 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing and Detecting Mismatch in Machine-Learning-Enabled Systems
Mar 25, 2021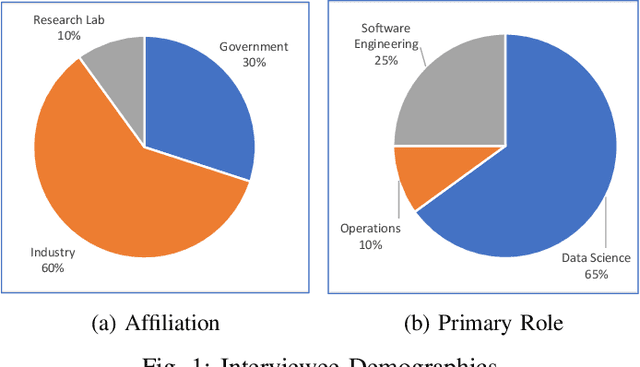
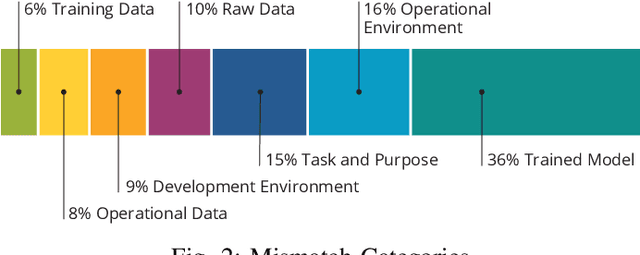
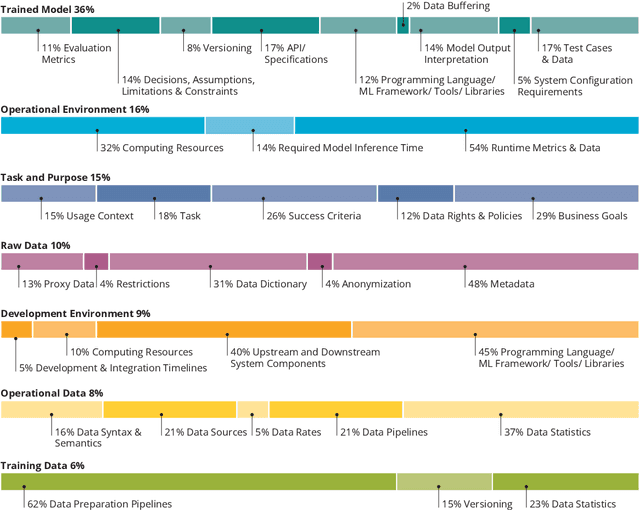
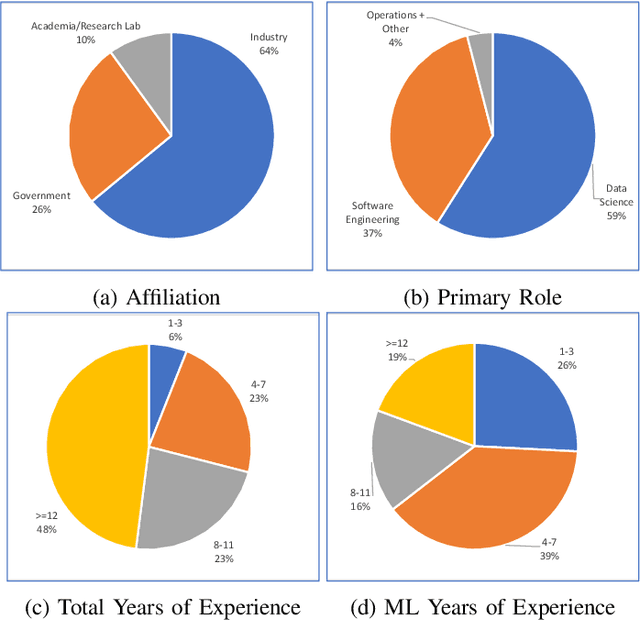
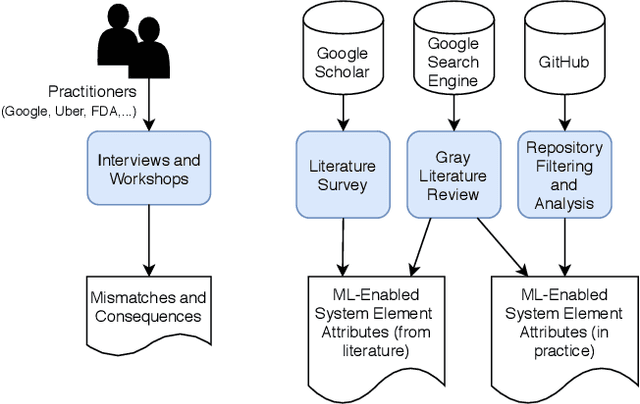
Increasing availability of machine learning (ML) frameworks and tools, as well as their promise to improve solutions to data-driven decision problems, has resulted in popularity of using ML techniques in software systems. However, end-to-end development of ML-enabled systems, as well as their seamless deployment and operations, remain a challenge. One reason is that development and deployment of ML-enabled systems involves three distinct workflows, perspectives, and roles, which include data science, software engineering, and operations. These three distinct perspectives, when misaligned due to incorrect assumptions, cause ML mismatches which can result in failed systems. We conducted an interview and survey study where we collected and validated common types of mismatches that occur in end-to-end development of ML-enabled systems. Our analysis shows that how each role prioritizes the importance of relevant mismatches varies, potentially contributing to these mismatched assumptions. In addition, the mismatch categories we identified can be specified as machine readable descriptors contributing to improved ML-enabled system development. In this paper, we report our findings and their implications for improving end-to-end ML-enabled system development.
Component Mismatches Are a Critical Bottleneck to Fielding AI-Enabled Systems in the Public Sector
Oct 14, 2019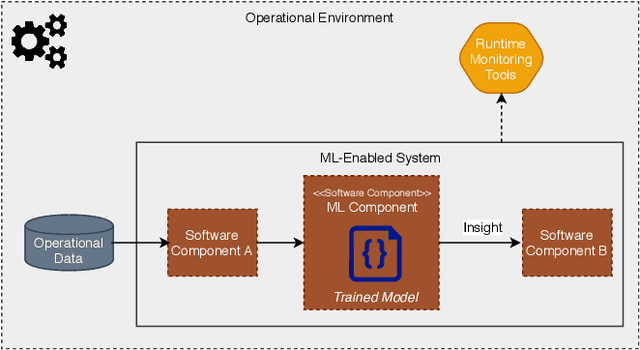
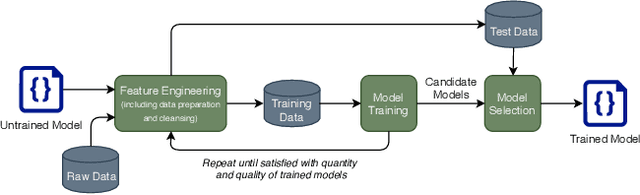
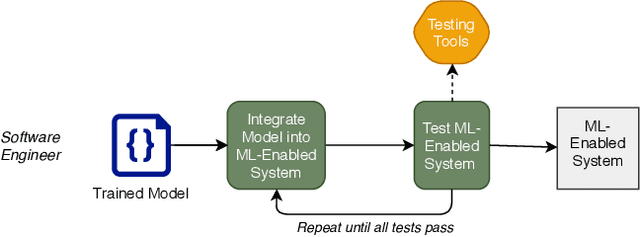
The use of machine learning or artificial intelligence (ML/AI) holds substantial potential toward improving many functions and needs of the public sector. In practice however, integrating ML/AI components into public sector applications is severely limited not only by the fragility of these components and their algorithms, but also because of mismatches between components of ML-enabled systems. For example, if an ML model is trained on data that is different from data in the operational environment, field performance of the ML component will be dramatically reduced. Separate from software engineering considerations, the expertise needed to field an ML/AI component within a system frequently comes from outside software engineering. As a result, assumptions and even descriptive language used by practitioners from these different disciplines can exacerbate other challenges to integrating ML/AI components into larger systems. We are investigating classes of mismatches in ML/AI systems integration, to identify the implicit assumptions made by practitioners in different fields (data scientists, software engineers, operations staff) and find ways to communicate the appropriate information explicitly. We will discuss a few categories of mismatch, and provide examples from each class. To enable ML/AI components to be fielded in a meaningful way, we will need to understand the mismatches that exist and develop practices to mitigate the impacts of these mismatches.