 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Feasibility of Using LLMs to Execute Multistage Network Attacks
Jan 27, 2025LLMs have shown preliminary promise in some security tasks and CTF challenges. However, it is unclear whether LLMs are able to realize multistage network attacks, which involve executing a wide variety of actions across multiple hosts such as conducting reconnaissance, exploiting vulnerabilities to gain initial access, leveraging internal hosts to move laterally, and using multiple compromised hosts to exfiltrate data. We evaluate LLMs across 10 multistage networks and find that popular LLMs are unable to realize these attacks. To enable LLMs to realize these attacks, we introduce Incalmo, an LLM-agnostic high-level attack abstraction layer that sits between an LLM and the environment. Rather than LLMs issuing low-level command-line instructions, which can lead to incorrect implementations, Incalmo allows LLMs to specify high-level tasks (e.g., infect a host, scan a network), which are then carried out by Incalmo. Incalmo realizes these tasks by translating them into low-level primitives (e.g., commands to exploit tools). Incalmo also provides an environment state service and an attack graph service to provide structure to LLMs in selecting actions relevant to a multistage attack. Across 9 out of 10 realistic emulated networks (from 25 to 50 hosts), LLMs using Incalmo can successfully autonomously execute multistage attacks. We also conduct an ablation analysis to show the key role the high-level abstractions play. For instance, we find that both Incalmo's high-level tasks and services are crucial. Furthermore, even smaller-parameter LLMs with Incalmo can fully succeed in 5 of 10 environments, while larger-parameter LLMs without Incalmo do not fully succeed in any.
Group-based Robustness: A General Framework for Customized Robustness in the Real World
Jun 29, 2023Machine-learning models are known to be vulnerable to evasion attacks that perturb model inputs to induce misclassifications. In this work, we identify real-world scenarios where the true threat cannot be assessed accurately by existing attacks. Specifically, we find that conventional metrics measuring targeted and untargeted robustness do not appropriately reflect a model's ability to withstand attacks from one set of source classes to another set of target classes. To address the shortcomings of existing methods, we formally define a new metric, termed group-based robustness, that complements existing metrics and is better-suited for evaluating model performance in certain attack scenarios. We show empirically that group-based robustness allows us to distinguish between models' vulnerability against specific threat models in situations where traditional robustness metrics do not apply. Moreover, to measure group-based robustness efficiently and accurately, we 1) propose two loss functions and 2) identify three new attack strategies. We show empirically that with comparable success rates, finding evasive samples using our new loss functions saves computation by a factor as large as the number of targeted classes, and finding evasive samples using our new attack strategies saves time by up to 99\% compared to brute-force search methods. Finally, we propose a defense method that increases group-based robustness by up to 3.52$\times$.
Randomness in ML Defenses Helps Persistent Attackers and Hinders Evaluators
Feb 27, 2023It is becoming increasingly imperative to design robust ML defenses. However, recent work has found that many defenses that initially resist state-of-the-art attacks can be broken by an adaptive adversary. In this work we take steps to simplify the design of defenses and argue that white-box defenses should eschew randomness when possible. We begin by illustrating a new issue with the deployment of randomized defenses that reduces their security compared to their deterministic counterparts. We then provide evidence that making defenses deterministic simplifies robustness evaluation, without reducing the effectiveness of a truly robust defense. Finally, we introduce a new defense evaluation framework that leverages a defense's deterministic nature to better evaluate its adversarial robustness.
Certified Robustness of Learning-based Static Malware Detectors
Jan 31, 2023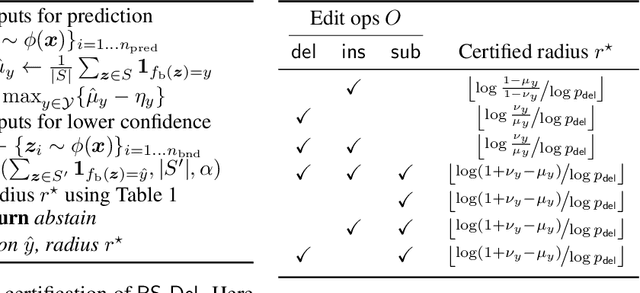


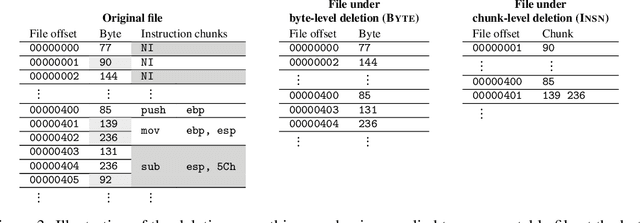
Certified defenses are a recent development in adversarial machine learning (ML), which aim to rigorously guarantee the robustness of ML models to adversarial perturbations. A large body of work studies certified defenses in computer vision, where $\ell_p$ norm-bounded evasion attacks are adopted as a tractable threat model. However, this threat model has known limitations in vision, and is not applicable to other domains -- e.g., where inputs may be discrete or subject to complex constraints. Motivated by this gap, we study certified defenses for malware detection, a domain where attacks against ML-based systems are a real and current threat. We consider static malware detection systems that operate on byte-level data. Our certified defense is based on the approach of randomized smoothing which we adapt by: (1) replacing the standard Gaussian randomization scheme with a novel deletion randomization scheme that operates on bytes or chunks of an executable; and (2) deriving a certificate that measures robustness to evasion attacks in terms of generalized edit distance. To assess the size of robustness certificates that are achievable while maintaining high accuracy, we conduct experiments on malware datasets using a popular convolutional malware detection model, MalConv. We are able to accurately classify 91% of the inputs while being certifiably robust to any adversarial perturbations of edit distance 128 bytes or less. By comparison, an existing certification of up to 128 bytes of substitutions (without insertions or deletions) achieves an accuracy of 78%. In addition, given that robustness certificates are conservative, we evaluate practical robustness to several recently published evasion attacks and, in some cases, find robustness beyond certified guarantees.
Any-Play: An Intrinsic Augmentation for Zero-Shot Coordination
Jan 28, 2022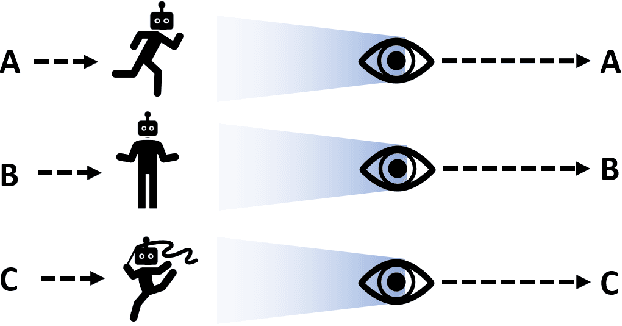
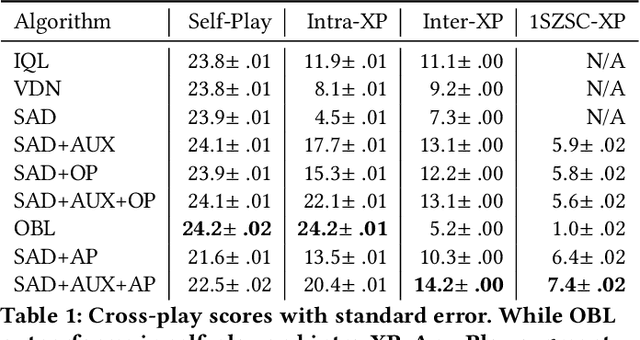
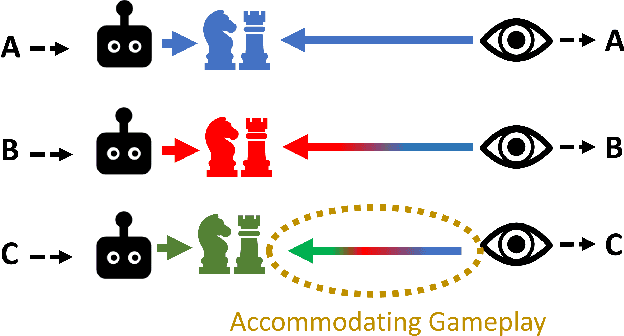
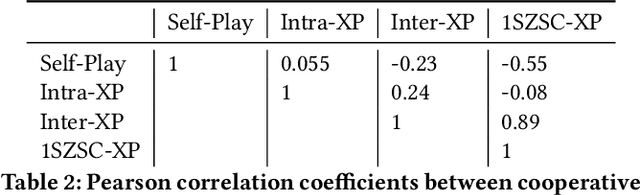
Cooperative artificial intelligence with human or superhuman proficiency in collaborative tasks stands at the frontier of machine learning research. Prior work has tended to evaluate cooperative AI performance under the restrictive paradigms of self-play (teams composed of agents trained together) and cross-play (teams of agents trained independently but using the same algorithm). Recent work has indicated that AI optimized for these narrow settings may make for undesirable collaborators in the real-world. We formalize an alternative criteria for evaluating cooperative AI, referred to as inter-algorithm cross-play, where agents are evaluated on teaming performance with all other agents within an experiment pool with no assumption of algorithmic similarities between agents. We show that existing state-of-the-art cooperative AI algorithms, such as Other-Play and Off-Belief Learning, under-perform in this paradigm. We propose the Any-Play learning augmentation -- a multi-agent extension of diversity-based intrinsic rewards for zero-shot coordination (ZSC) -- for generalizing self-play-based algorithms to the inter-algorithm cross-play setting. We apply the Any-Play learning augmentation to the Simplified Action Decoder (SAD) and demonstrate state-of-the-art performance in the collaborative card game Hanabi.
Constrained Gradient Descent: A Powerful and Principled Evasion Attack Against Neural Networks
Dec 28, 2021
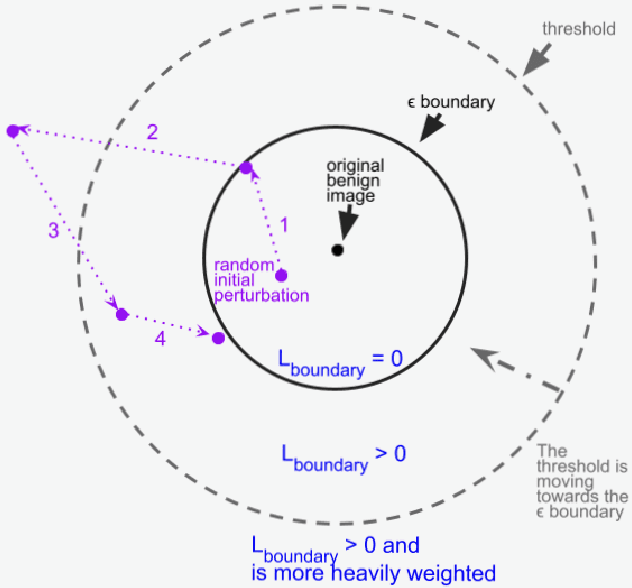
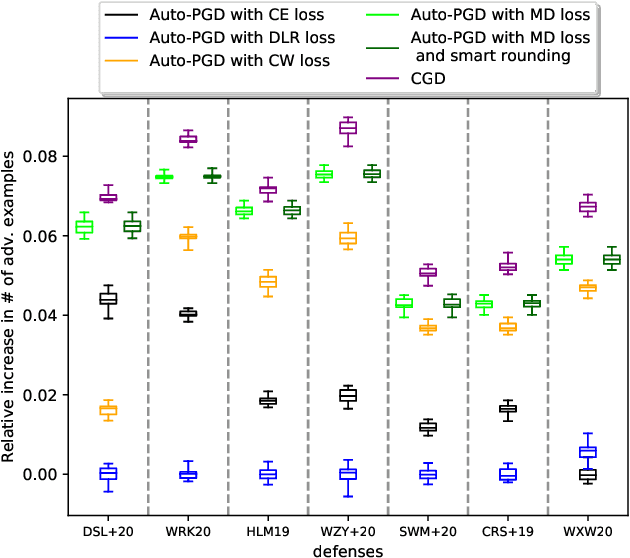
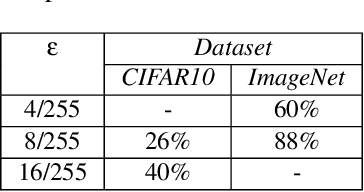
Minimal adversarial perturbations added to inputs have been shown to be effective at fooling deep neural networks. In this paper, we introduce several innovations that make white-box targeted attacks follow the intuition of the attacker's goal: to trick the model to assign a higher probability to the target class than to any other, while staying within a specified distance from the original input. First, we propose a new loss function that explicitly captures the goal of targeted attacks, in particular, by using the logits of all classes instead of just a subset, as is common. We show that Auto-PGD with this loss function finds more adversarial examples than it does with other commonly used loss functions. Second, we propose a new attack method that uses a further developed version of our loss function capturing both the misclassification objective and the $L_{\infty}$ distance limit $\epsilon$. This new attack method is relatively 1.5--4.2% more successful on the CIFAR10 dataset and relatively 8.2--14.9% more successful on the ImageNet dataset, than the next best state-of-the-art attack. We confirm using statistical tests that our attack outperforms state-of-the-art attacks on different datasets and values of $\epsilon$ and against different defenses.
Optimization-Guided Binary Diversification to Mislead Neural Networks for Malware Detection
Dec 19, 2019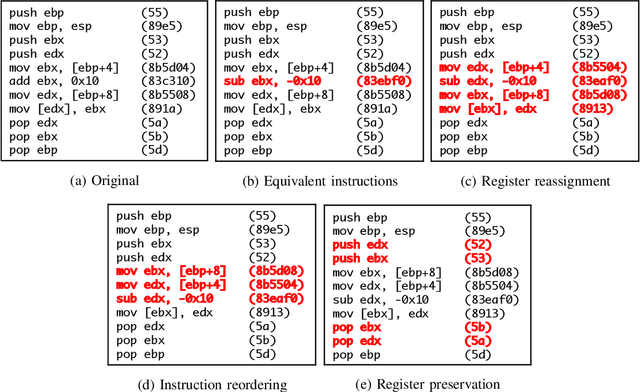

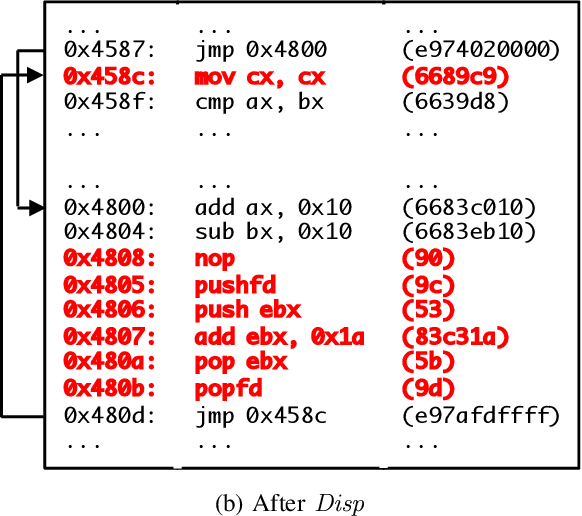
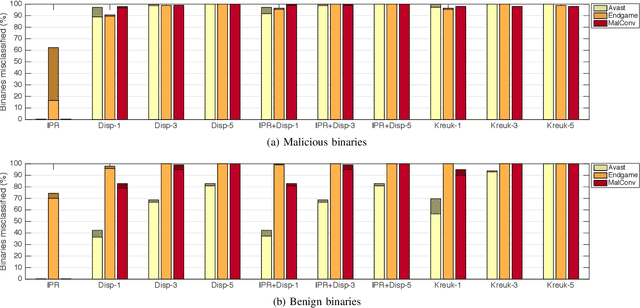
Motivated by the transformative impact of deep neural networks (DNNs) on different areas (e.g., image and speech recognition), researchers and anti-virus vendors are proposing end-to-end DNNs for malware detection from raw bytes that do not require manual feature engineering. Given the security sensitivity of the task that these DNNs aim to solve, it is important to assess their susceptibility to evasion. In this work, we propose an attack that guides binary-diversification tools via optimization to mislead DNNs for malware detection while preserving the functionality of binaries. Unlike previous attacks on such DNNs, ours manipulates instructions that are a functional part of the binary, which makes it particularly challenging to defend against. We evaluated our attack against three DNNs in white-box and black-box settings, and found that it can often achieve success rates near 100%. Moreover, we found that our attack can fool some commercial anti-viruses, in certain cases with a success rate of 85%. We explored several defenses, both new and old, and identified some that can successfully prevent over 80% of our evasion attempts. However, these defenses may still be susceptible to evasion by adaptive attackers, and so we advocate for augmenting malware-detection systems with methods that do not rely on machine learning.