 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Stylistic Variation in Human and LLM Writing Across Genres, Models, and Decoding Strategies
Apr 15, 2026Large Language Models (LLMs) are now capable of generating highly fluent, human-like text. They enable many applications, but also raise concerns such as large scale spam, phishing, or academic misuse. While much work has focused on detecting LLM-generated text, only limited work has gone into understanding the stylistic differences between human-written and machine-generated text. In this work, we perform a large scale analysis of stylistic variation across human-written text and outputs from 11 LLMs spanning 8 different genres and 4 decoding strategies using Douglas Biber's set of lexicogrammatical and functional features. Our findings reveal insights that can guide intentional LLM usage. First, key linguistic differentiators of LLM-generated text seem robust to generation conditions (e.g., prompt settings to nudge them to generate human-like text, or availability of human-written text to continue the style); second, genre exerts a stronger influence on stylistic features than the source itself; third, chat variants of the models generally appear to be clustered together in stylistic space, and finally, model has a larger effect on the style than decoding strategy, with some exceptions. These results highlight the relative importance of model and genre over prompting and decoding strategies in shaping the stylistic behavior of machine-generated text.
The Impact of Imperfect XAI on Human-AI Decision-Making
Jul 25, 2023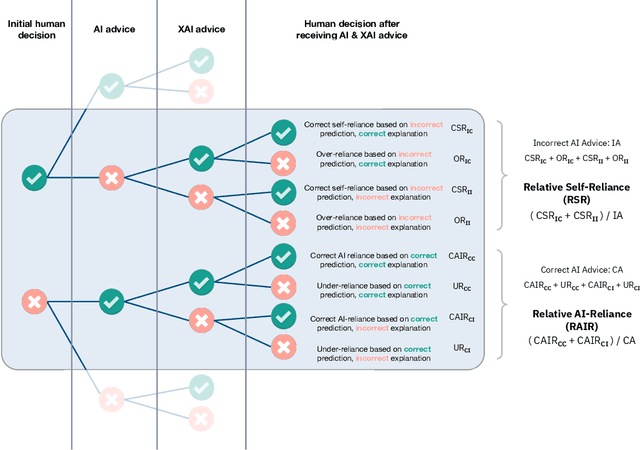
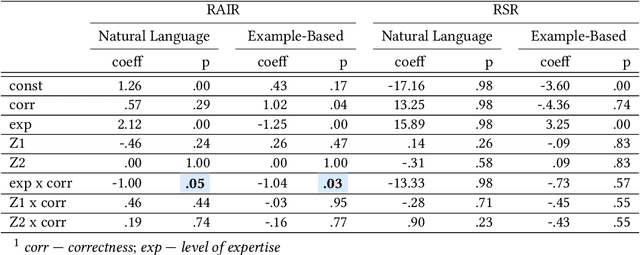
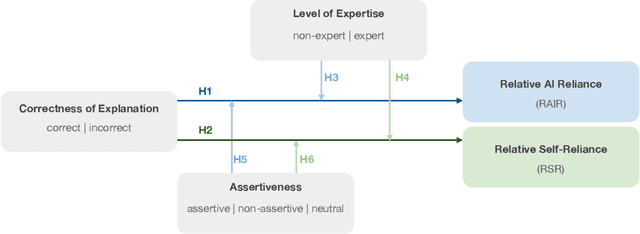
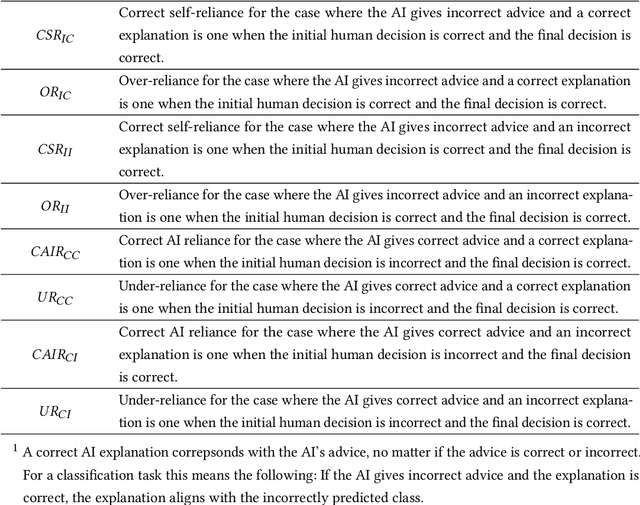
Explainability techniques are rapidly being developed to improve human-AI decision-making across various cooperative work settings. Consequently, previous research has evaluated how decision-makers collaborate with imperfect AI by investigating appropriate reliance and task performance with the aim of designing more human-centered computer-supported collaborative tools. Several human-centered explainable AI (XAI) techniques have been proposed in hopes of improving decision-makers' collaboration with AI; however, these techniques are grounded in findings from previous studies that primarily focus on the impact of incorrect AI advice. Few studies acknowledge the possibility for the explanations to be incorrect even if the AI advice is correct. Thus, it is crucial to understand how imperfect XAI affects human-AI decision-making. In this work, we contribute a robust, mixed-methods user study with 136 participants to evaluate how incorrect explanations influence humans' decision-making behavior in a bird species identification task taking into account their level of expertise and an explanation's level of assertiveness. Our findings reveal the influence of imperfect XAI and humans' level of expertise on their reliance on AI and human-AI team performance. We also discuss how explanations can deceive decision-makers during human-AI collaboration. Hence, we shed light on the impacts of imperfect XAI in the field of computer-supported cooperative work and provide guidelines for designers of human-AI collaboration systems.
Measuring AI Systems Beyond Accuracy
Apr 07, 2022Current test and evaluation (T&E) methods for assessing machine learning (ML) system performance often rely on incomplete metrics. Testing is additionally often siloed from the other phases of the ML system lifecycle. Research investigating cross-domain approaches to ML T&E is needed to drive the state of the art forward and to build an Artificial Intelligence (AI) engineering discipline. This paper advocates for a robust, integrated approach to testing by outlining six key questions for guiding a holistic T&E strategy.