 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the human-recognizability phenomenon of adversarially trained deep image classifiers
Dec 18, 2020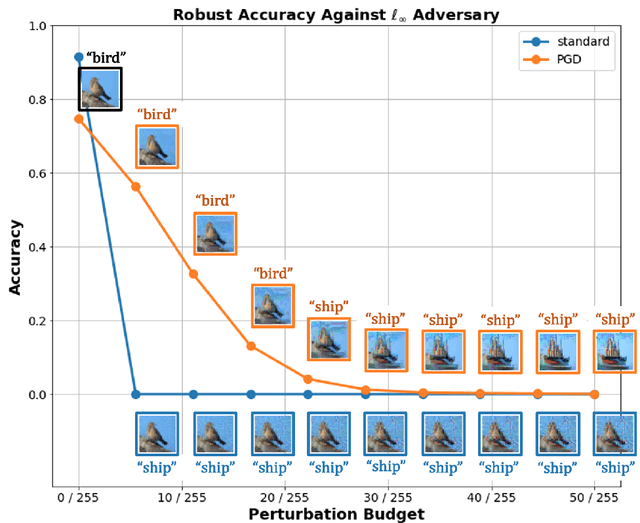
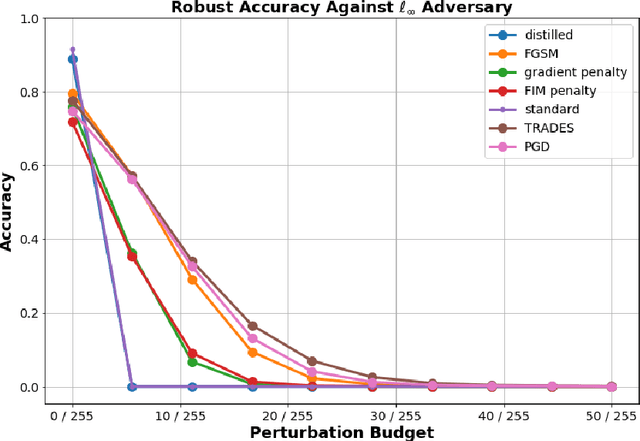

In this work, we investigate the phenomenon that robust image classifiers have human-recognizable features -- often referred to as interpretability -- as revealed through the input gradients of their score functions and their subsequent adversarial perturbations. In particular, we demonstrate that state-of-the-art methods for adversarial training incorporate two terms -- one that orients the decision boundary via minimizing the expected loss, and another that induces smoothness of the classifier's decision surface by penalizing the local Lipschitz constant. Through this demonstration, we provide a unified discussion of gradient and Jacobian-based regularizers that have been used to encourage adversarial robustness in prior works. Following this discussion, we give qualitative evidence that the coupling of smoothness and orientation of the decision boundary is sufficient to induce the aforementioned human-recognizability phenomenon.