 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlue Data Intelligence Layer: Streaming Data and Agents for Multi-source Multi-modal Data-Centric Applications
Apr 16, 2026NL2SQL systems aim to address the growing need for natural language interaction with data. However, real-world information rarely maps to a single SQL query because (1) users express queries iteratively (2) questions often span multiple data sources beyond the closed-world assumption of a single database, and (3) queries frequently rely on commonsense or external knowledge. Consequently, satisfying realistic data needs require integrating heterogeneous sources, modalities, and contextual data. In this paper, we present Blue's Data Intelligence Layer (DIL) designed to support multi-source, multi-modal, and data-centric applications. Blue is a compound AI system that orchestrates agents and data for enterprise settings. DIL serves as the data intelligence layer for agentic data processing, to bridge the semantic gap between user intent and available information by unifying structured enterprise data, world knowledge accessible through LLMs, and personal context obtained through interaction. At the core of DIL is a data registry that stores metadata for diverse data sources and modalities to enable both native and natural language queries. DIL treats LLMs, the Web, and the User as source 'databases', each with their own query interface, elevating them to first-class data sources. DIL relies on data planners to transform user queries into executable query plans. These plans are declarative abstractions that unify relational operators with other operators spanning multiple modalities. DIL planners support decomposition of complex requests into subqueries, retrieval from diverse sources, and finally reasoning and integration to produce final results. We demonstrate DIL through two interactive scenarios in which user queries dynamically trigger multi-source retrieval, cross-modal reasoning, and result synthesis, illustrating how compound AI systems can move beyond single database NL2SQL.
Regularized Calibration with Successive Rounding for Post-Training Quantization
Feb 05, 2026Large language models (LLMs) deliver robust performance across diverse applications, yet their deployment often faces challenges due to the memory and latency costs of storing and accessing billions of parameters. Post-training quantization (PTQ) enables efficient inference by mapping pretrained weights to low-bit formats without retraining, but its effectiveness depends critically on both the quantization objective and the rounding procedure used to obtain low-bit weight representations. In this work, we show that interpolating between symmetric and asymmetric calibration acts as a form of regularization that preserves the standard quadratic structure used in PTQ while providing robustness to activation mismatch. Building on this perspective, we derive a simple successive rounding procedure that naturally incorporates asymmetric calibration, as well as a bounded-search extension that allows for an explicit trade-off between quantization quality and the compute cost. Experiments across multiple LLM families, quantization bit-widths, and benchmarks demonstrate that the proposed bounded search based on a regularized asymmetric calibration objective consistently improves perplexity and accuracy over PTQ baselines, while incurring only modest and controllable additional computational cost.
A Differentiable Digital Twin of Distributed Link Scheduling for Contention-Aware Networking
Dec 11, 2025



Many routing and flow optimization problems in wired networks can be solved efficiently using minimum cost flow formulations. However, this approach does not extend to wireless multi-hop networks, where the assumptions of fixed link capacity and linear cost structure collapse due to contention for shared spectrum resources. The key challenge is that the long-term capacity of a wireless link becomes a non-linear function of its network context, including network topology, link quality, and the traffic assigned to neighboring links. In this work, we pursue a new direction of modeling wireless network under randomized medium access control by developing an analytical network digital twin (NDT) that predicts link duty cycles from network context. We generalize randomized contention as finding a Maximal Independent Set (MIS) on the conflict graph using weighted Luby's algorithm, derive an analytical model of link duty cycles, and introduce an iterative procedure that resolves the circular dependency among duty cycle, link capacity, and contention probability. Our numerical experiments show that the proposed NDT accurately predicts link duty cycles and congestion patterns with up to a 5000x speedup over packet-level simulation, and enables us to optimize link scheduling using gradient descent for reduced congestion and radio footprint.
Omnilingual ASR: Open-Source Multilingual Speech Recognition for 1600+ Languages
Nov 12, 2025



Automatic speech recognition (ASR) has advanced in high-resource languages, but most of the world's 7,000+ languages remain unsupported, leaving thousands of long-tail languages behind. Expanding ASR coverage has been costly and limited by architectures that restrict language support, making extension inaccessible to most--all while entangled with ethical concerns when pursued without community collaboration. To transcend these limitations, we introduce Omnilingual ASR, the first large-scale ASR system designed for extensibility. Omnilingual ASR enables communities to introduce unserved languages with only a handful of data samples. It scales self-supervised pre-training to 7B parameters to learn robust speech representations and introduces an encoder-decoder architecture designed for zero-shot generalization, leveraging a LLM-inspired decoder. This capability is grounded in a massive and diverse training corpus; by combining breadth of coverage with linguistic variety, the model learns representations robust enough to adapt to unseen languages. Incorporating public resources with community-sourced recordings gathered through compensated local partnerships, Omnilingual ASR expands coverage to over 1,600 languages, the largest such effort to date--including over 500 never before served by ASR. Automatic evaluations show substantial gains over prior systems, especially in low-resource conditions, and strong generalization. We release Omnilingual ASR as a family of models, from 300M variants for low-power devices to 7B for maximum accuracy. We reflect on the ethical considerations shaping this design and conclude by discussing its societal impact. In particular, we highlight how open-sourcing models and tools can lower barriers for researchers and communities, inviting new forms of participation. Open-source artifacts are available at https://github.com/facebookresearch/omnilingual-asr.
SeLR: Sparsity-enhanced Lagrangian Relaxation for Computation Offloading at the Edge
May 01, 2025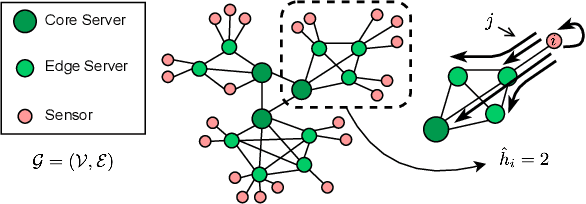
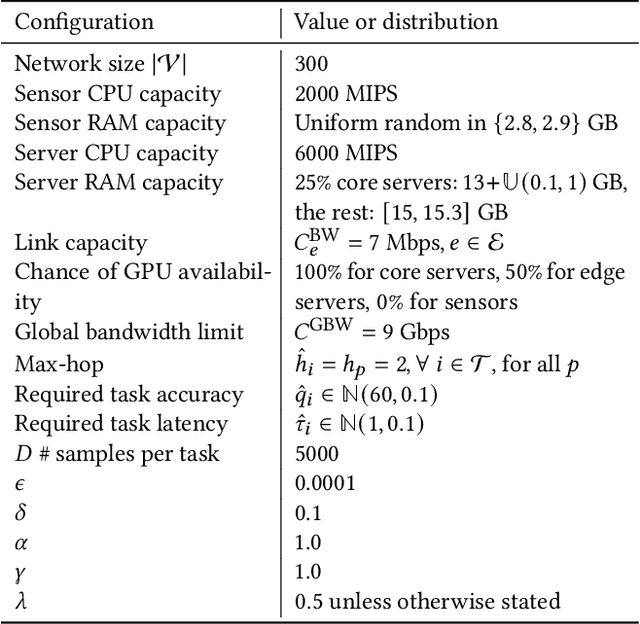
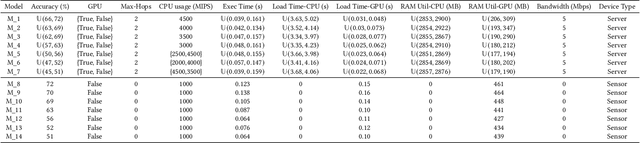
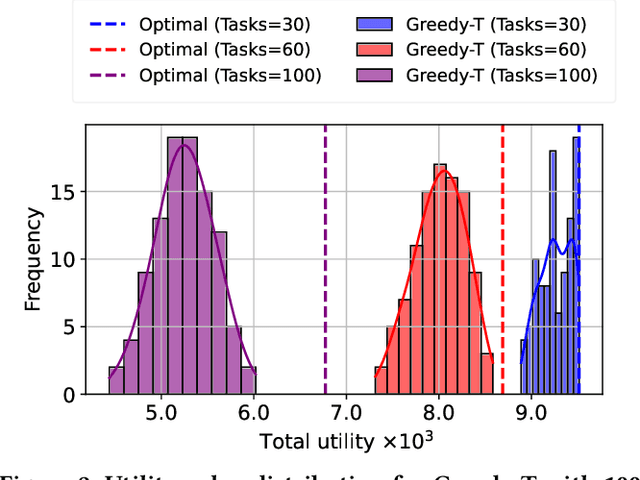
This paper introduces a novel computational approach for offloading sensor data processing tasks to servers in edge networks for better accuracy and makespan. A task is assigned with one of several offloading options, each comprises a server, a route for uploading data to the server, and a service profile that specifies the performance and resource consumption at the server and in the network. This offline offloading and routing problem is formulated as mixed integer programming (MIP), which is non-convex and HP-hard due to the discrete decision variables associated to the offloading options. The novelty of our approach is to transform this non-convex problem into iterative convex optimization by relaxing integer decision variables into continuous space, combining primal-dual optimization for penalizing constraint violations and reweighted $L_1$-minimization for promoting solution sparsity, which achieves better convergence through a smoother path in a continuous search space. Compared to existing greedy heuristics, our approach can achieve a better Pareto frontier in accuracy and latency, scales better to larger problem instances, and can achieve a 7.72--9.17$\times$ reduction in computational overhead of scheduling compared to the optimal solver in hierarchically organized edge networks with 300 nodes and 50--100 tasks.
Generalizing Biased Backpressure Routing and Scheduling to Wireless Multi-hop Networks with Advanced Air-interfaces
Apr 30, 2025
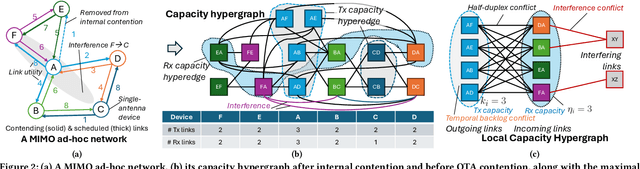
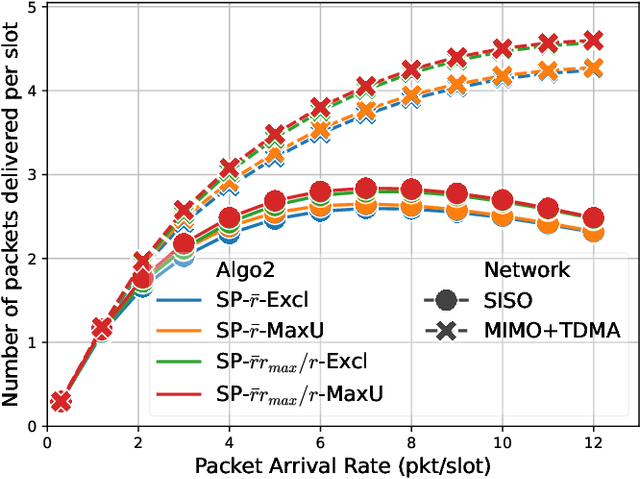
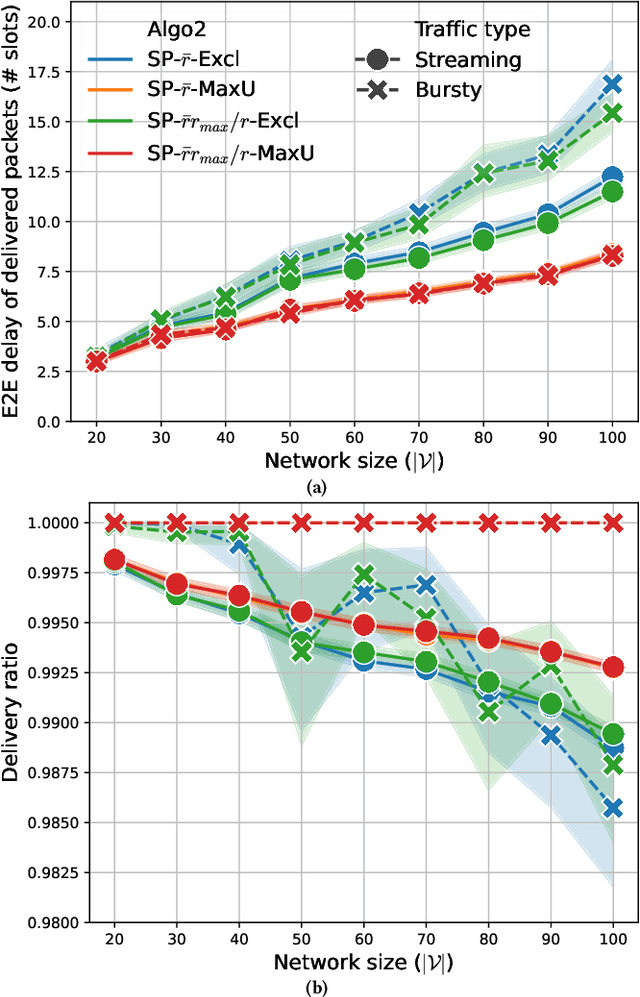
Backpressure (BP) routing and scheduling is a well-established resource allocation method for wireless multi-hop networks, known for its fully distributed operations and proven maximum queue stability. Recent advances in shortest path-biased BP routing (SP-BP) mitigate shortcomings such as slow startup and random walk, but exclusive link-level commodity selection still suffers from the last-packet problem and bandwidth underutilization. Moreover, classic BP routing implicitly assumes single-input-single-output (SISO) transceivers, which can lead to the same packets being scheduled on multiple outgoing links for multiple-input-multiple-output (MIMO) transceivers, causing detouring and looping in MIMO networks. In this paper, we revisit the foundational Lyapunov drift theory underlying BP routing and demonstrate that exclusive commodity selection is unnecessary, and instead propose a Max-Utility link-sharing method. Additionally, we generalize MaxWeight scheduling to MIMO networks by introducing attributed capacity hypergraphs (ACH), an extension of traditional conflict graphs for SISO networks, and by incorporating backlog reassignment into scheduling iterations to prevent redundant packet routing. Numerical evaluations show that our approach substantially mitigates the last-packet problem in state-of-the-art (SOTA) SP-BP under lightweight traffic, and slightly expands the network capacity region for heavier traffic.
Joint Task Offloading and Routing in Wireless Multi-hop Networks Using Biased Backpressure Algorithm
Dec 19, 2024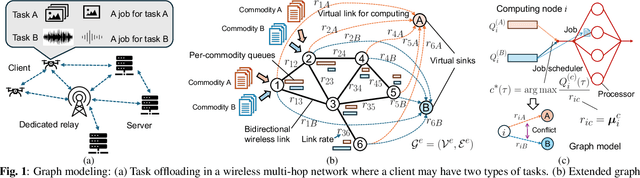
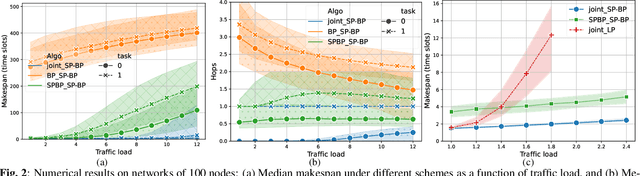
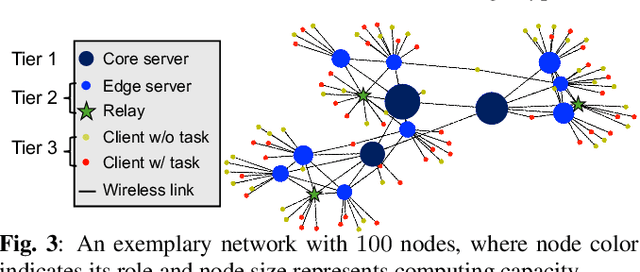
A significant challenge for computation offloading in wireless multi-hop networks is the complex interaction among traffic flows in the presence of interference. Existing approaches often ignore these key effects and/or rely on outdated queueing and channel state information. To fill these gaps, we reformulate joint offloading and routing as a routing problem on an extended graph with physical and virtual links. We adopt the state-of-the-art shortest path-biased Backpressure routing algorithm, which allows the destination and the route of a job to be dynamically adjusted at every time step based on network-wide long-term information and real-time states of local neighborhoods. In large networks, our approach achieves smaller makespan than existing approaches, such as separated Backpressure offloading and joint offloading and routing based on linear programming.
Fully Distributed Online Training of Graph Neural Networks in Networked Systems
Dec 08, 2024


Graph neural networks (GNNs) are powerful tools for developing scalable, decentralized artificial intelligence in large-scale networked systems, such as wireless networks, power grids, and transportation networks. Currently, GNNs in networked systems mostly follow a paradigm of `centralized training, distributed execution', which limits their adaptability and slows down their development cycles. In this work, we fill this gap for the first time by developing a communication-efficient, fully distributed online training approach for GNNs applied to large networked systems. For a mini-batch with $B$ samples, our approach of training an $L$-layer GNN only adds $L$ rounds of message passing to the $LB$ rounds required by GNN inference, with doubled message sizes. Through numerical experiments in graph-based node regression, power allocation, and link scheduling in wireless networks, we demonstrate the effectiveness of our approach in training GNNs under supervised, unsupervised, and reinforcement learning paradigms.
Adversarial Plannning
May 01, 2022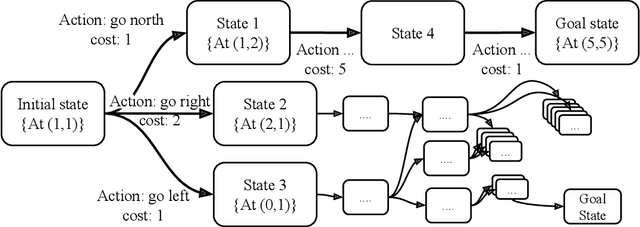
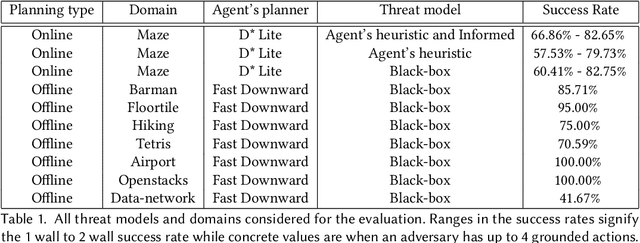
Planning algorithms are used in computational systems to direct autonomous behavior. In a canonical application, for example, planning for autonomous vehicles is used to automate the static or continuous planning towards performance, resource management, or functional goals (e.g., arriving at the destination, managing fuel fuel consumption). Existing planning algorithms assume non-adversarial settings; a least-cost plan is developed based on available environmental information (i.e., the input instance). Yet, it is unclear how such algorithms will perform in the face of adversaries attempting to thwart the planner. In this paper, we explore the security of planning algorithms used in cyber- and cyber-physical systems. We present two $\textit{adversarial planning}$ algorithms-one static and one adaptive-that perturb input planning instances to maximize cost (often substantially so). We evaluate the performance of the algorithms against two dominant planning algorithms used in commercial applications (D* Lite and Fast Downward) and show both are vulnerable to extremely limited adversarial action. Here, experiments show that an adversary is able to increase plan costs in 66.9% of instances by only removing a single action from the actions space (D* Lite) and render 70% of instances from an international planning competition unsolvable by removing only three actions (Fast Forward). Finally, we show that finding an optimal perturbation in any search-based planning system is NP-hard.
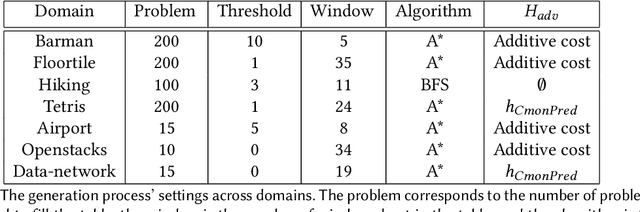
Communication-Efficient Device Scheduling for Federated Learning Using Stochastic Optimization
Jan 19, 2022
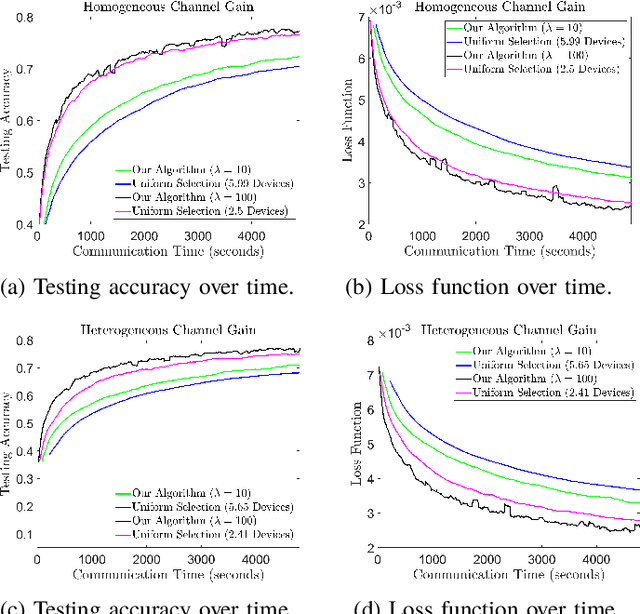
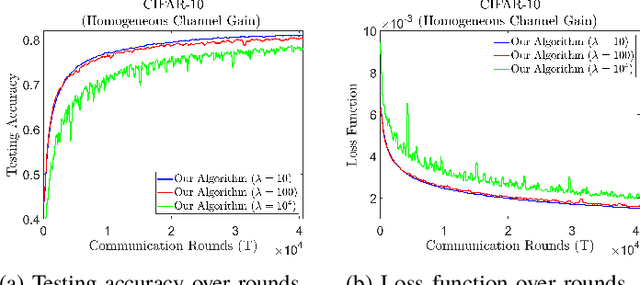
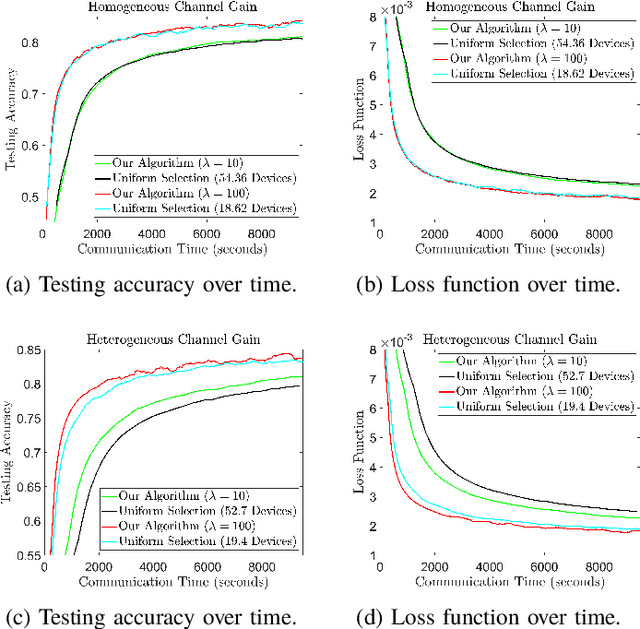
Federated learning (FL) is a useful tool in distributed machine learning that utilizes users' local datasets in a privacy-preserving manner. When deploying FL in a constrained wireless environment; however, training models in a time-efficient manner can be a challenging task due to intermittent connectivity of devices, heterogeneous connection quality, and non-i.i.d. data. In this paper, we provide a novel convergence analysis of non-convex loss functions using FL on both i.i.d. and non-i.i.d. datasets with arbitrary device selection probabilities for each round. Then, using the derived convergence bound, we use stochastic optimization to develop a new client selection and power allocation algorithm that minimizes a function of the convergence bound and the average communication time under a transmit power constraint. We find an analytical solution to the minimization problem. One key feature of the algorithm is that knowledge of the channel statistics is not required and only the instantaneous channel state information needs to be known. Using the FEMNIST and CIFAR-10 datasets, we show through simulations that the communication time can be significantly decreased using our algorithm, compared to uniformly random participation.