 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeidelberg Colorectal Data Set for Surgical Data Science in the Sensor Operating Room
May 28, 2020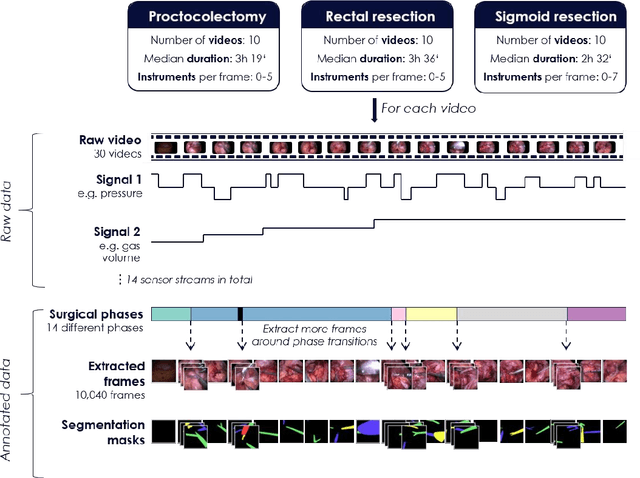
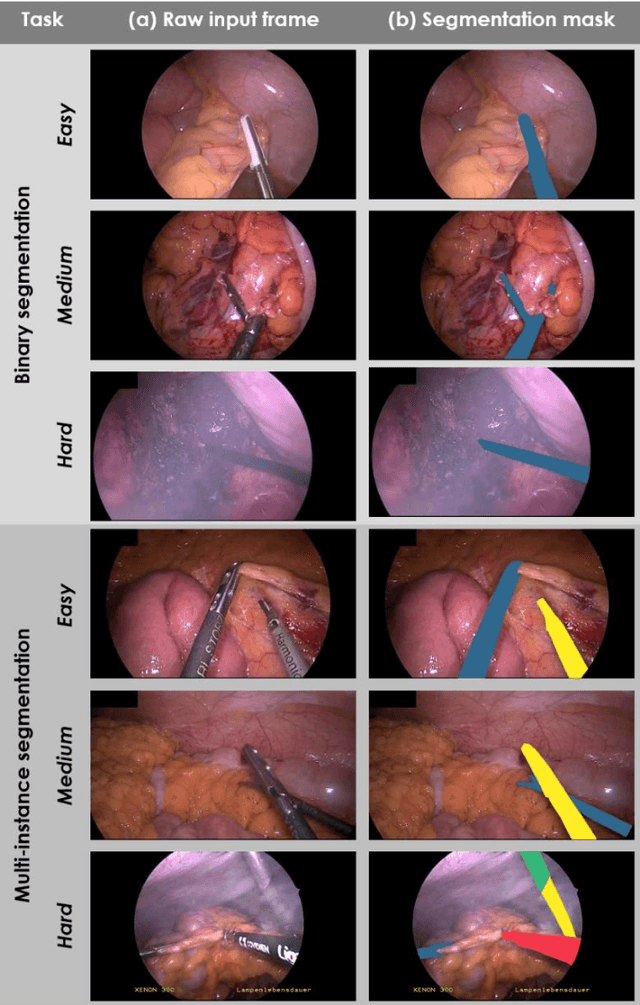
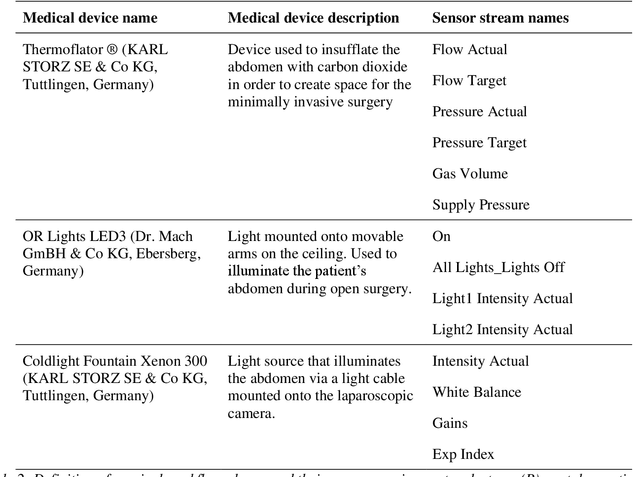
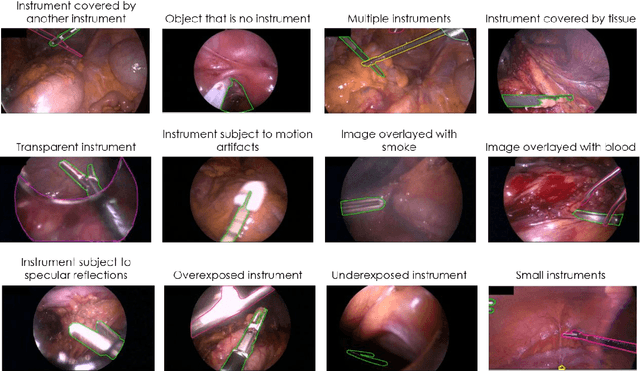
Image-based tracking of medical instruments is an integral part of many surgical data science applications. Previous research has addressed the tasks of detecting, segmenting and tracking medical instruments based on laparoscopic video data. However, the methods proposed still tend to fail when applied to challenging images and do not generalize well to data they have not been trained on. This paper introduces the Heidelberg Colorectal (HeiCo) data set - the first publicly available data set enabling comprehensive benchmarking of medical instrument detection and segmentation algorithms with a specific emphasis on robustness and generalization capabilities of the methods. Our data set comprises 30 laparoscopic videos and corresponding sensor data from medical devices in the operating room for three different types of laparoscopic surgery. Annotations include surgical phase labels for all frames in the videos as well as instance-wise segmentation masks for surgical instruments in more than 10,000 individual frames. The data has successfully been used to organize international competitions in the scope of the Endoscopic Vision Challenges (EndoVis) 2017 and 2019.
Robust Medical Instrument Segmentation Challenge 2019
Mar 23, 2020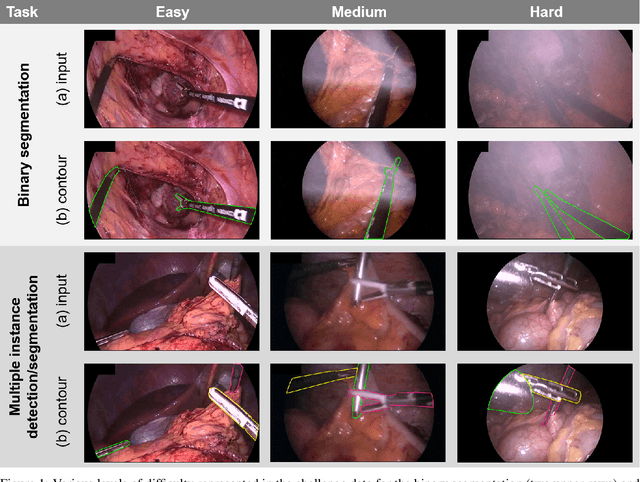
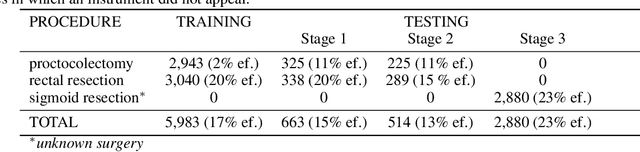
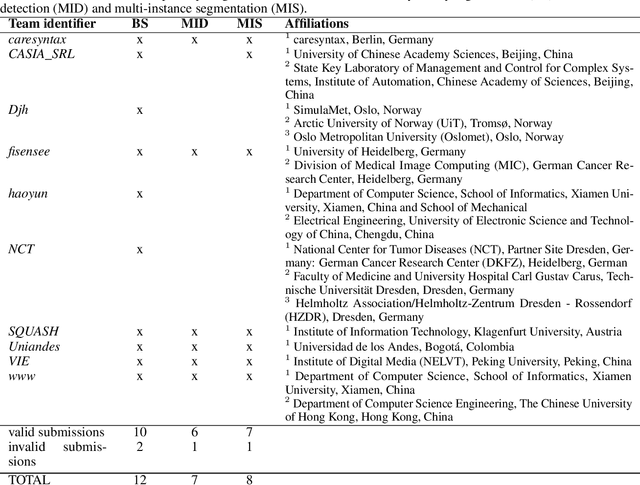
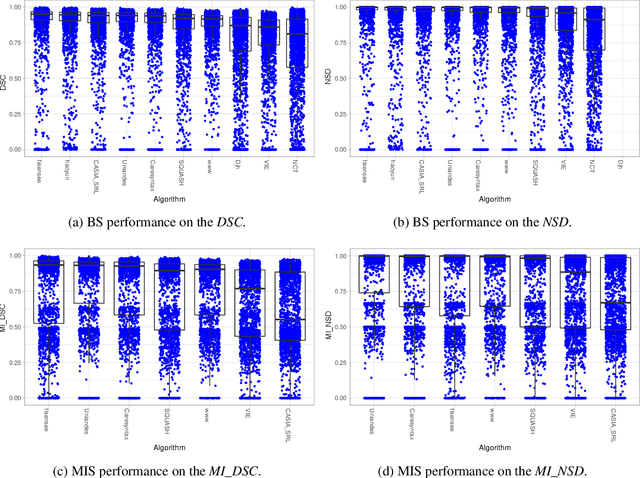
Intraoperative tracking of laparoscopic instruments is often a prerequisite for computer and robotic-assisted interventions. While numerous methods for detecting, segmenting and tracking of medical instruments based on endoscopic video images have been proposed in the literature, key limitations remain to be addressed: Firstly, robustness, that is, the reliable performance of state-of-the-art methods when run on challenging images (e.g. in the presence of blood, smoke or motion artifacts). Secondly, generalization; algorithms trained for a specific intervention in a specific hospital should generalize to other interventions or institutions. In an effort to promote solutions for these limitations, we organized the Robust Medical Instrument Segmentation (ROBUST-MIS) challenge as an international benchmarking competition with a specific focus on the robustness and generalization capabilities of algorithms. For the first time in the field of endoscopic image processing, our challenge included a task on binary segmentation and also addressed multi-instance detection and segmentation. The challenge was based on a surgical data set comprising 10,040 annotated images acquired from a total of 30 surgical procedures from three different types of surgery. The validation of the competing methods for the three tasks (binary segmentation, multi-instance detection and multi-instance segmentation) was performed in three different stages with an increasing domain gap between the training and the test data. The results confirm the initial hypothesis, namely that algorithm performance degrades with an increasing domain gap. While the average detection and segmentation quality of the best-performing algorithms is high, future research should concentrate on detection and segmentation of small, crossing, moving and transparent instrument(s) (parts).
Exploiting the potential of unlabeled endoscopic video data with self-supervised learning
Jan 31, 2018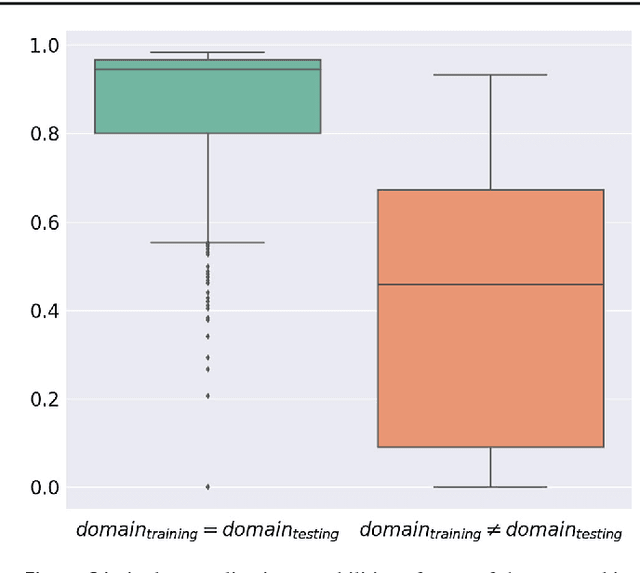
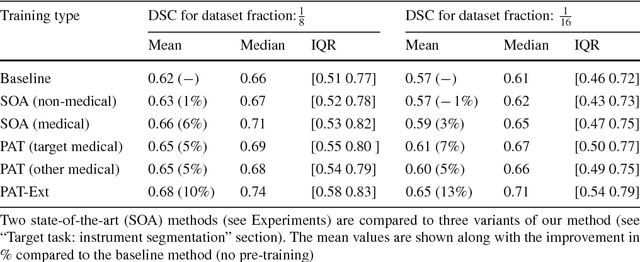
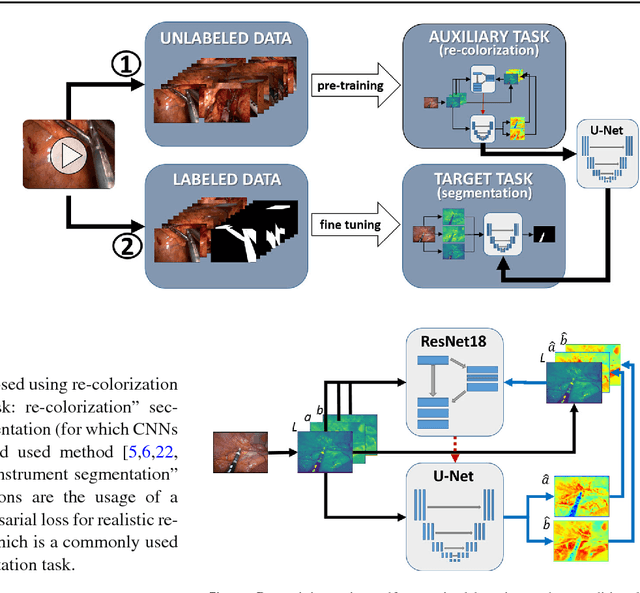
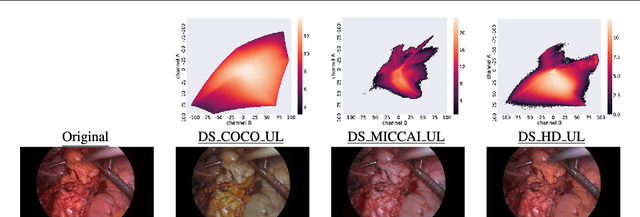
Surgical data science is a new research field that aims to observe all aspects of the patient treatment process in order to provide the right assistance at the right time. Due to the breakthrough successes of deep learning-based solutions for automatic image annotation, the availability of reference annotations for algorithm training is becoming a major bottleneck in the field. The purpose of this paper was to investigate the concept of self-supervised learning to address this issue. Our approach is guided by the hypothesis that unlabeled video data can be used to learn a representation of the target domain that boosts the performance of state-of-the-art machine learning algorithms when used for pre-training. Core of the method is an auxiliary task based on raw endoscopic video data of the target domain that is used to initialize the convolutional neural network (CNN) for the target task. In this paper, we propose the re-colorization of medical images with a generative adversarial network (GAN)-based architecture as auxiliary task. A variant of the method involves a second pre-training step based on labeled data for the target task from a related domain. We validate both variants using medical instrument segmentation as target task. The proposed approach can be used to radically reduce the manual annotation effort involved in training CNNs. Compared to the baseline approach of generating annotated data from scratch, our method decreases exploratively the number of labeled images by up to 75% without sacrificing performance. Our method also outperforms alternative methods for CNN pre-training, such as pre-training on publicly available non-medical or medical data using the target task (in this instance: segmentation). As it makes efficient use of available (non-)public and (un-)labeled data, the approach has the potential to become a valuable tool for CNN (pre-)training.
Clickstream analysis for crowd-based object segmentation with confidence
Nov 29, 2017
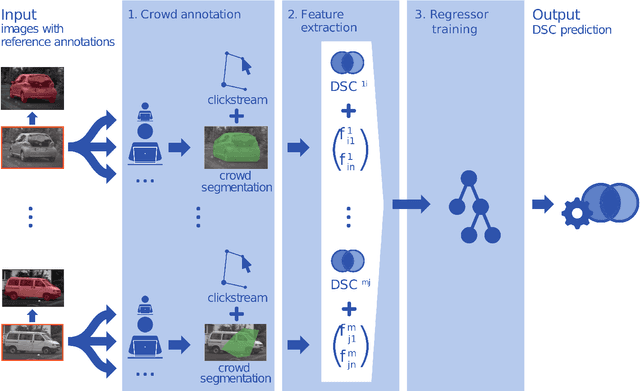
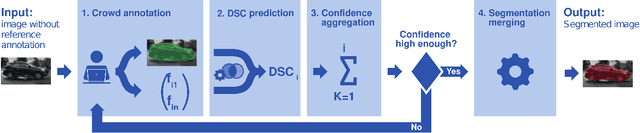
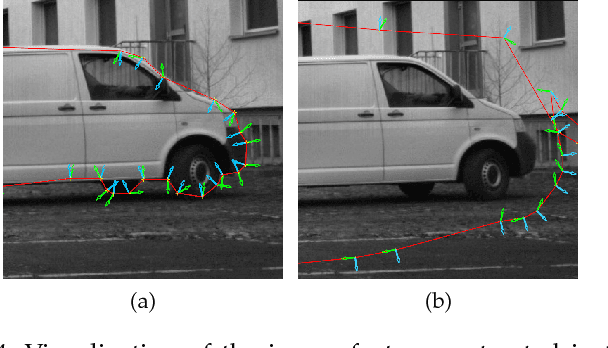
With the rapidly increasing interest in machine learning based solutions for automatic image annotation, the availability of reference annotations for algorithm training is one of the major bottlenecks in the field. Crowdsourcing has evolved as a valuable option for low-cost and large-scale data annotation; however, quality control remains a major issue which needs to be addressed. To our knowledge, we are the first to analyze the annotation process to improve crowd-sourced image segmentation. Our method involves training a regressor to estimate the quality of a segmentation from the annotator's clickstream data. The quality estimation can be used to identify spam and weight individual annotations by their (estimated) quality when merging multiple segmentations of one image. Using a total of 29,000 crowd annotations performed on publicly available data of different object classes, we show that (1) our method is highly accurate in estimating the segmentation quality based on clickstream data, (2) outperforms state-of-the-art methods for merging multiple annotations. As the regressor does not need to be trained on the object class that it is applied to it can be regarded as a low-cost option for quality control and confidence analysis in the context of crowd-based image annotation.