 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDG-TTA: Out-of-domain medical image segmentation through Domain Generalization and Test-Time Adaptation
Dec 22, 2023



Applying pre-trained medical segmentation models on out-of-domain images often yields predictions of insufficient quality. Several strategies have been proposed to maintain model performance, such as finetuning or unsupervised- and source-free domain adaptation. These strategies set restrictive requirements for data availability. In this study, we propose to combine domain generalization and test-time adaptation to create a highly effective approach for reusing pre-trained models in unseen target domains. Domain-generalized pre-training on source data is used to obtain the best initial performance in the target domain. We introduce the MIND descriptor previously used in image registration tasks as a further technique to achieve generalization and present superior performance for small-scale datasets compared to existing approaches. At test-time, high-quality segmentation for every single unseen scan is ensured by optimizing the model weights for consistency given different image augmentations. That way, our method enables separate use of source and target data and thus removes current data availability barriers. Moreover, the presented method is highly modular as it does not require specific model architectures or prior knowledge of involved domains and labels. We demonstrate this by integrating it into the nnUNet, which is currently the most popular and accurate framework for medical image segmentation. We employ multiple datasets covering abdominal, cardiac, and lumbar spine scans and compose several out-of-domain scenarios in this study. We demonstrate that our method, combined with pre-trained whole-body CT models, can effectively segment MR images with high accuracy in all of the aforementioned scenarios. Open-source code can be found here: https://github.com/multimodallearning/DG-TTA
Shape Matters: Detecting Vertebral Fractures Using Differentiable Point-Based Shape Decoding
Dec 08, 2023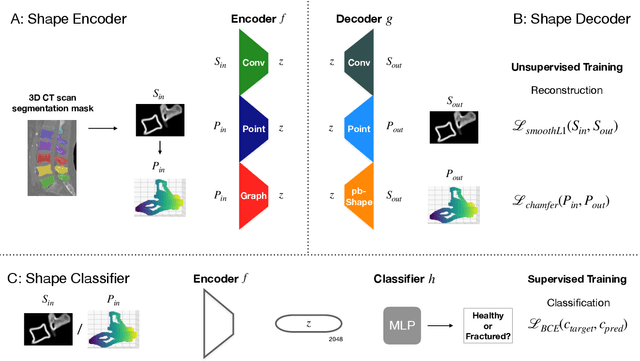
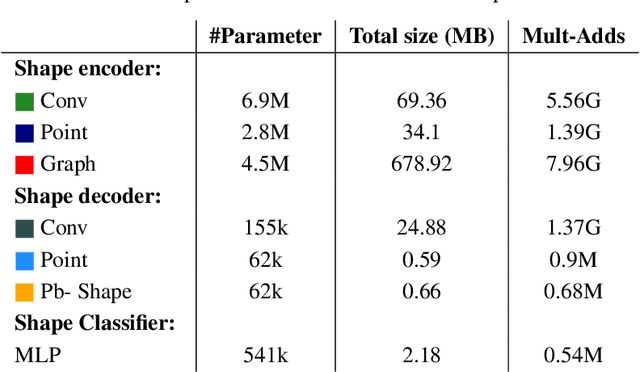
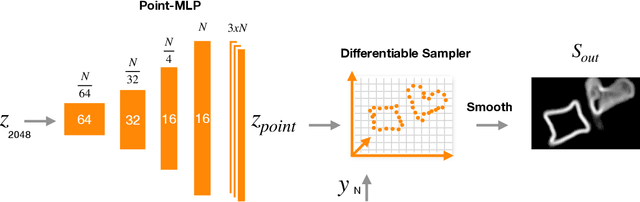
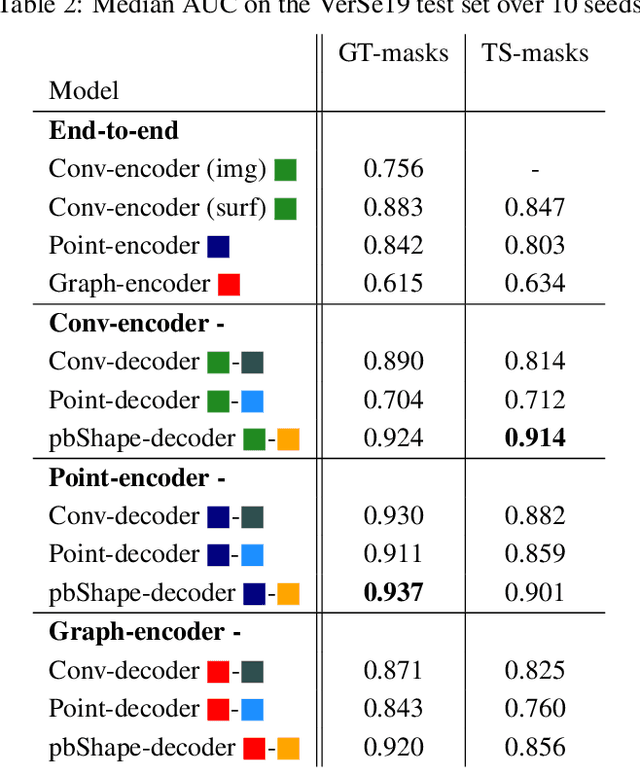
Degenerative spinal pathologies are highly prevalent among the elderly population. Timely diagnosis of osteoporotic fractures and other degenerative deformities facilitates proactive measures to mitigate the risk of severe back pain and disability. In this study, we specifically explore the use of shape auto-encoders for vertebrae, taking advantage of advancements in automated multi-label segmentation and the availability of large datasets for unsupervised learning. Our shape auto-encoders are trained on a large set of vertebrae surface patches, leveraging the vast amount of available data for vertebra segmentation. This addresses the label scarcity problem faced when learning shape information of vertebrae from image intensities. Based on the learned shape features we train an MLP to detect vertebral body fractures. Using segmentation masks that were automatically generated using the TotalSegmentator, our proposed method achieves an AUC of 0.901 on the VerSe19 testset. This outperforms image-based and surface-based end-to-end trained models. Additionally, our results demonstrate that pre-training the models in an unsupervised manner enhances geometric methods like PointNet and DGCNN. Our findings emphasise the advantages of explicitly learning shape features for diagnosing osteoporotic vertebrae fractures. This approach improves the reliability of classification results and reduces the need for annotated labels. This study provides novel insights into the effectiveness of various encoder-decoder models for shape analysis of vertebrae and proposes a new decoder architecture: the point-based shape decoder.
A denoised Mean Teacher for domain adaptive point cloud registration
Jul 04, 2023



Point cloud-based medical registration promises increased computational efficiency, robustness to intensity shifts, and anonymity preservation but is limited by the inefficacy of unsupervised learning with similarity metrics. Supervised training on synthetic deformations is an alternative but, in turn, suffers from the domain gap to the real domain. In this work, we aim to tackle this gap through domain adaptation. Self-training with the Mean Teacher is an established approach to this problem but is impaired by the inherent noise of the pseudo labels from the teacher. As a remedy, we present a denoised teacher-student paradigm for point cloud registration, comprising two complementary denoising strategies. First, we propose to filter pseudo labels based on the Chamfer distances of teacher and student registrations, thus preventing detrimental supervision by the teacher. Second, we make the teacher dynamically synthesize novel training pairs with noise-free labels by warping its moving inputs with the predicted deformations. Evaluation is performed for inhale-to-exhale registration of lung vessel trees on the public PVT dataset under two domain shifts. Our method surpasses the baseline Mean Teacher by 13.5/62.8%, consistently outperforms diverse competitors, and sets a new state-of-the-art accuracy (TRE=2.31mm). Code is available at https://github.com/multimodallearning/denoised_mt_pcd_reg.
Unsupervised 3D registration through optimization-guided cyclical self-training
Jun 29, 2023


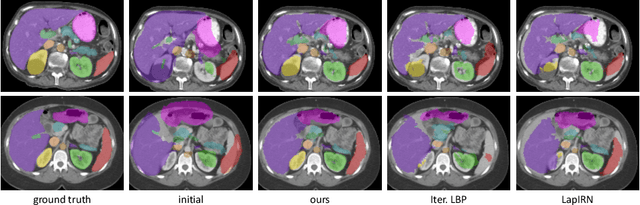
State-of-the-art deep learning-based registration methods employ three different learning strategies: supervised learning, which requires costly manual annotations, unsupervised learning, which heavily relies on hand-crafted similarity metrics designed by domain experts, or learning from synthetic data, which introduces a domain shift. To overcome the limitations of these strategies, we propose a novel self-supervised learning paradigm for unsupervised registration, relying on self-training. Our idea is based on two key insights. Feature-based differentiable optimizers 1) perform reasonable registration even from random features and 2) stabilize the training of the preceding feature extraction network on noisy labels. Consequently, we propose cyclical self-training, where pseudo labels are initialized as the displacement fields inferred from random features and cyclically updated based on more and more expressive features from the learning feature extractor, yielding a self-reinforcement effect. We evaluate the method for abdomen and lung registration, consistently surpassing metric-based supervision and outperforming diverse state-of-the-art competitors. Source code is available at https://github.com/multimodallearning/reg-cyclical-self-train.
Anatomy-guided domain adaptation for 3D in-bed human pose estimation
Nov 22, 20223D human pose estimation is a key component of clinical monitoring systems. The clinical applicability of deep pose estimation models, however, is limited by their poor generalization under domain shifts along with their need for sufficient labeled training data. As a remedy, we present a novel domain adaptation method, adapting a model from a labeled source to a shifted unlabeled target domain. Our method comprises two complementary adaptation strategies based on prior knowledge about human anatomy. First, we guide the learning process in the target domain by constraining predictions to the space of anatomically plausible poses. To this end, we embed the prior knowledge into an anatomical loss function that penalizes asymmetric limb lengths, implausible bone lengths, and implausible joint angles. Second, we propose to filter pseudo labels for self-training according to their anatomical plausibility and incorporate the concept into the Mean Teacher paradigm. We unify both strategies in a point cloud-based framework applicable to unsupervised and source-free domain adaptation. Evaluation is performed for in-bed pose estimation under two adaptation scenarios, using the public SLP dataset and a newly created dataset. Our method consistently outperforms various state-of-the-art domain adaptation methods, surpasses the baseline model by 31%/66%, and reduces the domain gap by 65%/82%. Source code is available at https://github.com/multimodallearning/da-3dhpe-anatomy.
Adapting the Mean Teacher for keypoint-based lung registration under geometric domain shifts
Jul 01, 2022


Recent deep learning-based methods for medical image registration achieve results that are competitive with conventional optimization algorithms at reduced run times. However, deep neural networks generally require plenty of labeled training data and are vulnerable to domain shifts between training and test data. While typical intensity shifts can be mitigated by keypoint-based registration, these methods still suffer from geometric domain shifts, for instance, due to different fields of view. As a remedy, in this work, we present a novel approach to geometric domain adaptation for image registration, adapting a model from a labeled source to an unlabeled target domain. We build on a keypoint-based registration model, combining graph convolutions for geometric feature learning with loopy belief optimization, and propose to reduce the domain shift through self-ensembling. To this end, we embed the model into the Mean Teacher paradigm. We extend the Mean Teacher to this context by 1) adapting the stochastic augmentation scheme and 2) combining learned feature extraction with differentiable optimization. This enables us to guide the learning process in the unlabeled target domain by enforcing consistent predictions of the learning student and the temporally averaged teacher model. We evaluate the method for exhale-to-inhale lung CT registration under two challenging adaptation scenarios (DIR-Lab 4D CT to COPD, COPD to Learn2Reg). Our method consistently improves on the baseline model by 50%/47% while even matching the accuracy of models trained on target data. Source code is available at https://github.com/multimodallearning/registration-da-mean-teacher.