 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Decision-driven Methodology for Designing Uncertainty-aware AI Self-Assessment
Aug 02, 2024Artificial intelligence (AI) has revolutionized decision-making processes and systems throughout society and, in particular, has emerged as a significant technology in high-impact scenarios of national interest. Yet, despite AI's impressive predictive capabilities in controlled settings, it still suffers from a range of practical setbacks preventing its widespread use in various critical scenarios. In particular, it is generally unclear if a given AI system's predictions can be trusted by decision-makers in downstream applications. To address the need for more transparent, robust, and trustworthy AI systems, a suite of tools has been developed to quantify the uncertainty of AI predictions and, more generally, enable AI to "self-assess" the reliability of its predictions. In this manuscript, we categorize methods for AI self-assessment along several key dimensions and provide guidelines for selecting and designing the appropriate method for a practitioner's needs. In particular, we focus on uncertainty estimation techniques that consider the impact of self-assessment on the choices made by downstream decision-makers and on the resulting costs and benefits of decision outcomes. To demonstrate the utility of our methodology for self-assessment design, we illustrate its use for two realistic national-interest scenarios. This manuscript is a practical guide for machine learning engineers and AI system users to select the ideal self-assessment techniques for each problem.
What is Your Metric Telling You? Evaluating Classifier Calibration under Context-Specific Definitions of Reliability
May 23, 2022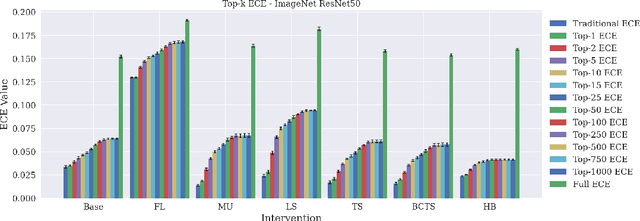
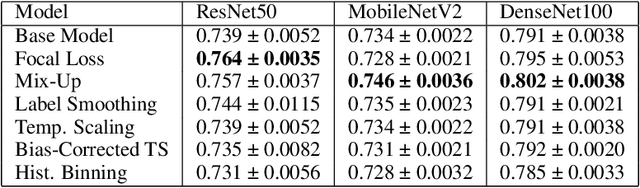
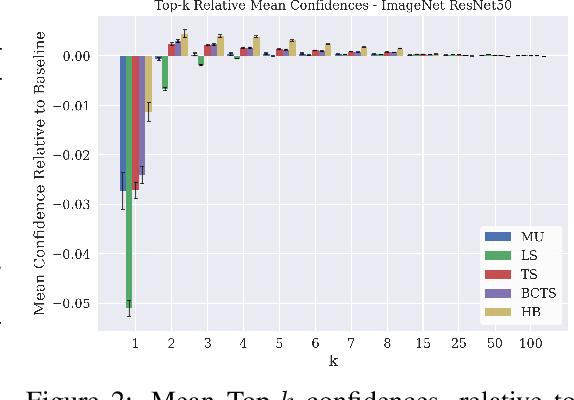
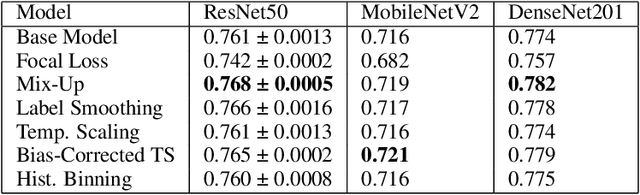
Classifier calibration has received recent attention from the machine learning community due both to its practical utility in facilitating decision making, as well as the observation that modern neural network classifiers are poorly calibrated. Much of this focus has been towards the goal of learning classifiers such that their output with largest magnitude (the "predicted class") is calibrated. However, this narrow interpretation of classifier outputs does not adequately capture the variety of practical use cases in which classifiers can aid in decision making. In this work, we argue that more expressive metrics must be developed that accurately measure calibration error for the specific context in which a classifier will be deployed. To this end, we derive a number of different metrics using a generalization of Expected Calibration Error (ECE) that measure calibration error under different definitions of reliability. We then provide an extensive empirical evaluation of commonly used neural network architectures and calibration techniques with respect to these metrics. We find that: 1) definitions of ECE that focus solely on the predicted class fail to accurately measure calibration error under a selection of practically useful definitions of reliability and 2) many common calibration techniques fail to improve calibration performance uniformly across ECE metrics derived from these diverse definitions of reliability.
Measuring AI Systems Beyond Accuracy
Apr 07, 2022Current test and evaluation (T&E) methods for assessing machine learning (ML) system performance often rely on incomplete metrics. Testing is additionally often siloed from the other phases of the ML system lifecycle. Research investigating cross-domain approaches to ML T&E is needed to drive the state of the art forward and to build an Artificial Intelligence (AI) engineering discipline. This paper advocates for a robust, integrated approach to testing by outlining six key questions for guiding a holistic T&E strategy.
Factor Analysis on Citation, Using a Combined Latent and Logistic Regression Model
Dec 02, 2019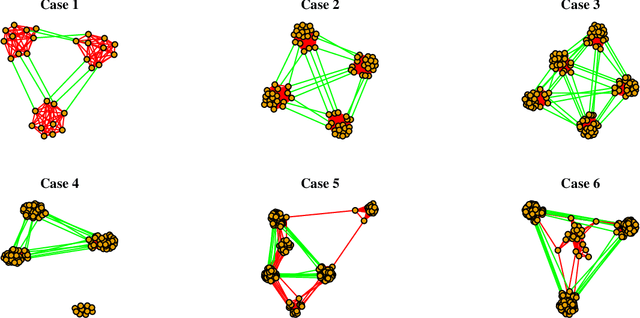
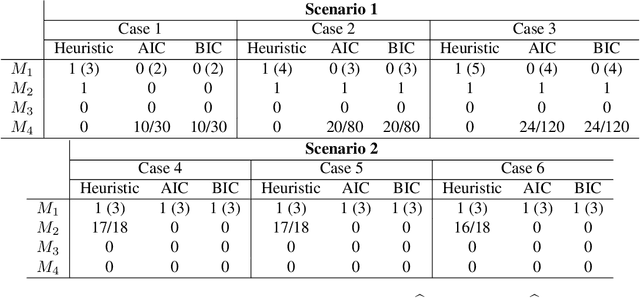
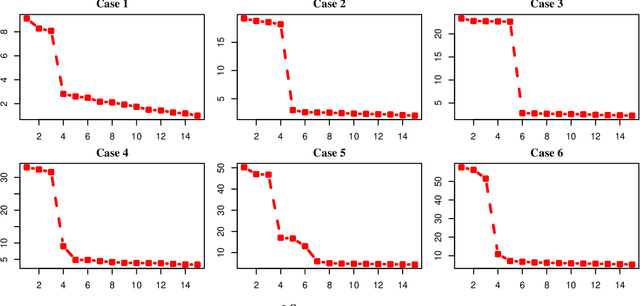
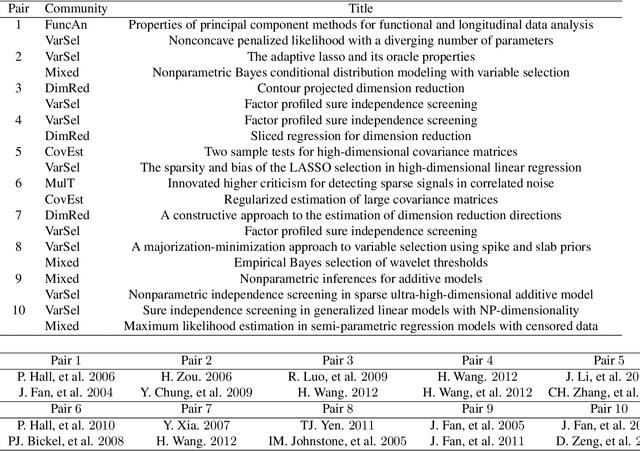
We propose a combined model, which integrates the latent factor model and the logistic regression model, for the citation network. It is noticed that neither a latent factor model nor a logistic regression model alone is sufficient to capture the structure of the data. The proposed model has a latent (i.e., factor analysis) model to represents the main technological trends (a.k.a., factors), and adds a sparse component that captures the remaining ad-hoc dependence. Parameter estimation is carried out through the construction of a joint-likelihood function of edges and properly chosen penalty terms. The convexity of the objective function allows us to develop an efficient algorithm, while the penalty terms push towards a low-dimensional latent component and a sparse graphical structure. Simulation results show that the proposed method works well in practical situations. The proposed method has been applied to a real application, which contains a citation network of statisticians (Ji and Jin, 2016). Some interesting findings are reported.
xBD: A Dataset for Assessing Building Damage from Satellite Imagery
Nov 21, 2019
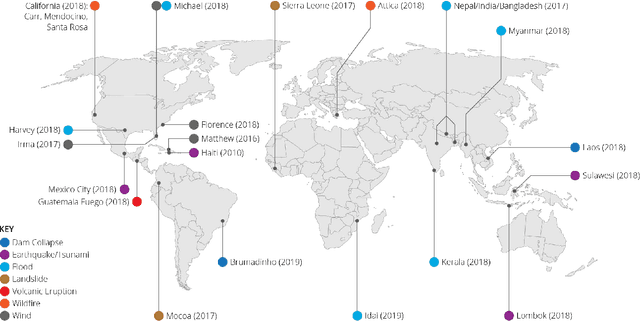
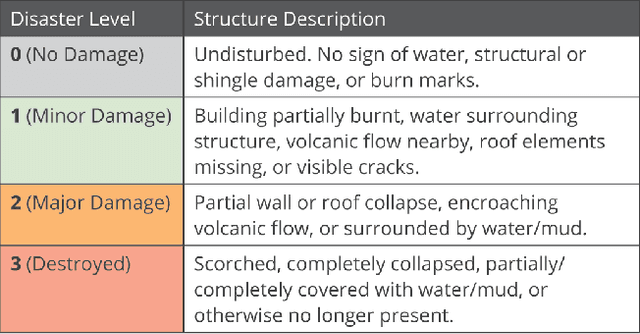

We present xBD, a new, large-scale dataset for the advancement of change detection and building damage assessment for humanitarian assistance and disaster recovery research. Natural disaster response requires an accurate understanding of damaged buildings in an affected region. Current response strategies require in-person damage assessments within 24-48 hours of a disaster. Massive potential exists for using aerial imagery combined with computer vision algorithms to assess damage and reduce the potential danger to human life. In collaboration with multiple disaster response agencies, xBD provides pre- and post-event satellite imagery across a variety of disaster events with building polygons, ordinal labels of damage level, and corresponding satellite metadata. Furthermore, the dataset contains bounding boxes and labels for environmental factors such as fire, water, and smoke. xBD is the largest building damage assessment dataset to date, containing 850,736 building annotations across 45,362 km\textsuperscript{2} of imagery.
Constrained Generative Adversarial Networks for Interactive Image Generation
Apr 03, 2019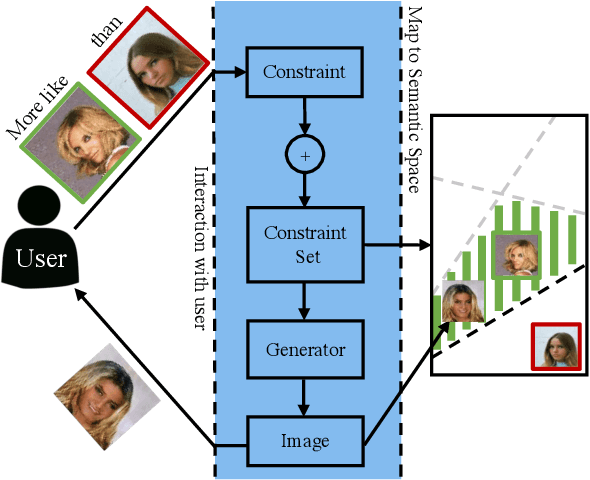


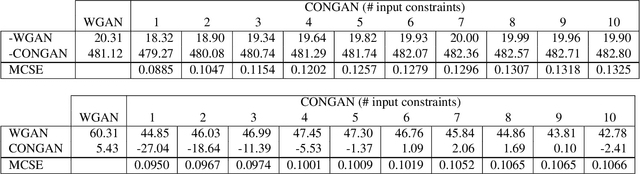
Generative Adversarial Networks (GANs) have received a great deal of attention due in part to recent success in generating original, high-quality samples from visual domains. However, most current methods only allow for users to guide this image generation process through limited interactions. In this work we develop a novel GAN framework that allows humans to be "in-the-loop" of the image generation process. Our technique iteratively accepts relative constraints of the form "Generate an image more like image A than image B". After each constraint is given, the user is presented with new outputs from the GAN, informing the next round of feedback. This feedback is used to constrain the output of the GAN with respect to an underlying semantic space that can be designed to model a variety of different notions of similarity (e.g. classes, attributes, object relationships, color, etc.). In our experiments, we show that our GAN framework is able to generate images that are of comparable quality to equivalent unsupervised GANs while satisfying a large number of the constraints provided by users, effectively changing a GAN into one that allows users interactive control over image generation without sacrificing image quality.
Exploiting Class Learnability in Noisy Data
Nov 15, 2018
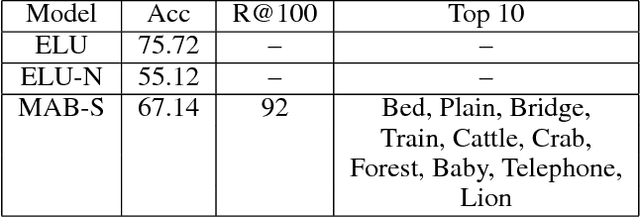
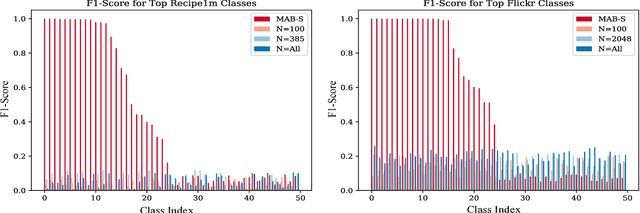

In many domains, collecting sufficient labeled training data for supervised machine learning requires easily accessible but noisy sources, such as crowdsourcing services or tagged Web data. Noisy labels occur frequently in data sets harvested via these means, sometimes resulting in entire classes of data on which learned classifiers generalize poorly. For real world applications, we argue that it can be beneficial to avoid training on such classes entirely. In this work, we aim to explore the classes in a given data set, and guide supervised training to spend time on a class proportional to its learnability. By focusing the training process, we aim to improve model generalization on classes with a strong signal. To that end, we develop an online algorithm that works in conjunction with classifier and training algorithm, iteratively selecting training data for the classifier based on how well it appears to generalize on each class. Testing our approach on a variety of data sets, we show our algorithm learns to focus on classes for which the model has low generalization error relative to strong baselines, yielding a classifier with good performance on learnable classes.
Generating Triples with Adversarial Networks for Scene Graph Construction
Feb 07, 2018
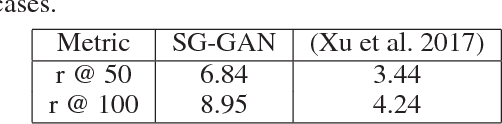
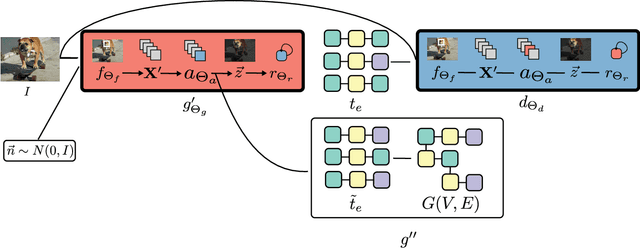

Driven by successes in deep learning, computer vision research has begun to move beyond object detection and image classification to more sophisticated tasks like image captioning or visual question answering. Motivating such endeavors is the desire for models to capture not only objects present in an image, but more fine-grained aspects of a scene such as relationships between objects and their attributes. Scene graphs provide a formal construct for capturing these aspects of an image. Despite this, there have been only a few recent efforts to generate scene graphs from imagery. Previous works limit themselves to settings where bounding box information is available at train time and do not attempt to generate scene graphs with attributes. In this paper we propose a method, based on recent advancements in Generative Adversarial Networks, to overcome these deficiencies. We take the approach of first generating small subgraphs, each describing a single statement about a scene from a specific region of the input image chosen using an attention mechanism. By doing so, our method is able to produce portions of the scene graphs with attribute information without the need for bounding box labels. Then, the complete scene graph is constructed from these subgraphs. We show that our model improves upon prior work in scene graph generation on state-of-the-art data sets and accepted metrics. Further, we demonstrate that our model is capable of handling a larger vocabulary size than prior work has attempted.
Clickstream analysis for crowd-based object segmentation with confidence
Nov 29, 2017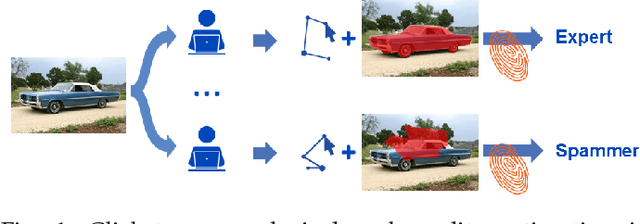
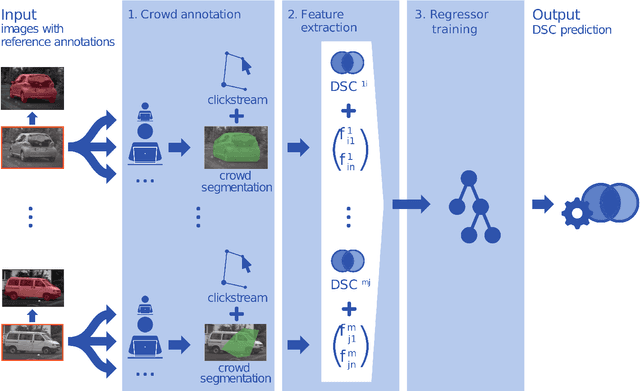
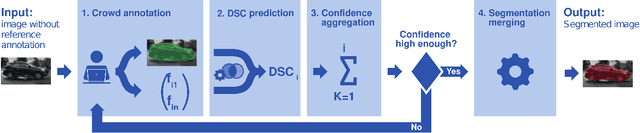
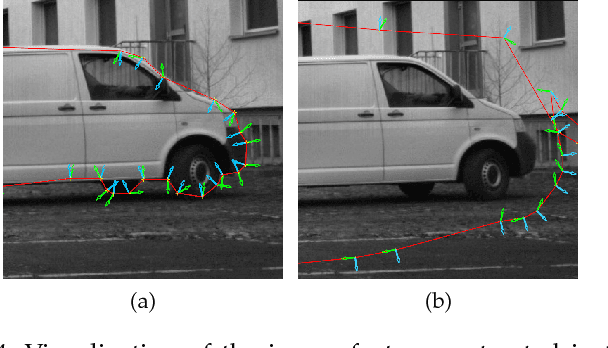
With the rapidly increasing interest in machine learning based solutions for automatic image annotation, the availability of reference annotations for algorithm training is one of the major bottlenecks in the field. Crowdsourcing has evolved as a valuable option for low-cost and large-scale data annotation; however, quality control remains a major issue which needs to be addressed. To our knowledge, we are the first to analyze the annotation process to improve crowd-sourced image segmentation. Our method involves training a regressor to estimate the quality of a segmentation from the annotator's clickstream data. The quality estimation can be used to identify spam and weight individual annotations by their (estimated) quality when merging multiple segmentations of one image. Using a total of 29,000 crowd annotations performed on publicly available data of different object classes, we show that (1) our method is highly accurate in estimating the segmentation quality based on clickstream data, (2) outperforms state-of-the-art methods for merging multiple annotations. As the regressor does not need to be trained on the object class that it is applied to it can be regarded as a low-cost option for quality control and confidence analysis in the context of crowd-based image annotation.
Active Perceptual Similarity Modeling with Auxiliary Information
Nov 06, 2015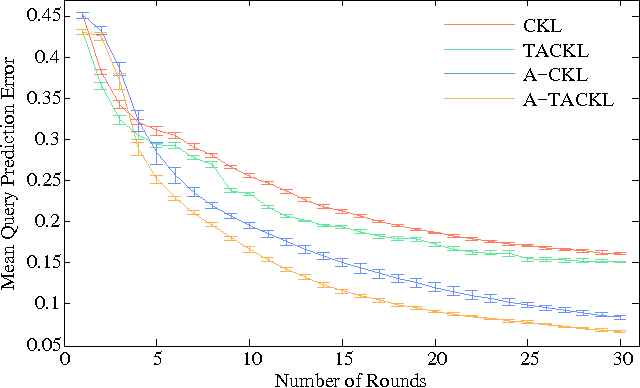
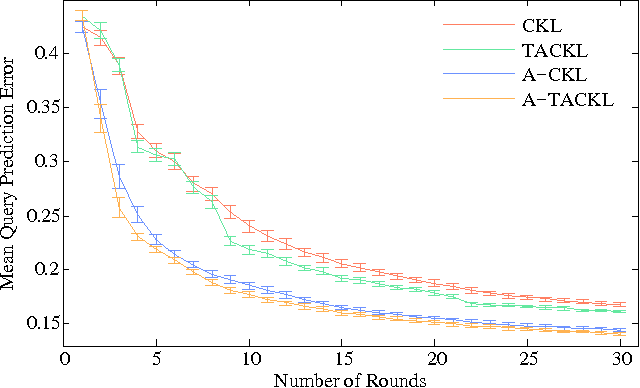
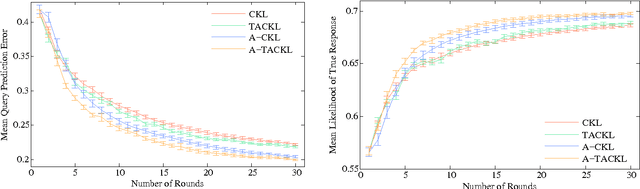

Learning a model of perceptual similarity from a collection of objects is a fundamental task in machine learning underlying numerous applications. A common way to learn such a model is from relative comparisons in the form of triplets: responses to queries of the form "Is object a more similar to b than it is to c?". If no consideration is made in the determination of which queries to ask, existing similarity learning methods can require a prohibitively large number of responses. In this work, we consider the problem of actively learning from triplets -finding which queries are most useful for learning. Different from previous active triplet learning approaches, we incorporate auxiliary information into our similarity model and introduce an active learning scheme to find queries that are informative for quickly learning both the relevant aspects of auxiliary data and the directly-learned similarity components. Compared to prior approaches, we show that we can learn just as effectively with much fewer queries. For evaluation, we introduce a new dataset of exhaustive triplet comparisons obtained from humans and demonstrate improved performance for different types of auxiliary information.