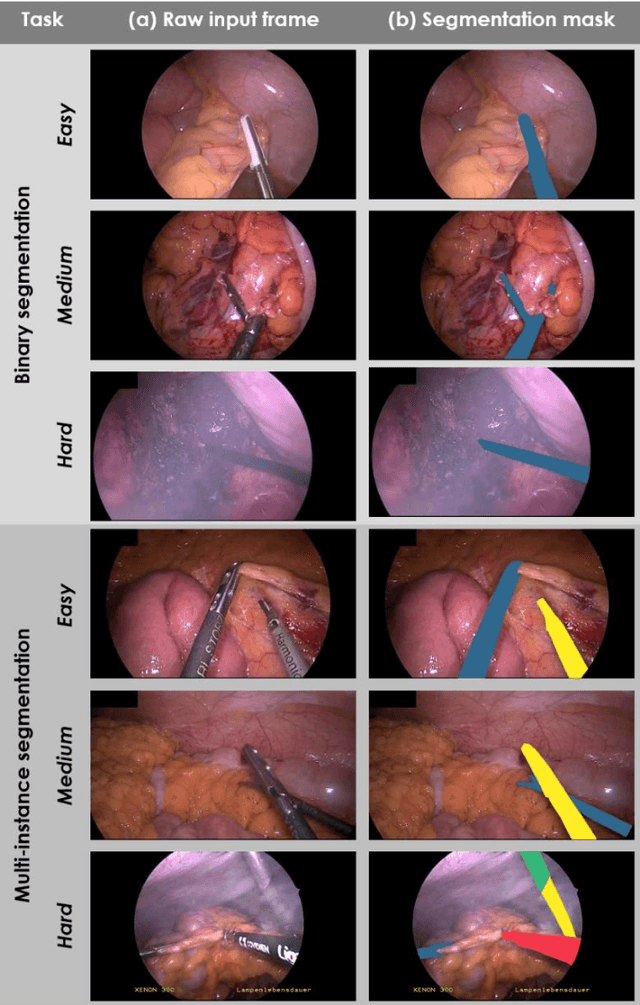
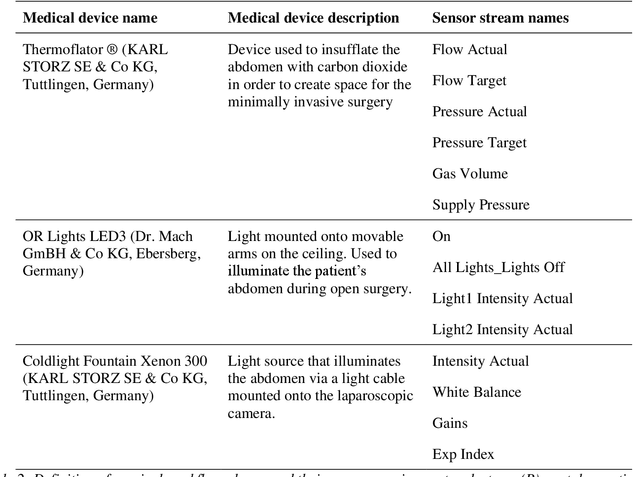
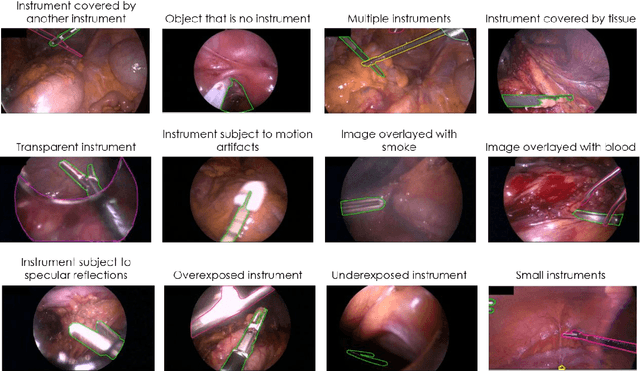
Image-based tracking of medical instruments is an integral part of many surgical data science applications. Previous research has addressed the tasks of detecting, segmenting and tracking medical instruments based on laparoscopic video data. However, the methods proposed still tend to fail when applied to challenging images and do not generalize well to data they have not been trained on. This paper introduces the Heidelberg Colorectal (HeiCo) data set - the first publicly available data set enabling comprehensive benchmarking of medical instrument detection and segmentation algorithms with a specific emphasis on robustness and generalization capabilities of the methods. Our data set comprises 30 laparoscopic videos and corresponding sensor data from medical devices in the operating room for three different types of laparoscopic surgery. Annotations include surgical phase labels for all frames in the videos as well as instance-wise segmentation masks for surgical instruments in more than 10,000 individual frames. The data has successfully been used to organize international competitions in the scope of the Endoscopic Vision Challenges (EndoVis) 2017 and 2019.
Robust Medical Instrument Segmentation Challenge 2019
Mar 23, 2020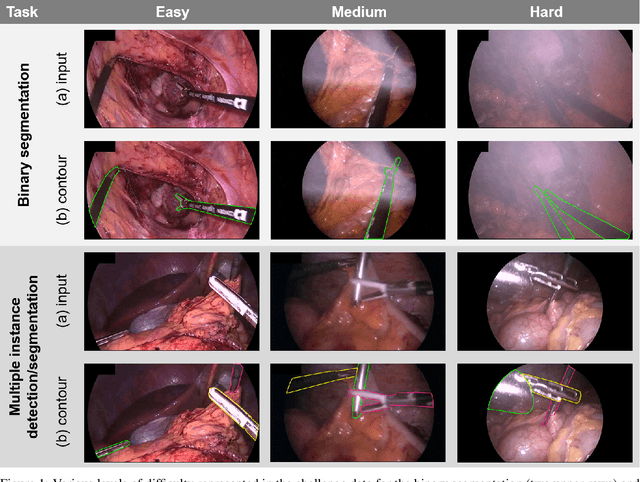
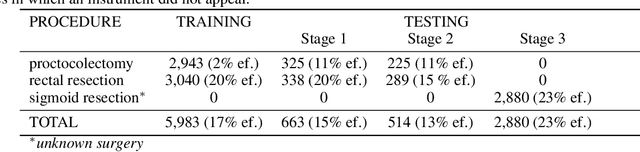
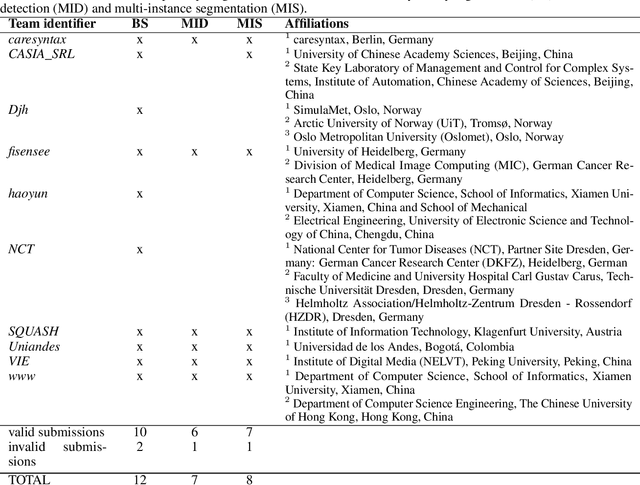
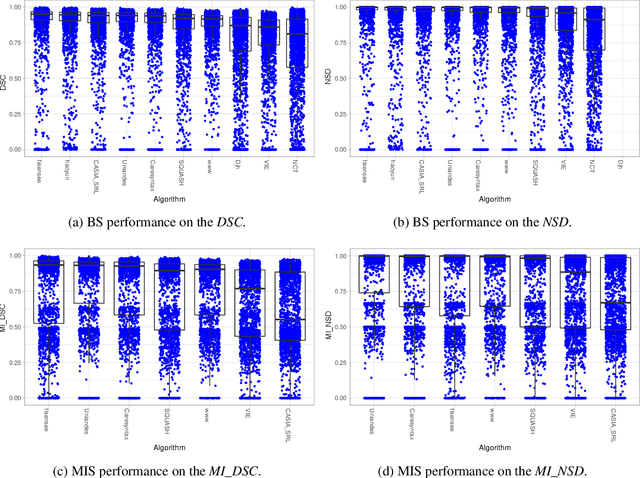
Intraoperative tracking of laparoscopic instruments is often a prerequisite for computer and robotic-assisted interventions. While numerous methods for detecting, segmenting and tracking of medical instruments based on endoscopic video images have been proposed in the literature, key limitations remain to be addressed: Firstly, robustness, that is, the reliable performance of state-of-the-art methods when run on challenging images (e.g. in the presence of blood, smoke or motion artifacts). Secondly, generalization; algorithms trained for a specific intervention in a specific hospital should generalize to other interventions or institutions. In an effort to promote solutions for these limitations, we organized the Robust Medical Instrument Segmentation (ROBUST-MIS) challenge as an international benchmarking competition with a specific focus on the robustness and generalization capabilities of algorithms. For the first time in the field of endoscopic image processing, our challenge included a task on binary segmentation and also addressed multi-instance detection and segmentation. The challenge was based on a surgical data set comprising 10,040 annotated images acquired from a total of 30 surgical procedures from three different types of surgery. The validation of the competing methods for the three tasks (binary segmentation, multi-instance detection and multi-instance segmentation) was performed in three different stages with an increasing domain gap between the training and the test data. The results confirm the initial hypothesis, namely that algorithm performance degrades with an increasing domain gap. While the average detection and segmentation quality of the best-performing algorithms is high, future research should concentrate on detection and segmentation of small, crossing, moving and transparent instrument(s) (parts).