 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn managing vulnerabilities in AI/ML systems
Jan 22, 2021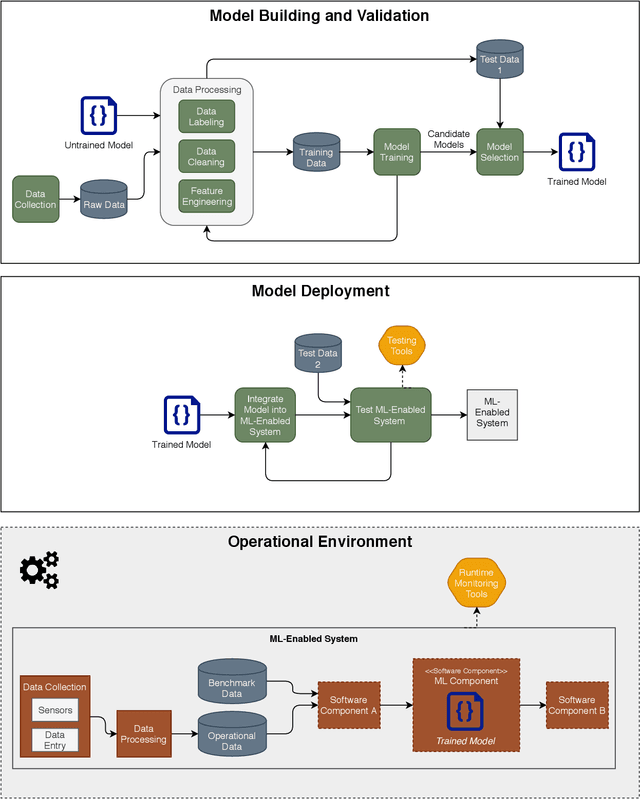
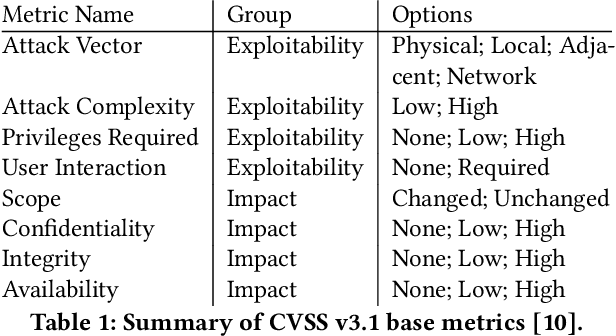
This paper explores how the current paradigm of vulnerability management might adapt to include machine learning systems through a thought experiment: what if flaws in machine learning (ML) were assigned Common Vulnerabilities and Exposures (CVE) identifiers (CVE-IDs)? We consider both ML algorithms and model objects. The hypothetical scenario is structured around exploring the changes to the six areas of vulnerability management: discovery, report intake, analysis, coordination, disclosure, and response. While algorithm flaws are well-known in the academic research community, there is no apparent clear line of communication between this research community and the operational communities that deploy and manage systems that use ML. The thought experiments identify some ways in which CVE-IDs may establish some useful lines of communication between these two communities. In particular, it would start to introduce the research community to operational security concepts, which appears to be a gap left by existing efforts.
Component Mismatches Are a Critical Bottleneck to Fielding AI-Enabled Systems in the Public Sector
Oct 14, 2019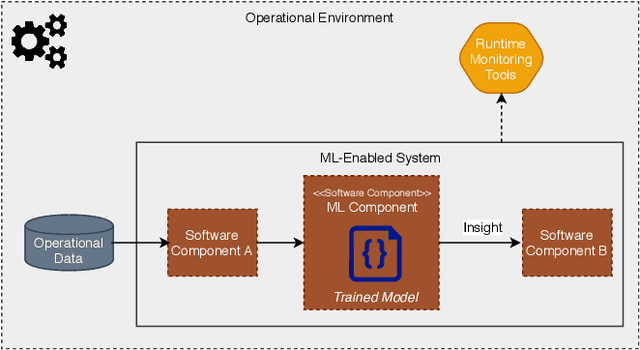
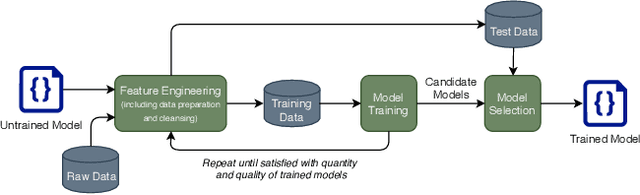
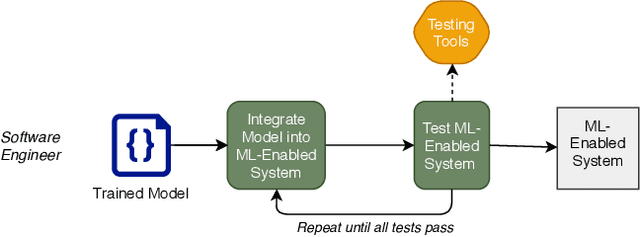
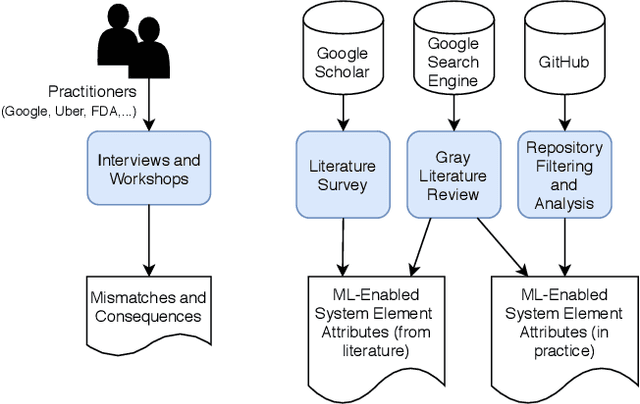
The use of machine learning or artificial intelligence (ML/AI) holds substantial potential toward improving many functions and needs of the public sector. In practice however, integrating ML/AI components into public sector applications is severely limited not only by the fragility of these components and their algorithms, but also because of mismatches between components of ML-enabled systems. For example, if an ML model is trained on data that is different from data in the operational environment, field performance of the ML component will be dramatically reduced. Separate from software engineering considerations, the expertise needed to field an ML/AI component within a system frequently comes from outside software engineering. As a result, assumptions and even descriptive language used by practitioners from these different disciplines can exacerbate other challenges to integrating ML/AI components into larger systems. We are investigating classes of mismatches in ML/AI systems integration, to identify the implicit assumptions made by practitioners in different fields (data scientists, software engineers, operations staff) and find ways to communicate the appropriate information explicitly. We will discuss a few categories of mismatch, and provide examples from each class. To enable ML/AI components to be fielded in a meaningful way, we will need to understand the mismatches that exist and develop practices to mitigate the impacts of these mismatches.
Automatic Identification of Ineffective Online Student Questions in Computing Education
Oct 07, 2018


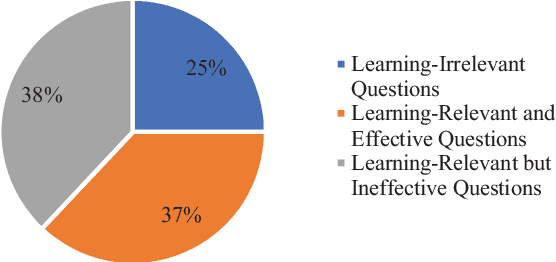
This Research Full Paper explores automatic identification of ineffective learning questions in the context of large-scale computer science classes. The immediate and accurate identification of ineffective learning questions opens the door to possible automated facilitation on a large scale, such as alerting learners to revise questions and providing adaptive question revision suggestions. To achieve this, 983 questions were collected from a question & answer platform implemented by an introductory programming course over three semesters in a large research university in the Southeastern United States. Questions were firstly manually classified into three hierarchical categories: 1) learning-irrelevant questions, 2) effective learning-relevant questions, 3) ineffective learningrelevant questions. The inter-rater reliability of the manual classification (Cohen's Kappa) was .88. Four different machine learning algorithms were then used to automatically classify the questions, including Naive Bayes Multinomial, Logistic Regression, Support Vector Machines, and Boosted Decision Tree. Both flat and single path strategies were explored, and the most effective algorithms under both strategies were identified and discussed. This study contributes to the automatic determination of learning question quality in computer science, and provides evidence for the feasibility of automated facilitation of online question & answer in large scale computer science classes.
Predicting Performance During Tutoring with Models of Recent Performance
Jan 12, 2015


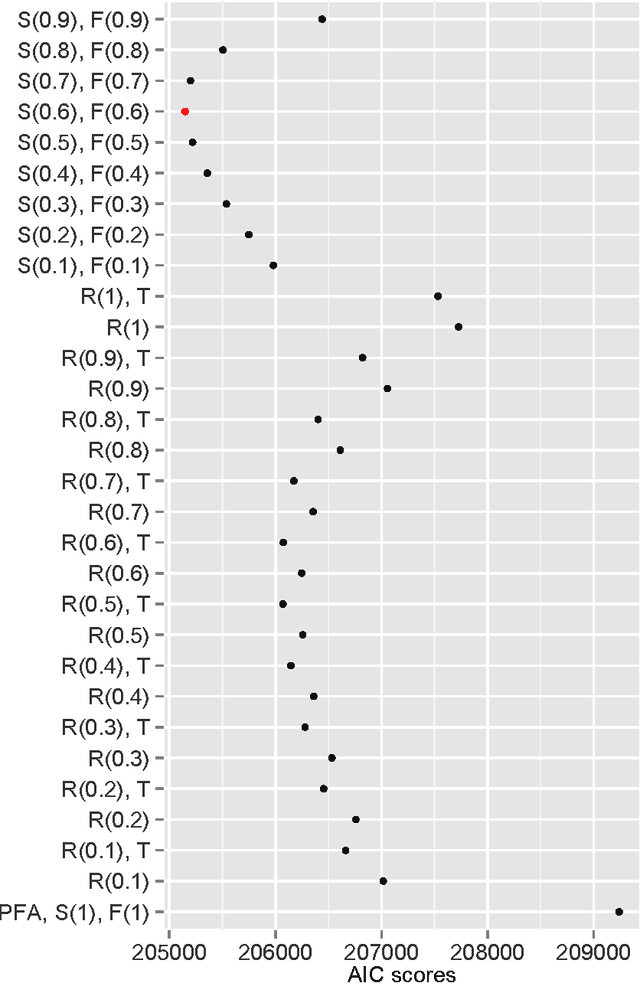
In educational technology and learning sciences, there are multiple uses for a predictive model of whether a student will perform a task correctly or not. For example, an intelligent tutoring system may use such a model to estimate whether or not a student has mastered a skill. We analyze the significance of data recency in making such predictions, i.e., asking whether relatively more recent observations of a student's performance matter more than relatively older observations. We develop a new Recent-Performance Factors Analysis model that takes data recency into account. The new model significantly improves predictive accuracy over both existing logistic-regression performance models and over novel baseline models in evaluations on real-world and synthetic datasets. As a secondary contribution, we demonstrate how the widely used cross-validation with 0-1 loss is inferior to AIC and to cross-validation with L1 prediction error loss as a measure of model performance.