 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Expressive and Customizable Evals for Timeseries Data Analysis Agents with AgentFuel
Mar 12, 2026Across many domains (e.g., IoT, observability, telecommunications, cybersecurity), there is an emerging adoption of conversational data analysis agents that enable users to "talk to your data" to extract insights. Such data analysis agents operate on timeseries data models; e.g., measurements from sensors or events monitoring user clicks and actions in product analytics. We evaluate 6 popular data analysis agents (both open-source and proprietary) on domain-specific data and query types, and find that they fail on stateful and incident-specific queries. We observe two key expressivity gaps in existing evals: domain-customized datasets and domain-specific query types. To enable practitioners in such domains to generate customized and expressive evals for such timeseries data agents, we present AgentFuel. AgentFuel helps domain experts quickly create customized evals to perform end-to-end functional tests. We show that AgentFuel's benchmarks expose key directions for improvement in existing data agent frameworks. We also present anecdotal evidence that using AgentFuel can improve agent performance (e.g., with GEPA). AgentFuel benchmarks are available at https://huggingface.co/datasets/RockfishData/TimeSeriesAgentEvals.
On the Feasibility of Using LLMs to Execute Multistage Network Attacks
Jan 27, 2025LLMs have shown preliminary promise in some security tasks and CTF challenges. However, it is unclear whether LLMs are able to realize multistage network attacks, which involve executing a wide variety of actions across multiple hosts such as conducting reconnaissance, exploiting vulnerabilities to gain initial access, leveraging internal hosts to move laterally, and using multiple compromised hosts to exfiltrate data. We evaluate LLMs across 10 multistage networks and find that popular LLMs are unable to realize these attacks. To enable LLMs to realize these attacks, we introduce Incalmo, an LLM-agnostic high-level attack abstraction layer that sits between an LLM and the environment. Rather than LLMs issuing low-level command-line instructions, which can lead to incorrect implementations, Incalmo allows LLMs to specify high-level tasks (e.g., infect a host, scan a network), which are then carried out by Incalmo. Incalmo realizes these tasks by translating them into low-level primitives (e.g., commands to exploit tools). Incalmo also provides an environment state service and an attack graph service to provide structure to LLMs in selecting actions relevant to a multistage attack. Across 9 out of 10 realistic emulated networks (from 25 to 50 hosts), LLMs using Incalmo can successfully autonomously execute multistage attacks. We also conduct an ablation analysis to show the key role the high-level abstractions play. For instance, we find that both Incalmo's high-level tasks and services are crucial. Furthermore, even smaller-parameter LLMs with Incalmo can fully succeed in 5 of 10 environments, while larger-parameter LLMs without Incalmo do not fully succeed in any.
Summary Statistic Privacy in Data Sharing
Mar 03, 2023



Data sharing between different parties has become increasingly common across industry and academia. An important class of privacy concerns that arises in data sharing scenarios regards the underlying distribution of data. For example, the total traffic volume of data from a networking company can reveal the scale of its business, which may be considered a trade secret. Unfortunately, existing privacy frameworks (e.g., differential privacy, anonymization) do not adequately address such concerns. In this paper, we propose summary statistic privacy, a framework for analyzing and protecting these summary statistic privacy concerns. We propose a class of quantization mechanisms that can be tailored to various data distributions and statistical secrets, and analyze their privacy-distortion trade-offs under our framework. We prove corresponding lower bounds on the privacy-utility tradeoff, which match the tradeoffs of the quantization mechanism under certain regimes, up to small constant factors. Finally, we demonstrate that the proposed quantization mechanisms achieve better privacy-distortion tradeoffs than alternative privacy mechanisms on real-world datasets.
On the Privacy Properties of GAN-generated Samples
Jun 03, 2022
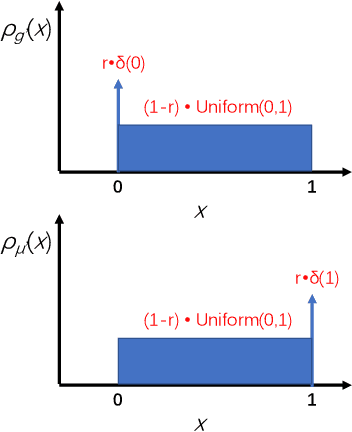
The privacy implications of generative adversarial networks (GANs) are a topic of great interest, leading to several recent algorithms for training GANs with privacy guarantees. By drawing connections to the generalization properties of GANs, we prove that under some assumptions, GAN-generated samples inherently satisfy some (weak) privacy guarantees. First, we show that if a GAN is trained on m samples and used to generate n samples, the generated samples are (epsilon, delta)-differentially-private for (epsilon, delta) pairs where delta scales as O(n/m). We show that under some special conditions, this upper bound is tight. Next, we study the robustness of GAN-generated samples to membership inference attacks. We model membership inference as a hypothesis test in which the adversary must determine whether a given sample was drawn from the training dataset or from the underlying data distribution. We show that this adversary can achieve an area under the ROC curve that scales no better than O(m^{-1/4}).
RareGAN: Generating Samples for Rare Classes
Mar 20, 2022
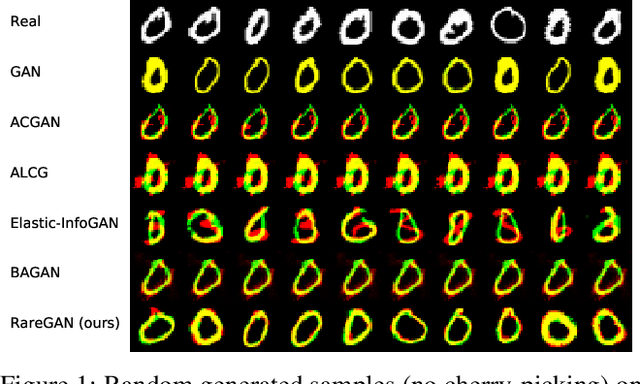


We study the problem of learning generative adversarial networks (GANs) for a rare class of an unlabeled dataset subject to a labeling budget. This problem is motivated from practical applications in domains including security (e.g., synthesizing packets for DNS amplification attacks), systems and networking (e.g., synthesizing workloads that trigger high resource usage), and machine learning (e.g., generating images from a rare class). Existing approaches are unsuitable, either requiring fully-labeled datasets or sacrificing the fidelity of the rare class for that of the common classes. We propose RareGAN, a novel synthesis of three key ideas: (1) extending conditional GANs to use labelled and unlabelled data for better generalization; (2) an active learning approach that requests the most useful labels; and (3) a weighted loss function to favor learning the rare class. We show that RareGAN achieves a better fidelity-diversity tradeoff on the rare class than prior work across different applications, budgets, rare class fractions, GAN losses, and architectures.
Pareto GAN: Extending the Representational Power of GANs to Heavy-Tailed Distributions
Jan 22, 2021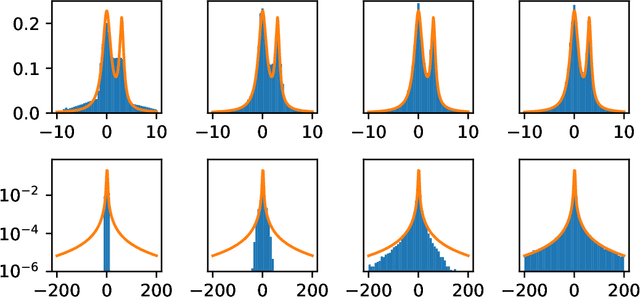
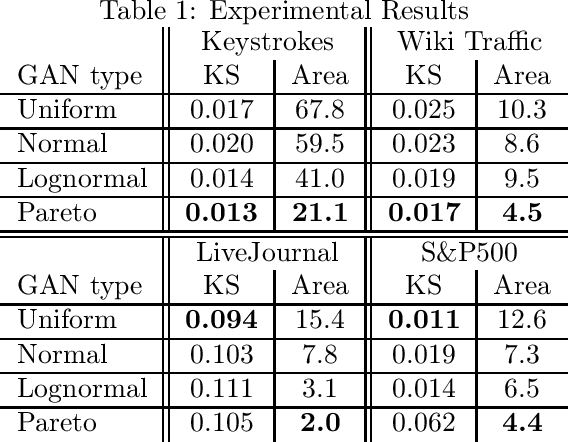
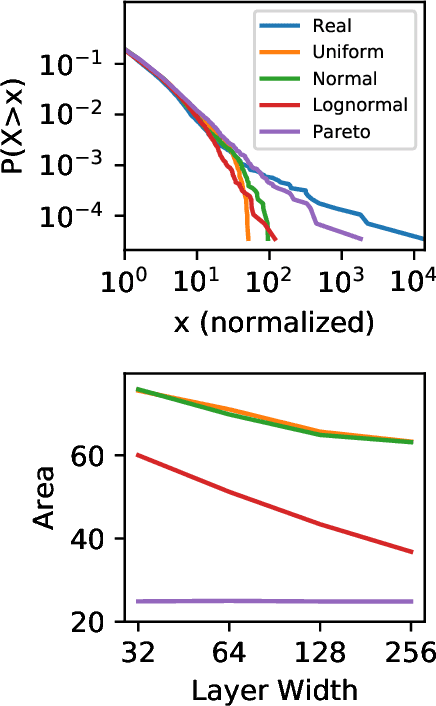
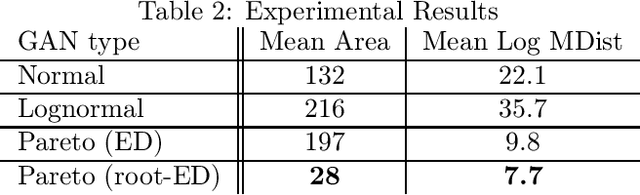
Generative adversarial networks (GANs) are often billed as "universal distribution learners", but precisely what distributions they can represent and learn is still an open question. Heavy-tailed distributions are prevalent in many different domains such as financial risk-assessment, physics, and epidemiology. We observe that existing GAN architectures do a poor job of matching the asymptotic behavior of heavy-tailed distributions, a problem that we show stems from their construction. Additionally, when faced with the infinite moments and large distances between outlier points that are characteristic of heavy-tailed distributions, common loss functions produce unstable or near-zero gradients. We address these problems with the Pareto GAN. A Pareto GAN leverages extreme value theory and the functional properties of neural networks to learn a distribution that matches the asymptotic behavior of the marginal distributions of the features. We identify issues with standard loss functions and propose the use of alternative metric spaces that enable stable and efficient learning. Finally, we evaluate our proposed approach on a variety of heavy-tailed datasets.
Why Spectral Normalization Stabilizes GANs: Analysis and Improvements
Sep 06, 2020
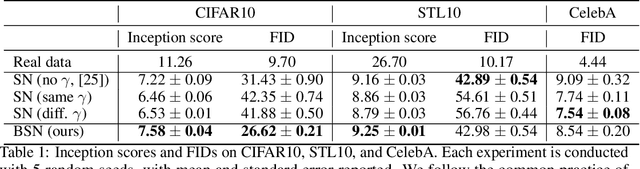
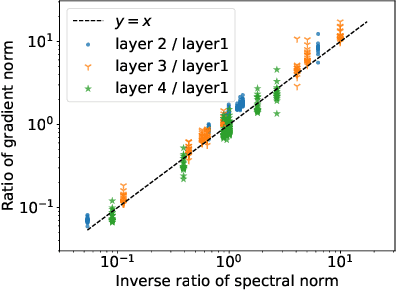
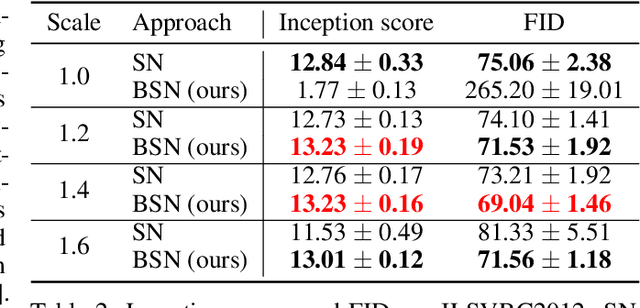
Spectral normalization (SN) is a widely-used technique for improving the stability of Generative Adversarial Networks (GANs) by forcing each layer of the discriminator to have unit spectral norm. This approach controls the Lipschitz constant of the discriminator, and is empirically known to improve sample quality in many GAN architectures. However, there is currently little understanding of why SN is so effective. In this work, we show that SN controls two important failure modes of GAN training: exploding and vanishing gradients. Our proofs illustrate a (perhaps unintentional) connection with the successful LeCun initialization technique, proposed over two decades ago to control gradients in the training of deep neural networks. This connection helps to explain why the most popular implementation of SN for GANs requires no hyperparameter tuning, whereas stricter implementations of SN have poor empirical performance out-of-the-box. Unlike LeCun initialization which only controls gradient vanishing at the beginning of training, we show that SN tends to preserve this property throughout training. Finally, building on this theoretical understanding, we propose Bidirectional Spectral Normalization (BSN), a modification of SN inspired by Xavier initialization, a later improvement to LeCun initialization. Theoretically, we show that BSN gives better gradient control than SN. Empirically, we demonstrate that BSN outperforms SN in sample quality on several benchmark datasets, while also exhibiting better training stability.
Privacy for Free: Communication-Efficient Learning with Differential Privacy Using Sketches
Dec 06, 2019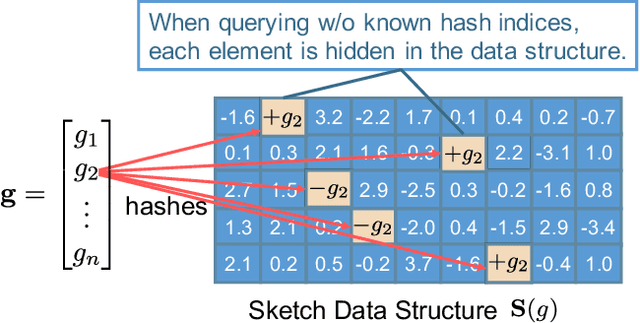

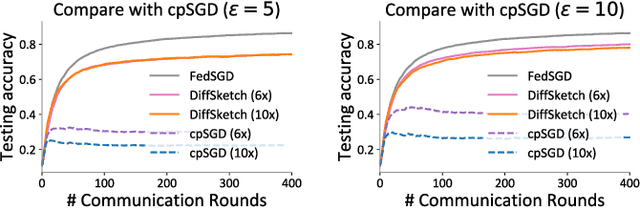
Communication and privacy are two critical concerns in distributed learning. Many existing works treat these concerns separately. In this work, we argue that a natural connection exists between methods for communication reduction and privacy preservation in the context of distributed machine learning. In particular, we prove that Count Sketch, a simple method for data stream summarization, has inherent differential privacy properties. Using these derived privacy guarantees, we propose a novel sketch-based framework (DiffSketch) for distributed learning, where we compress the transmitted messages via sketches to simultaneously achieve communication efficiency and provable privacy benefits. Our evaluation demonstrates that DiffSketch can provide strong differential privacy guarantees (e.g., $\varepsilon$= 1) and reduce communication by 20-50x with only marginal decreases in accuracy. Compared to baselines that treat privacy and communication separately, DiffSketch improves absolute test accuracy by 5%-50% while offering the same privacy guarantees and communication compression.
Enhancing the Privacy of Federated Learning with Sketching
Nov 05, 2019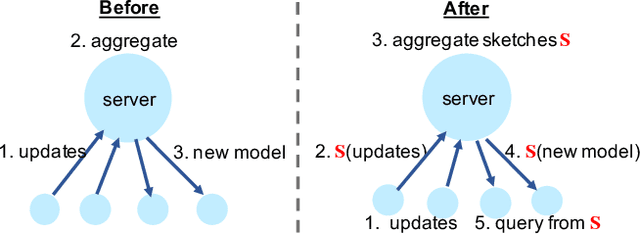
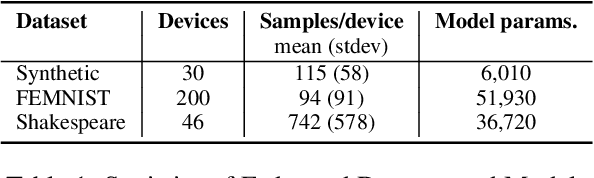
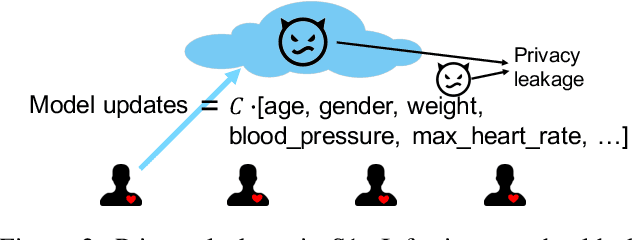
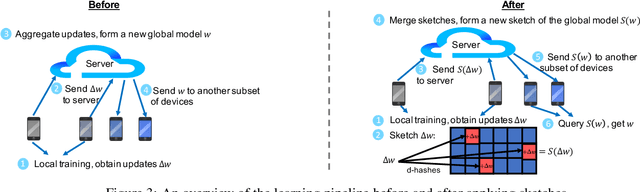
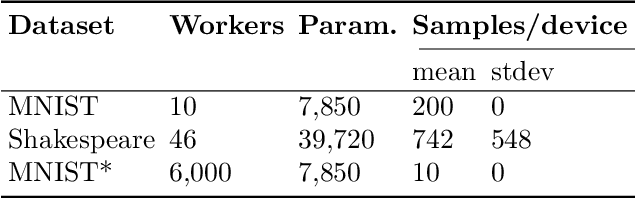
In response to growing concerns about user privacy, federated learning has emerged as a promising tool to train statistical models over networks of devices while keeping data localized. Federated learning methods run training tasks directly on user devices and do not share the raw user data with third parties. However, current methods still share model updates, which may contain private information (e.g., one's weight and height), during the training process. Existing efforts that aim to improve the privacy of federated learning make compromises in one or more of the following key areas: performance (particularly communication cost), accuracy, or privacy. To better optimize these trade-offs, we propose that \textit{sketching algorithms} have a unique advantage in that they can provide both privacy and performance benefits while maintaining accuracy. We evaluate the feasibility of sketching-based federated learning with a prototype on three representative learning models. Our initial findings show that it is possible to provide strong privacy guarantees for federated learning without sacrificing performance or accuracy. Our work highlights that there exists a fundamental connection between privacy and communication in distributed settings, and suggests important open problems surrounding the theoretical understanding, methodology, and system design of practical, private federated learning.
Generating High-fidelity, Synthetic Time Series Datasets with DoppelGANger
Sep 30, 2019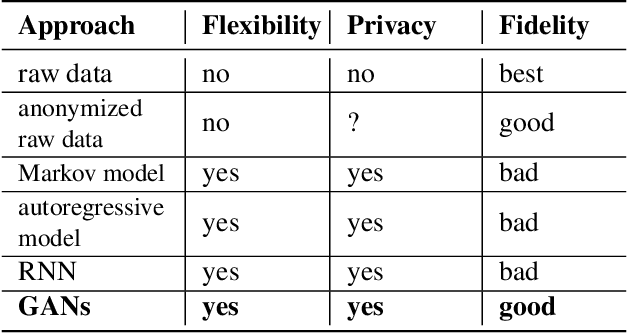
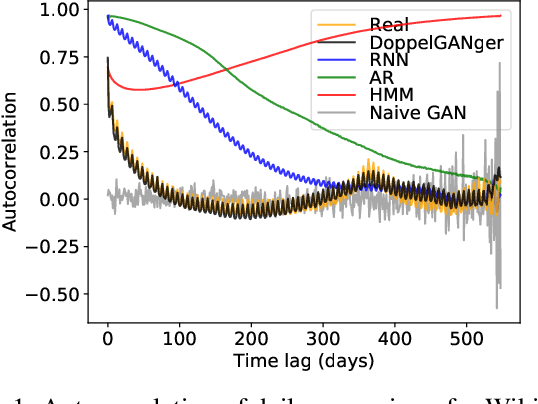
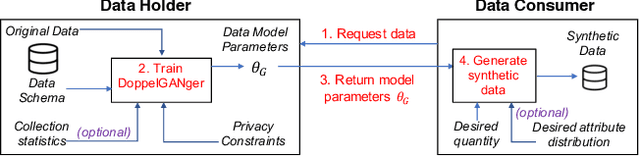
Limited data access is a substantial barrier to data-driven networking research and development. Although many organizations are motivated to share data, privacy concerns often prevent the sharing of proprietary data, including between teams in the same organization and with outside stakeholders (e.g., researchers, vendors). Many researchers have therefore proposed synthetic data models, most of which have not gained traction because of their narrow scope. In this work, we present DoppelGANger, a synthetic data generation framework based on generative adversarial networks (GANs). DoppelGANger is designed to work on time series datasets with both continuous features (e.g. traffic measurements) and discrete ones (e.g., protocol name). Modeling time series and mixed-type data is known to be difficult; DoppelGANger circumvents these problems through a new conditional architecture that isolates the generation of metadata from time series, but uses metadata to strongly influence time series generation. We demonstrate the efficacy of DoppelGANger on three real-world datasets. We show that DoppelGANger achieves up to 43% better fidelity than baseline models, and captures structural properties of data that baseline methods are unable to learn. Additionally, it gives data holders an easy mechanism for protecting attributes of their data without substantial loss of data utility.