 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Stylistic Variation in Human and LLM Writing Across Genres, Models, and Decoding Strategies
Apr 15, 2026Large Language Models (LLMs) are now capable of generating highly fluent, human-like text. They enable many applications, but also raise concerns such as large scale spam, phishing, or academic misuse. While much work has focused on detecting LLM-generated text, only limited work has gone into understanding the stylistic differences between human-written and machine-generated text. In this work, we perform a large scale analysis of stylistic variation across human-written text and outputs from 11 LLMs spanning 8 different genres and 4 decoding strategies using Douglas Biber's set of lexicogrammatical and functional features. Our findings reveal insights that can guide intentional LLM usage. First, key linguistic differentiators of LLM-generated text seem robust to generation conditions (e.g., prompt settings to nudge them to generate human-like text, or availability of human-written text to continue the style); second, genre exerts a stronger influence on stylistic features than the source itself; third, chat variants of the models generally appear to be clustered together in stylistic space, and finally, model has a larger effect on the style than decoding strategy, with some exceptions. These results highlight the relative importance of model and genre over prompting and decoding strategies in shaping the stylistic behavior of machine-generated text.
SENSE: Semantically Enhanced Node Sequence Embedding
Nov 07, 2019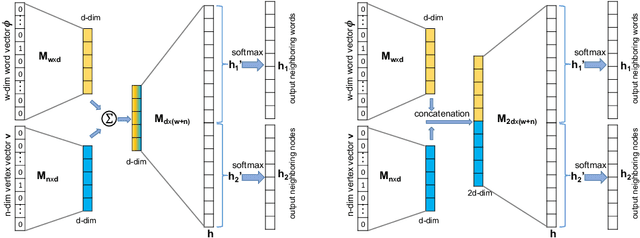
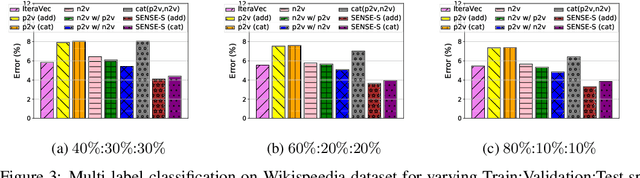
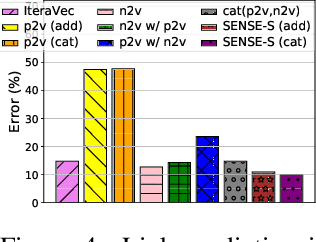
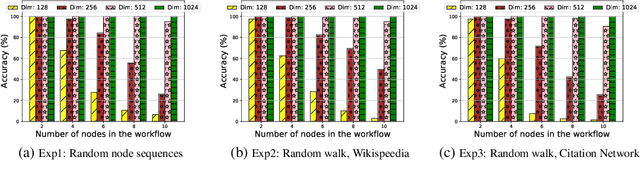
Effectively capturing graph node sequences in the form of vector embeddings is critical to many applications. We achieve this by (i) first learning vector embeddings of single graph nodes and (ii) then composing them to compactly represent node sequences. Specifically, we propose SENSE-S (Semantically Enhanced Node Sequence Embedding - for Single nodes), a skip-gram based novel embedding mechanism, for single graph nodes that co-learns graph structure as well as their textual descriptions. We demonstrate that SENSE-S vectors increase the accuracy of multi-label classification tasks by up to 50% and link-prediction tasks by up to 78% under a variety of scenarios using real datasets. Based on SENSE-S, we next propose generic SENSE to compute composite vectors that represent a sequence of nodes, where preserving the node order is important. We prove that this approach is efficient in embedding node sequences, and our experiments on real data confirm its high accuracy in node order decoding.
Actor Conditioned Attention Maps for Video Action Detection
Dec 30, 2018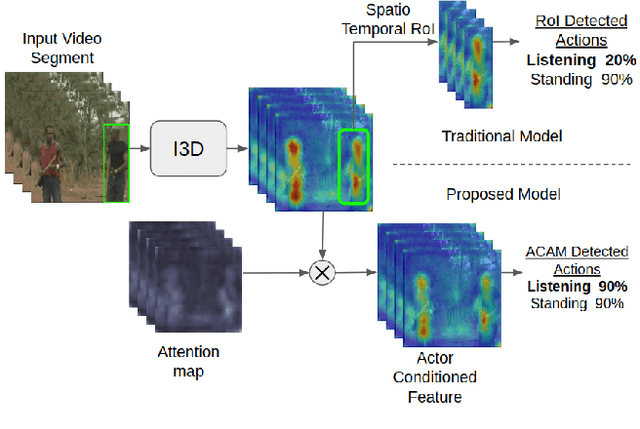
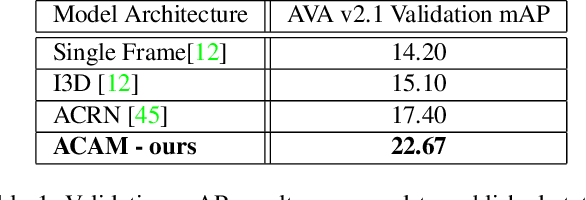

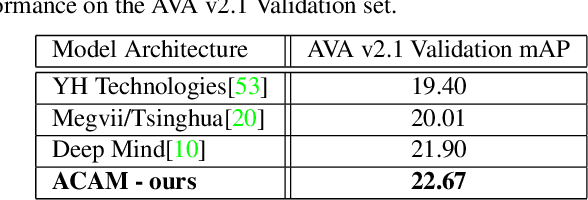
Interactions with surrounding objects and people contain important information towards understanding human actions. In order to model such interactions explicitly, we propose to generate attention maps that rank each spatio-temporal region's importance to a detected actor. We refer to these as Actor-Conditioned Attention Maps (ACAM), and these maps serve as weights to the features extracted from the whole scene. These resulting actor-conditioned features help focus the learned model on regions that are important/relevant to the conditioned actor. Another novelty of our approach is in the use of pre-trained object detectors, instead of region proposals, that generalize better to videos from different sources. Detailed experimental results on the AVA 2.1 datasets demonstrate the importance of interactions, with a performance improvement of 5 mAP with respect to state of the art published results.
Object Localization and Size Estimation from RGB-D Images
Aug 02, 2018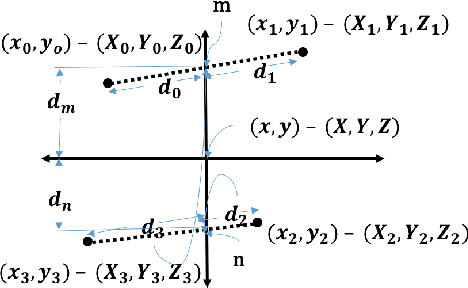



Depth sensing cameras (e.g., Kinect sensor, Tango phone) can acquire color and depth images that are registered to a common viewpoint. This opens the possibility of developing algorithms that exploit the advantages of both sensing modalities. Traditionally, cues from color images have been used for object localization (e.g., YOLO). However, the addition of a depth image can be further used to segment images that might otherwise have identical color information. Further, the depth image can be used for object size (height/width) estimation (in real-world measurements units, such as meters) as opposed to image based segmentation that would only support drawing bounding boxes around objects of interest. In this paper, we first collect color camera information along with depth information using a custom Android application on Tango Phab2 phone. Second, we perform timing and spatial alignment between the two data sources. Finally, we evaluate several ways of measuring the height of the object of interest within the captured images under a variety of settings.
Modeling the Resource Requirements of Convolutional Neural Networks on Mobile Devices
Sep 27, 2017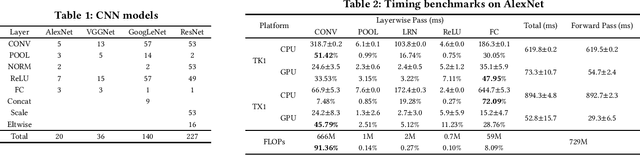
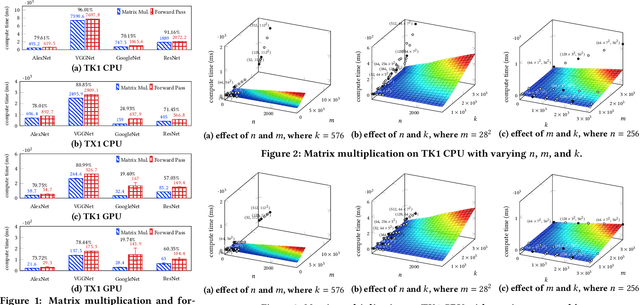
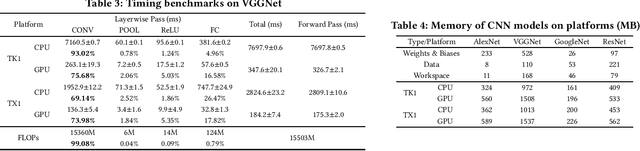
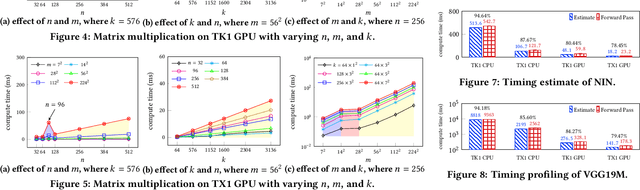
Convolutional Neural Networks (CNNs) have revolutionized the research in computer vision, due to their ability to capture complex patterns, resulting in high inference accuracies. However, the increasingly complex nature of these neural networks means that they are particularly suited for server computers with powerful GPUs. We envision that deep learning applications will be eventually and widely deployed on mobile devices, e.g., smartphones, self-driving cars, and drones. Therefore, in this paper, we aim to understand the resource requirements (time, memory) of CNNs on mobile devices. First, by deploying several popular CNNs on mobile CPUs and GPUs, we measure and analyze the performance and resource usage for every layer of the CNNs. Our findings point out the potential ways of optimizing the performance on mobile devices. Second, we model the resource requirements of the different CNN computations. Finally, based on the measurement, pro ling, and modeling, we build and evaluate our modeling tool, Augur, which takes a CNN configuration (descriptor) as the input and estimates the compute time and resource usage of the CNN, to give insights about whether and how e ciently a CNN can be run on a given mobile platform. In doing so Augur tackles several challenges: (i) how to overcome pro ling and measurement overhead; (ii) how to capture the variance in different mobile platforms with different processors, memory, and cache sizes; and (iii) how to account for the variance in the number, type and size of layers of the different CNN configurations.
Beyond Spatial Auto-Regressive Models: Predicting Housing Prices with Satellite Imagery
Oct 16, 2016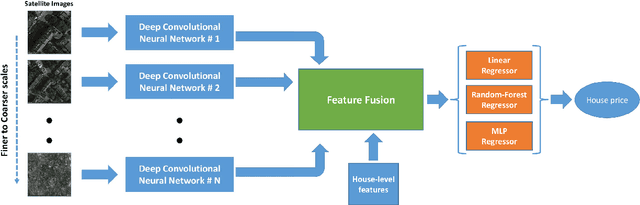
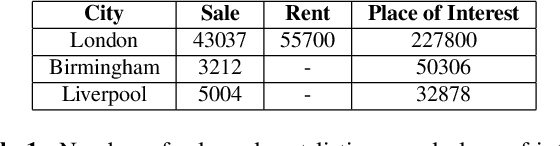


When modeling geo-spatial data, it is critical to capture spatial correlations for achieving high accuracy. Spatial Auto-Regression (SAR) is a common tool used to model such data, where the spatial contiguity matrix (W) encodes the spatial correlations. However, the efficacy of SAR is limited by two factors. First, it depends on the choice of contiguity matrix, which is typically not learnt from data, but instead, is assumed to be known apriori. Second, it assumes that the observations can be explained by linear models. In this paper, we propose a Convolutional Neural Network (CNN) framework to model geo-spatial data (specifi- cally housing prices), to learn the spatial correlations automatically. We show that neighborhood information embedded in satellite imagery can be leveraged to achieve the desired spatial smoothing. An additional upside of our framework is the relaxation of linear assumption on the data. Specific challenges we tackle while implementing our framework include, (i) how much of the neighborhood is relevant while estimating housing prices? (ii) what is the right approach to capture multiple resolutions of satellite imagery? and (iii) what other data-sources can help improve the estimation of spatial correlations? We demonstrate a marked improvement of 57% on top of the SAR baseline through the use of features from deep neural networks for the cities of London, Birmingham and Liverpool.