 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring AI Systems Beyond Accuracy
Apr 07, 2022Current test and evaluation (T&E) methods for assessing machine learning (ML) system performance often rely on incomplete metrics. Testing is additionally often siloed from the other phases of the ML system lifecycle. Research investigating cross-domain approaches to ML T&E is needed to drive the state of the art forward and to build an Artificial Intelligence (AI) engineering discipline. This paper advocates for a robust, integrated approach to testing by outlining six key questions for guiding a holistic T&E strategy.
On managing vulnerabilities in AI/ML systems
Jan 22, 2021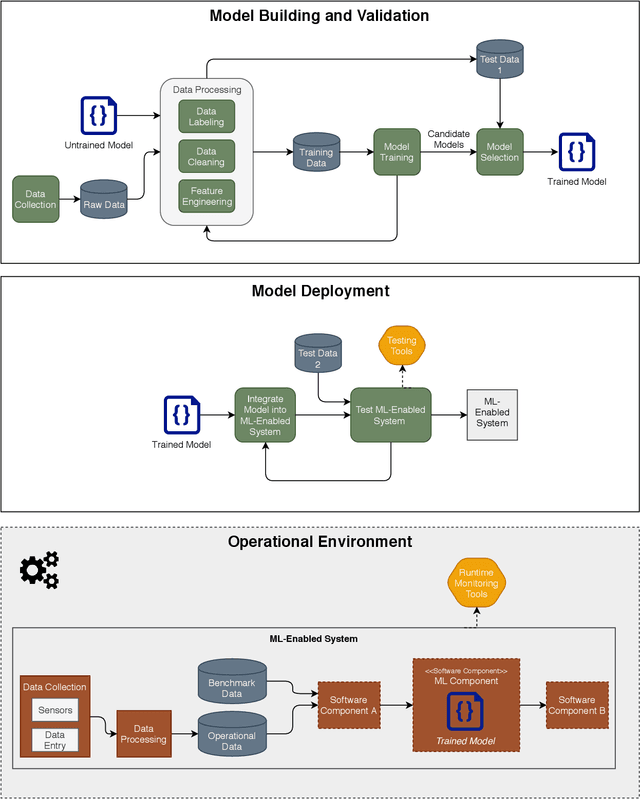
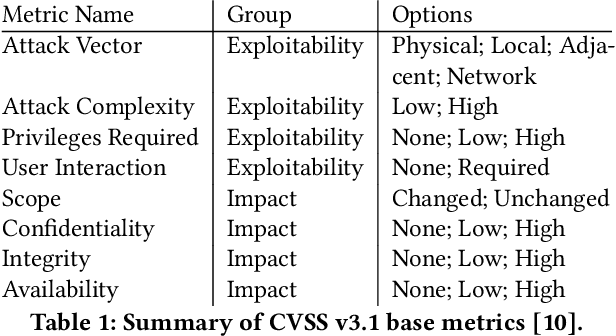
This paper explores how the current paradigm of vulnerability management might adapt to include machine learning systems through a thought experiment: what if flaws in machine learning (ML) were assigned Common Vulnerabilities and Exposures (CVE) identifiers (CVE-IDs)? We consider both ML algorithms and model objects. The hypothetical scenario is structured around exploring the changes to the six areas of vulnerability management: discovery, report intake, analysis, coordination, disclosure, and response. While algorithm flaws are well-known in the academic research community, there is no apparent clear line of communication between this research community and the operational communities that deploy and manage systems that use ML. The thought experiments identify some ways in which CVE-IDs may establish some useful lines of communication between these two communities. In particular, it would start to introduce the research community to operational security concepts, which appears to be a gap left by existing efforts.
On the human-recognizability phenomenon of adversarially trained deep image classifiers
Dec 18, 2020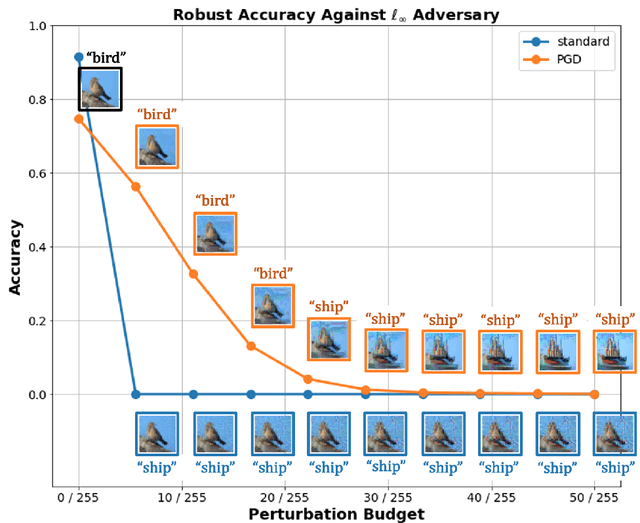
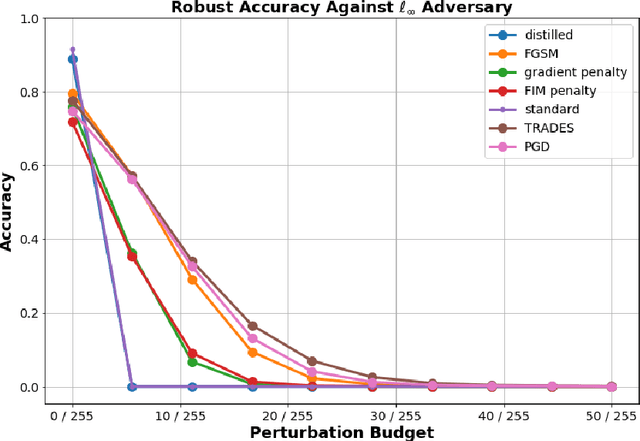

In this work, we investigate the phenomenon that robust image classifiers have human-recognizable features -- often referred to as interpretability -- as revealed through the input gradients of their score functions and their subsequent adversarial perturbations. In particular, we demonstrate that state-of-the-art methods for adversarial training incorporate two terms -- one that orients the decision boundary via minimizing the expected loss, and another that induces smoothness of the classifier's decision surface by penalizing the local Lipschitz constant. Through this demonstration, we provide a unified discussion of gradient and Jacobian-based regularizers that have been used to encourage adversarial robustness in prior works. Following this discussion, we give qualitative evidence that the coupling of smoothness and orientation of the decision boundary is sufficient to induce the aforementioned human-recognizability phenomenon.