 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Trojan Detection Competitions with Linear Weight Classification
Nov 05, 2024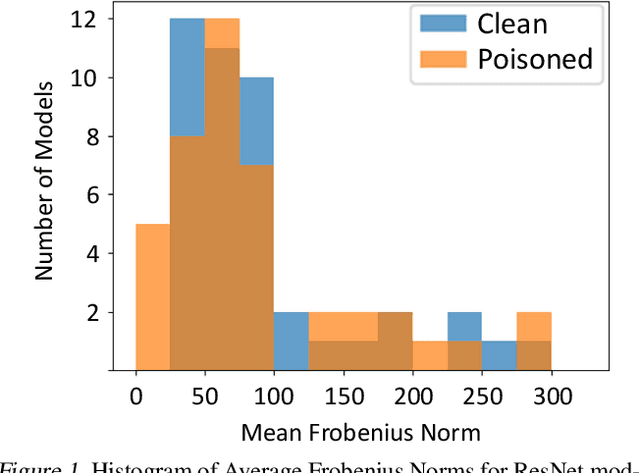
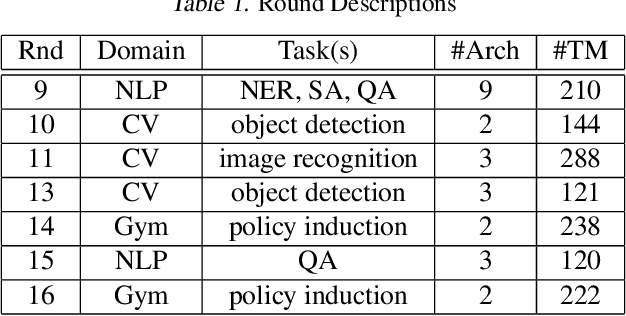
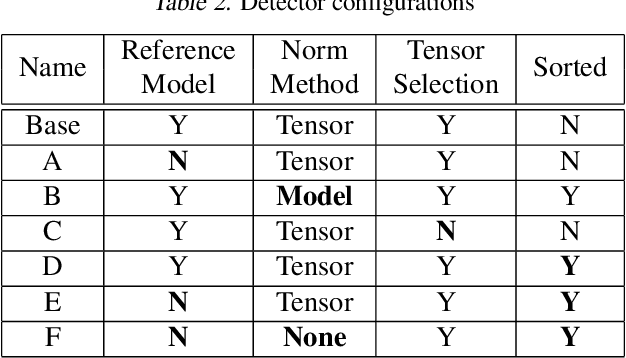
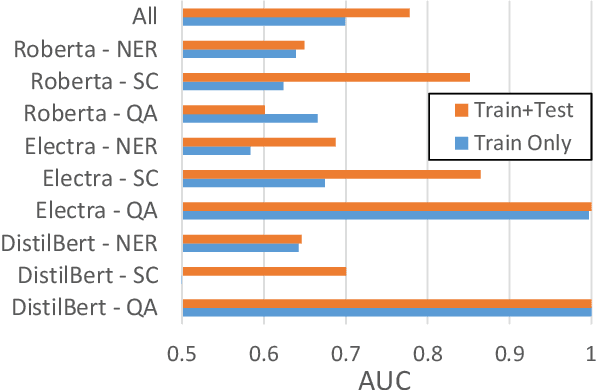
Neural networks can conceal malicious Trojan backdoors that allow a trigger to covertly change the model behavior. Detecting signs of these backdoors, particularly without access to any triggered data, is the subject of ongoing research and open challenges. In one common formulation of the problem, we are given a set of clean and poisoned models and need to predict whether a given test model is clean or poisoned. In this paper, we introduce a detector that works remarkably well across many of the existing datasets and domains. It is obtained by training a binary classifier on a large number of models' weights after performing a few different pre-processing steps including feature selection and standardization, reference model weights subtraction, and model alignment prior to detection. We evaluate this algorithm on a diverse set of Trojan detection benchmarks and domains and examine the cases where the approach is most and least effective.
ReFace: Real-time Adversarial Attacks on Face Recognition Systems
Jun 09, 2022
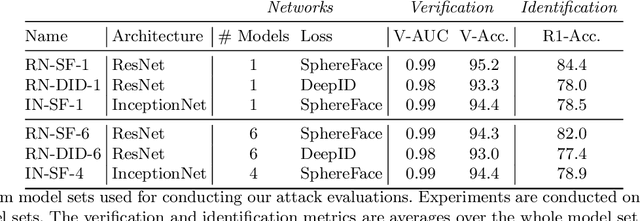
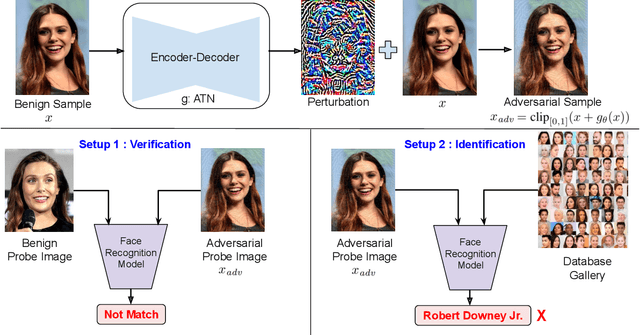
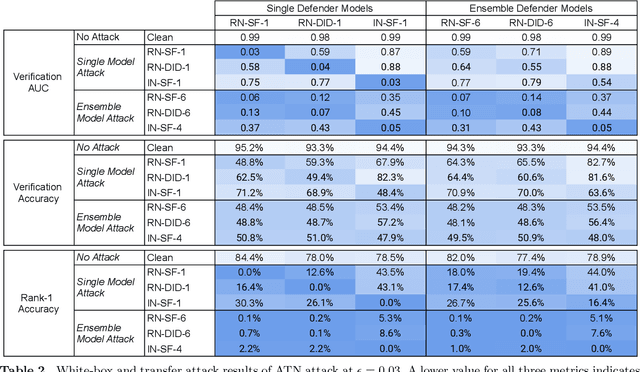
Deep neural network based face recognition models have been shown to be vulnerable to adversarial examples. However, many of the past attacks require the adversary to solve an input-dependent optimization problem using gradient descent which makes the attack impractical in real-time. These adversarial examples are also tightly coupled to the attacked model and are not as successful in transferring to different models. In this work, we propose ReFace, a real-time, highly-transferable attack on face recognition models based on Adversarial Transformation Networks (ATNs). ATNs model adversarial example generation as a feed-forward neural network. We find that the white-box attack success rate of a pure U-Net ATN falls substantially short of gradient-based attacks like PGD on large face recognition datasets. We therefore propose a new architecture for ATNs that closes this gap while maintaining a 10000x speedup over PGD. Furthermore, we find that at a given perturbation magnitude, our ATN adversarial perturbations are more effective in transferring to new face recognition models than PGD. ReFace attacks can successfully deceive commercial face recognition services in a transfer attack setting and reduce face identification accuracy from 82% to 16.4% for AWS SearchFaces API and Azure face verification accuracy from 91% to 50.1%.
Scaled-Time-Attention Robust Edge Network
Jul 09, 2021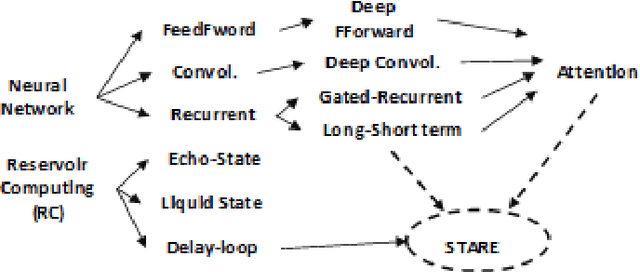
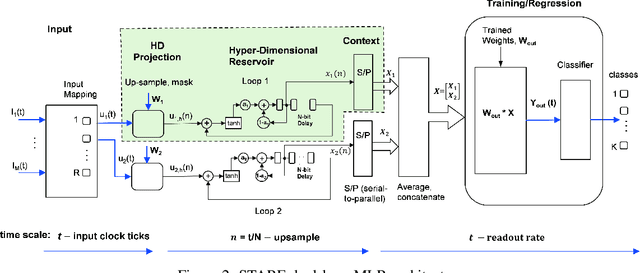
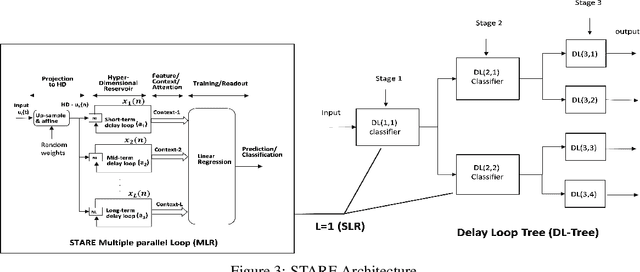
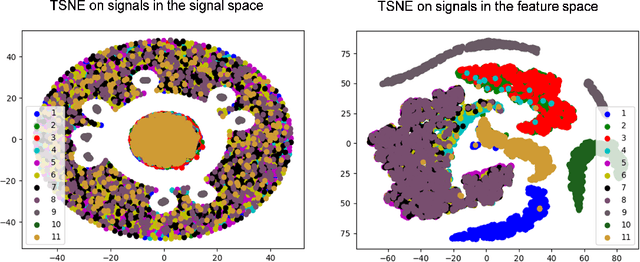
This paper describes a systematic approach towards building a new family of neural networks based on a delay-loop version of a reservoir neural network. The resulting architecture, called Scaled-Time-Attention Robust Edge (STARE) network, exploits hyper dimensional space and non-multiply-and-add computation to achieve a simpler architecture, which has shallow layers, is simple to train, and is better suited for Edge applications, such as Internet of Things (IoT), over traditional deep neural networks. STARE incorporates new AI concepts such as Attention and Context, and is best suited for temporal feature extraction and classification. We demonstrate that STARE is applicable to a variety of applications with improved performance and lower implementation complexity. In particular, we showed a novel way of applying a dual-loop configuration to detection and identification of drone vs bird in a counter Unmanned Air Systems (UAS) detection application by exploiting both spatial (video frame) and temporal (trajectory) information. We also demonstrated that the STARE performance approaches that of a State-of-the-Art deep neural network in classifying RF modulations, and outperforms Long Short-term Memory (LSTM) in a special case of Mackey Glass time series prediction. To demonstrate hardware efficiency, we designed and developed an FPGA implementation of the STARE algorithm to demonstrate its low-power and high-throughput operations. In addition, we illustrate an efficient structure for integrating a massively parallel implementation of the STARE algorithm for ASIC implementation.
TOP: Backdoor Detection in Neural Networks via Transferability of Perturbation
Mar 18, 2021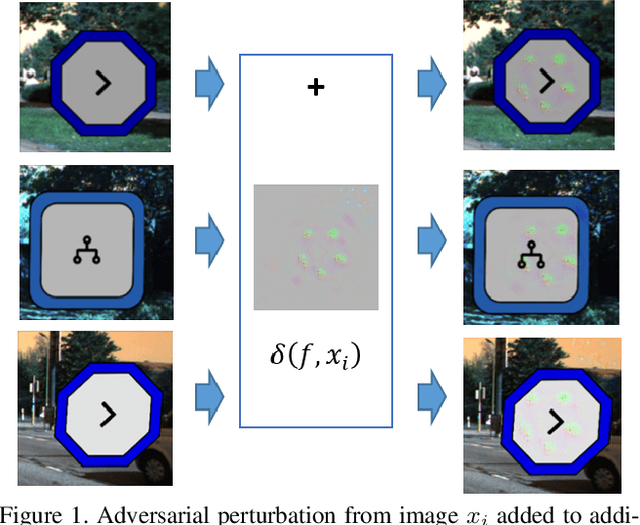
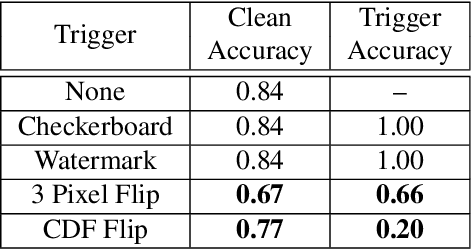
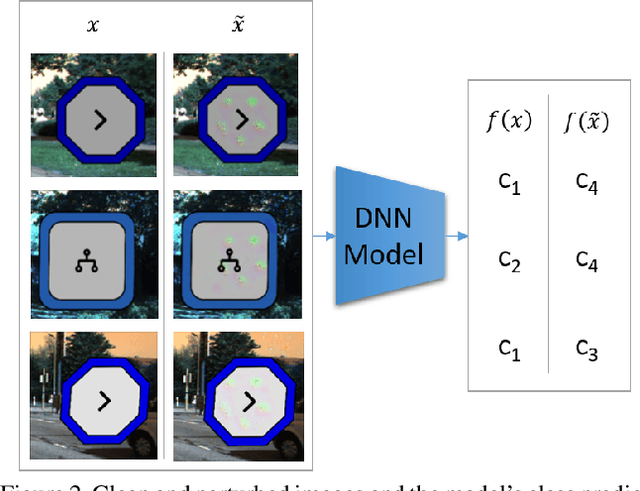
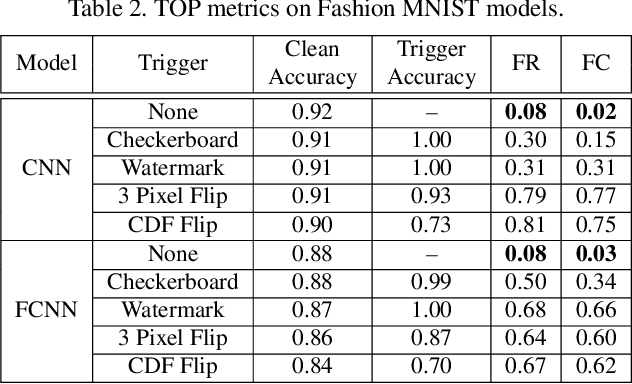
Deep neural networks (DNNs) are vulnerable to "backdoor" poisoning attacks, in which an adversary implants a secret trigger into an otherwise normally functioning model. Detection of backdoors in trained models without access to the training data or example triggers is an important open problem. In this paper, we identify an interesting property of these models: adversarial perturbations transfer from image to image more readily in poisoned models than in clean models. This holds for a variety of model and trigger types, including triggers that are not linearly separable from clean data. We use this feature to detect poisoned models in the TrojAI benchmark, as well as additional models.
Pareto GAN: Extending the Representational Power of GANs to Heavy-Tailed Distributions
Jan 22, 2021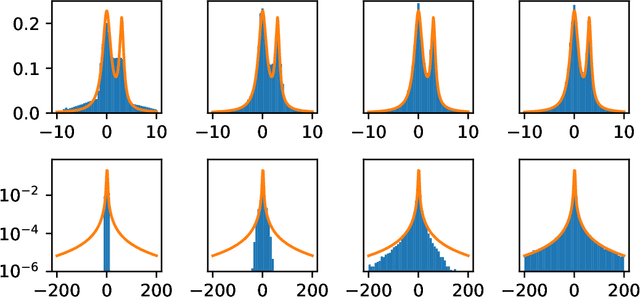
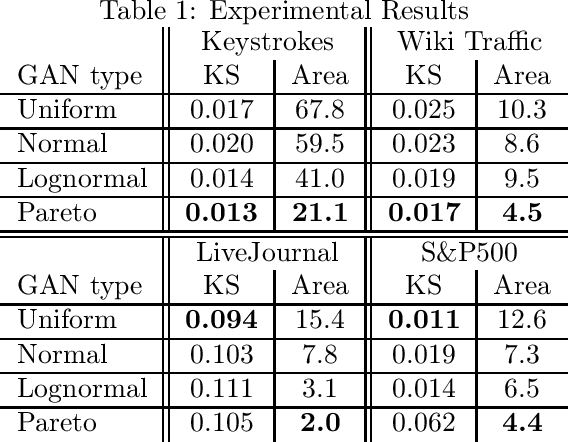
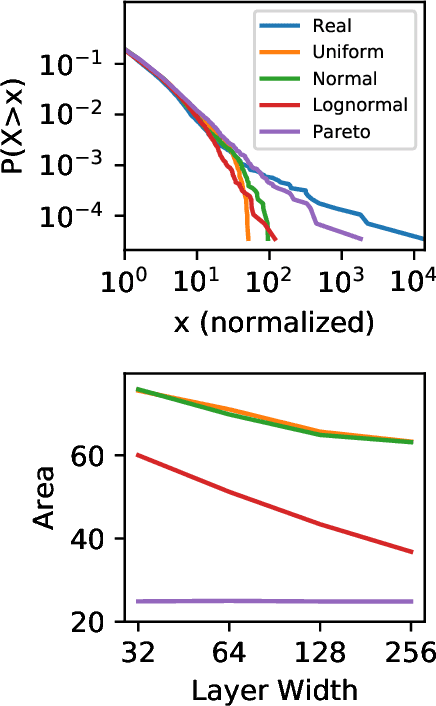
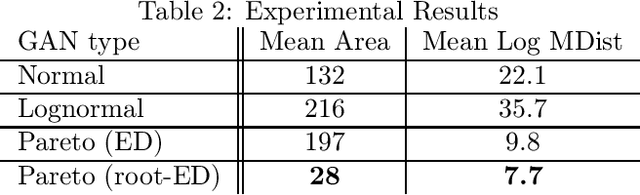
Generative adversarial networks (GANs) are often billed as "universal distribution learners", but precisely what distributions they can represent and learn is still an open question. Heavy-tailed distributions are prevalent in many different domains such as financial risk-assessment, physics, and epidemiology. We observe that existing GAN architectures do a poor job of matching the asymptotic behavior of heavy-tailed distributions, a problem that we show stems from their construction. Additionally, when faced with the infinite moments and large distances between outlier points that are characteristic of heavy-tailed distributions, common loss functions produce unstable or near-zero gradients. We address these problems with the Pareto GAN. A Pareto GAN leverages extreme value theory and the functional properties of neural networks to learn a distribution that matches the asymptotic behavior of the marginal distributions of the features. We identify issues with standard loss functions and propose the use of alternative metric spaces that enable stable and efficient learning. Finally, we evaluate our proposed approach on a variety of heavy-tailed datasets.
Robot Design With Neural Networks, MILP Solvers and Active Learning
Oct 19, 2020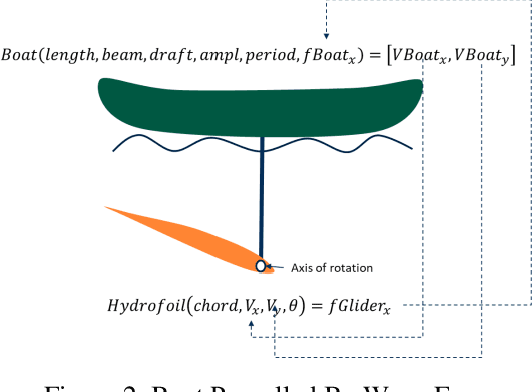
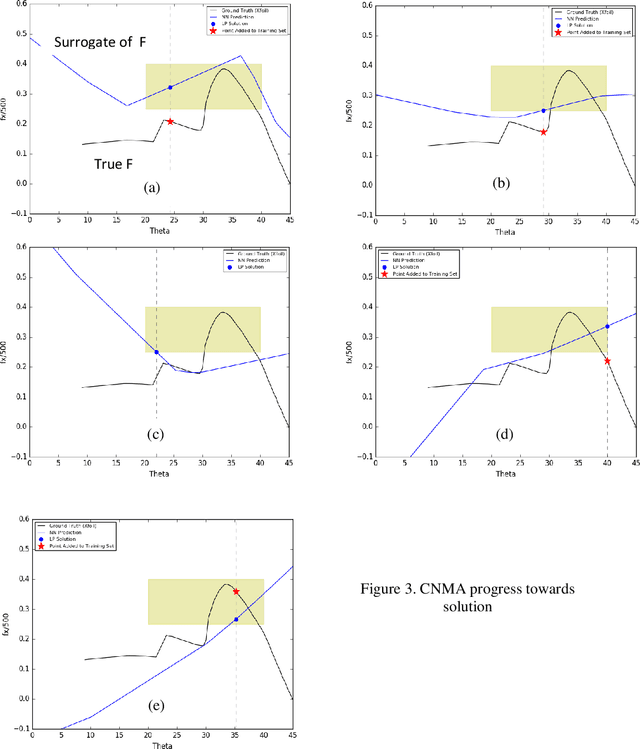
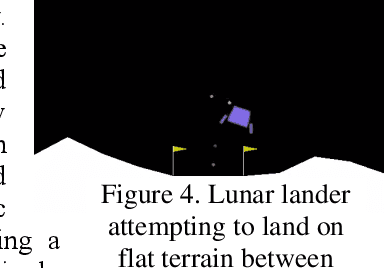
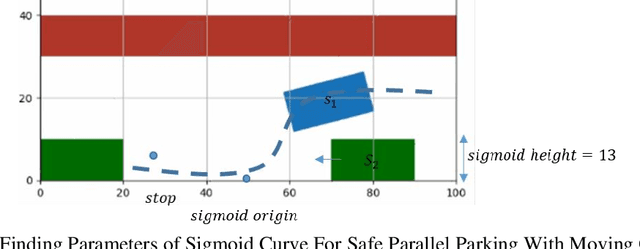
Central to the design of many robot systems and their controllers is solving a constrained blackbox optimization problem. This paper presents CNMA, a new method of solving this problem that is conservative in the number of potentially expensive blackbox function evaluations; allows specifying complex, even recursive constraints directly rather than as hard-to-design penalty or barrier functions; and is resilient to the non-termination of function evaluations. CNMA leverages the ability of neural networks to approximate any continuous function, their transformation into equivalent mixed integer linear programs (MILPs) and their optimization subject to constraints with industrial strength MILP solvers. A new learning-from-failure step guides the learning to be relevant to solving the constrained optimization problem. Thus, the amount of learning is orders of magnitude smaller than that needed to learn functions over their entire domains. CNMA is illustrated with the design of several robotic systems: wave-energy propelled boat, lunar lander, hexapod, cartpole, acrobot and parallel parking. These range from 6 real-valued dimensions to 36. We show that CNMA surpasses the Nelder-Mead, Gaussian and Random Search optimization methods against the metric of number of function evaluations.
Universal Lipschitz Approximation in Bounded Depth Neural Networks
Apr 09, 2019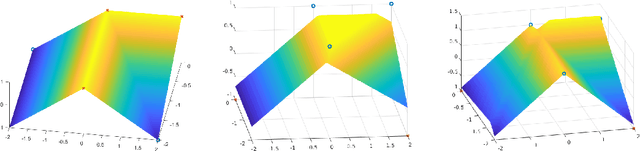
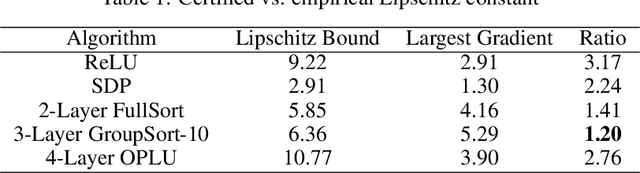
Adversarial attacks against machine learning models are a rather hefty obstacle to our increasing reliance on these models. Due to this, provably robust (certified) machine learning models are a major topic of interest. Lipschitz continuous models present a promising approach to solving this problem. By leveraging the expressive power of a variant of neural networks which maintain low Lipschitz constants, we prove that three layer neural networks using the FullSort activation function are Universal Lipschitz function Approximators (ULAs). This both explains experimental results and paves the way for the creation of better certified models going forward. We conclude by presenting experimental results that suggest that ULAs are a not just a novelty, but a competitive approach to providing certified classifiers, using these results to motivate several potential topics of further research.
Limitations of the Lipschitz constant as a defense against adversarial examples
Jul 25, 2018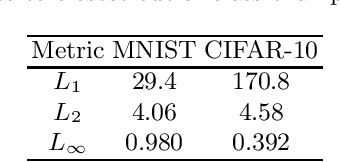
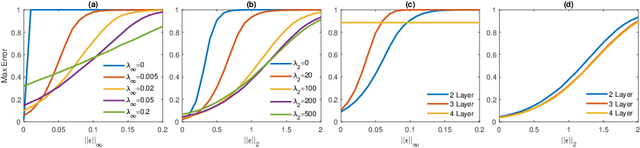
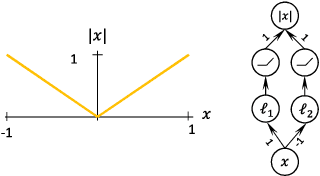
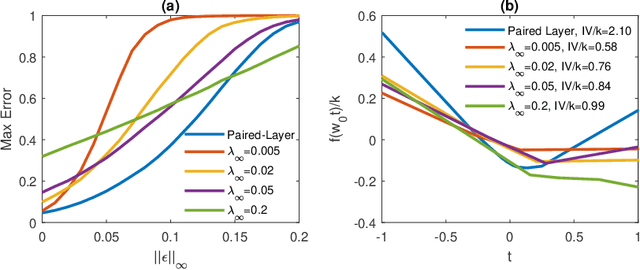
Several recent papers have discussed utilizing Lipschitz constants to limit the susceptibility of neural networks to adversarial examples. We analyze recently proposed methods for computing the Lipschitz constant. We show that the Lipschitz constant may indeed enable adversarially robust neural networks. However, the methods currently employed for computing it suffer from theoretical and practical limitations. We argue that addressing this shortcoming is a promising direction for future research into certified adversarial defenses.