 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical Imaging AI Competitions Lack Fairness
Dec 19, 2025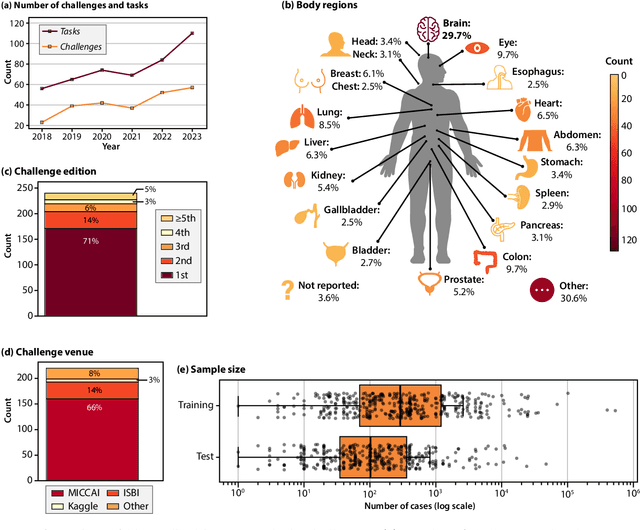
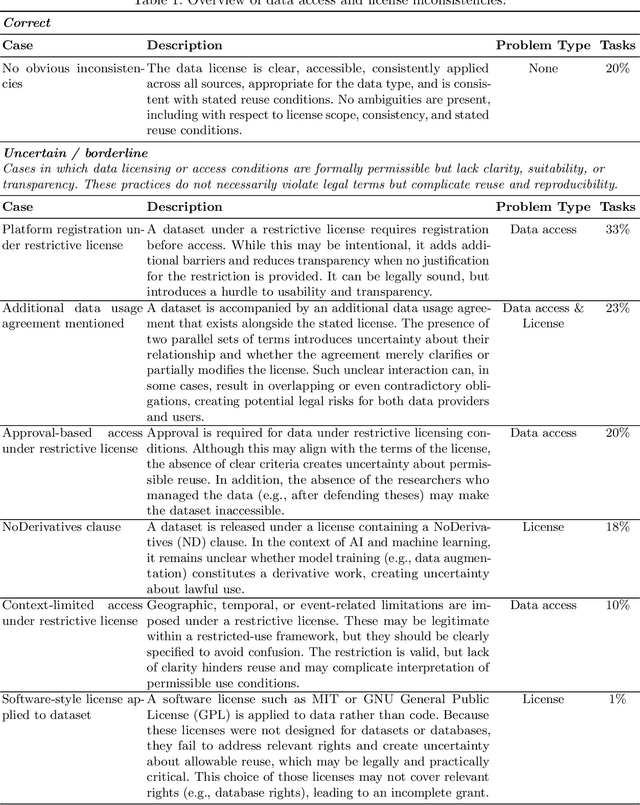
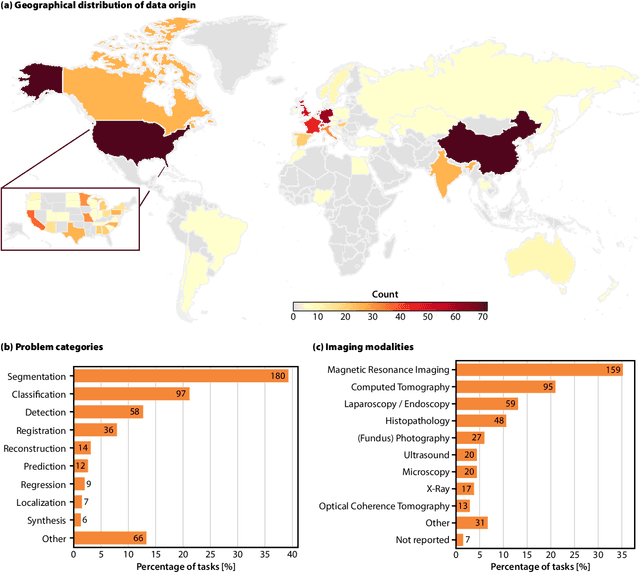
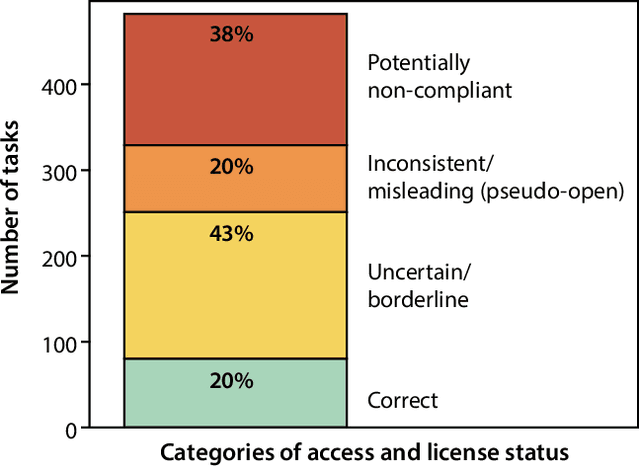
Benchmarking competitions are central to the development of artificial intelligence (AI) in medical imaging, defining performance standards and shaping methodological progress. However, it remains unclear whether these benchmarks provide data that are sufficiently representative, accessible, and reusable to support clinically meaningful AI. In this work, we assess fairness along two complementary dimensions: (1) whether challenge datasets are representative of real-world clinical diversity, and (2) whether they are accessible and legally reusable in line with the FAIR principles. To address this question, we conducted a large-scale systematic study of 241 biomedical image analysis challenges comprising 458 tasks across 19 imaging modalities. Our findings show substantial biases in dataset composition, including geographic location, modality-, and problem type-related biases, indicating that current benchmarks do not adequately reflect real-world clinical diversity. Despite their widespread influence, challenge datasets were frequently constrained by restrictive or ambiguous access conditions, inconsistent or non-compliant licensing practices, and incomplete documentation, limiting reproducibility and long-term reuse. Together, these shortcomings expose foundational fairness limitations in our benchmarking ecosystem and highlight a disconnect between leaderboard success and clinical relevance.
Unsupervised Domain Transfer with Conditional Invertible Neural Networks
Mar 17, 2023Synthetic medical image generation has evolved as a key technique for neural network training and validation. A core challenge, however, remains in the domain gap between simulations and real data. While deep learning-based domain transfer using Cycle Generative Adversarial Networks and similar architectures has led to substantial progress in the field, there are use cases in which state-of-the-art approaches still fail to generate training images that produce convincing results on relevant downstream tasks. Here, we address this issue with a domain transfer approach based on conditional invertible neural networks (cINNs). As a particular advantage, our method inherently guarantees cycle consistency through its invertible architecture, and network training can efficiently be conducted with maximum likelihood training. To showcase our method's generic applicability, we apply it to two spectral imaging modalities at different scales, namely hyperspectral imaging (pixel-level) and photoacoustic tomography (image-level). According to comprehensive experiments, our method enables the generation of realistic spectral data and outperforms the state of the art on two downstream classification tasks (binary and multi-class). cINN-based domain transfer could thus evolve as an important method for realistic synthetic data generation in the field of spectral imaging and beyond.
Semantic segmentation of multispectral photoacoustic images using deep learning
May 20, 2021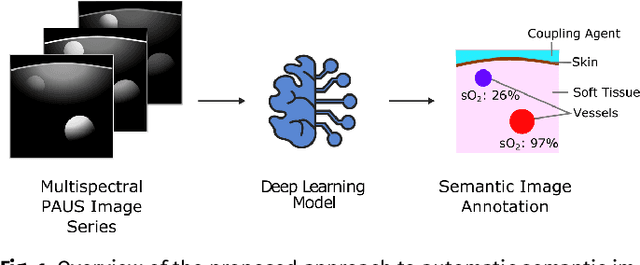

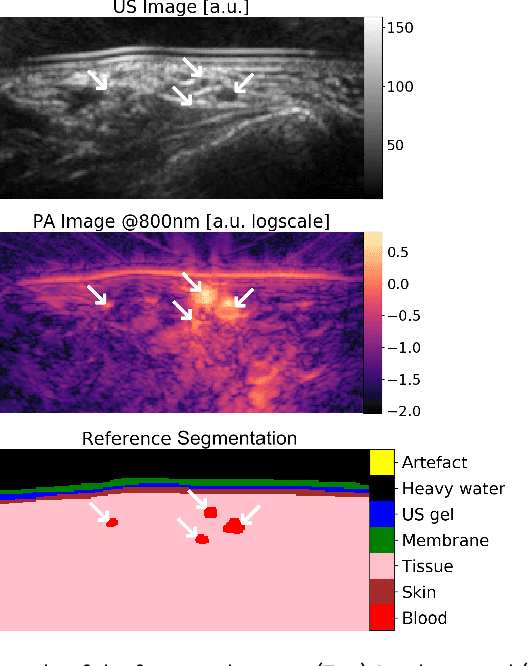
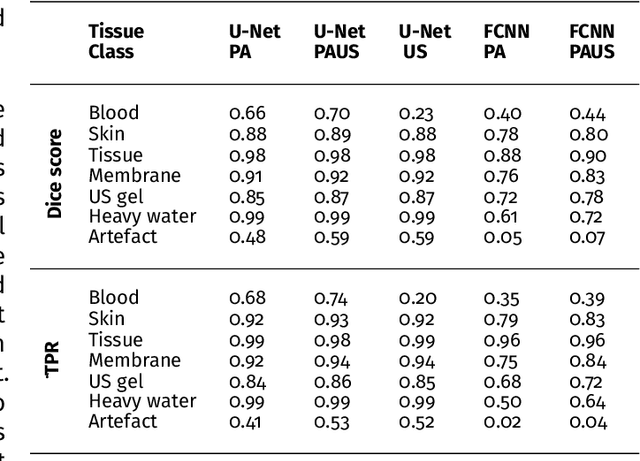
Photoacoustic imaging has the potential to revolutionise healthcare due to the valuable information on tissue physiology that is contained in multispectral photoacoustic measurements. Clinical translation of the technology requires conversion of the high-dimensional acquired data into clinically relevant and interpretable information. In this work, we present a deep learning-based approach to semantic segmentation of multispectral photoacoustic images to facilitate the interpretability of recorded images. Manually annotated multispectral photoacoustic imaging data are used as gold standard reference annotations and enable the training of a deep learning-based segmentation algorithm in a supervised manner. Based on a validation study with experimentally acquired data of healthy human volunteers, we show that automatic tissue segmentation can be used to create powerful analyses and visualisations of multispectral photoacoustic images. Due to the intuitive representation of high-dimensional information, such a processing algorithm could be a valuable means to facilitate the clinical translation of photoacoustic imaging.
Data-driven generation of plausible tissue geometries for realistic photoacoustic image synthesis
Mar 29, 2021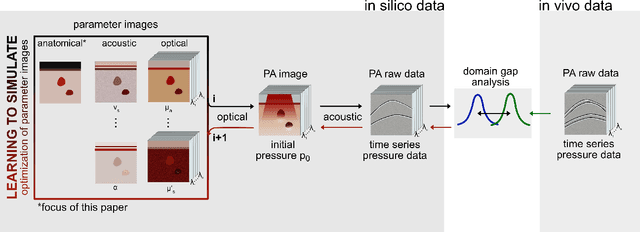

Photoacoustic tomography (PAT) has the potential to recover morphological and functional tissue properties such as blood oxygenation with high spatial resolution and in an interventional setting. However, decades of research invested in solving the inverse problem of recovering clinically relevant tissue properties from spectral measurements have failed to produce solutions that can quantify tissue parameters robustly in a clinical setting. Previous attempts to address the limitations of model-based approaches with machine learning were hampered by the absence of labeled reference data needed for supervised algorithm training. While this bottleneck has been tackled by simulating training data, the domain gap between real and simulated images remains a huge unsolved challenge. As a first step to address this bottleneck, we propose a novel approach to PAT data simulation, which we refer to as "learning to simulate". Our approach involves subdividing the challenge of generating plausible simulations into two disjoint problems: (1) Probabilistic generation of realistic tissue morphology, represented by semantic segmentation maps and (2) pixel-wise assignment of corresponding optical and acoustic properties. In the present work, we focus on the first challenge. Specifically, we leverage the concept of Generative Adversarial Networks (GANs) trained on semantically annotated medical imaging data to generate plausible tissue geometries. According to an initial in silico feasibility study our approach is well-suited for contributing to realistic PAT image synthesis and could thus become a fundamental step for deep learning-based quantitative PAT.
Tattoo tomography: Freehand 3D photoacoustic image reconstruction with an optical pattern
Nov 11, 2020


Purpose: Photoacoustic tomography (PAT) is a novel imaging technique that can spatially resolve both morphological and functional tissue properties, such as the vessel topology and tissue oxygenation. While this capacity makes PAT a promising modality for the diagnosis, treatment and follow-up of various diseases, a current drawback is the limited field-of-view (FoV) provided by the conventionally applied 2D probes. Methods: In this paper, we present a novel approach to 3D reconstruction of PAT data (Tattoo tomography) that does not require an external tracking system and can smoothly be integrated into clinical workflows. It is based on an optical pattern placed on the region of interest prior to image acquisition. This pattern is designed in a way that a tomographic image of it enables the recovery of the probe pose relative to the coordinate system of the pattern. This allows the transformation of a sequence of acquired PA images into one common global coordinate system and thus the consistent 3D reconstruction of PAT imaging data. Results: An initial feasibility study conducted with experimental phantom data and in vivo forearm data indicates that the Tattoo approach is well-suited for 3D reconstruction of PAT data with high accuracy and precision. Conclusion: In contrast to previous approaches to 3D ultrasound (US) or PAT reconstruction, the Tattoo approach neither requires complex external hardware nor training data acquired for a specific application. It could thus become a valuable tool for clinical freehand PAT.
Clickstream analysis for crowd-based object segmentation with confidence
Nov 29, 2017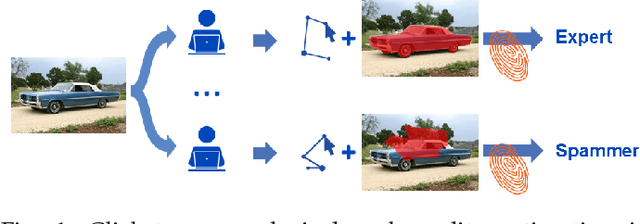
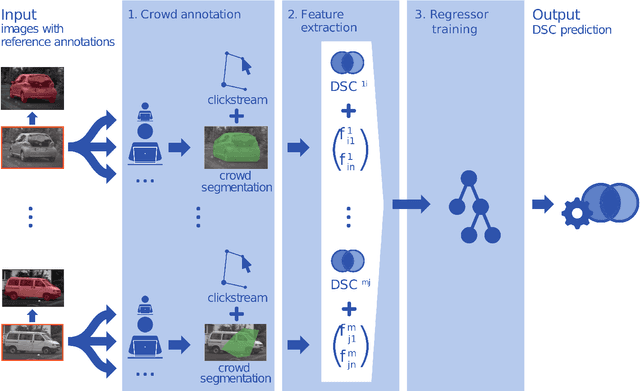
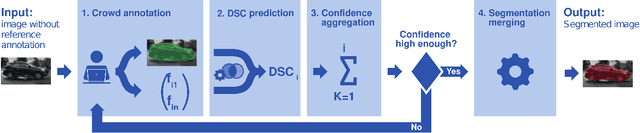
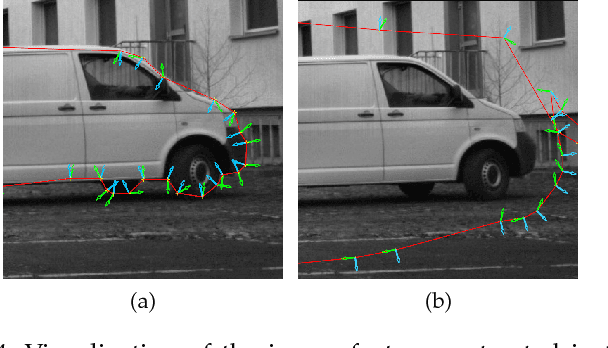
With the rapidly increasing interest in machine learning based solutions for automatic image annotation, the availability of reference annotations for algorithm training is one of the major bottlenecks in the field. Crowdsourcing has evolved as a valuable option for low-cost and large-scale data annotation; however, quality control remains a major issue which needs to be addressed. To our knowledge, we are the first to analyze the annotation process to improve crowd-sourced image segmentation. Our method involves training a regressor to estimate the quality of a segmentation from the annotator's clickstream data. The quality estimation can be used to identify spam and weight individual annotations by their (estimated) quality when merging multiple segmentations of one image. Using a total of 29,000 crowd annotations performed on publicly available data of different object classes, we show that (1) our method is highly accurate in estimating the segmentation quality based on clickstream data, (2) outperforms state-of-the-art methods for merging multiple annotations. As the regressor does not need to be trained on the object class that it is applied to it can be regarded as a low-cost option for quality control and confidence analysis in the context of crowd-based image annotation.