 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization-Guided Binary Diversification to Mislead Neural Networks for Malware Detection
Dec 19, 2019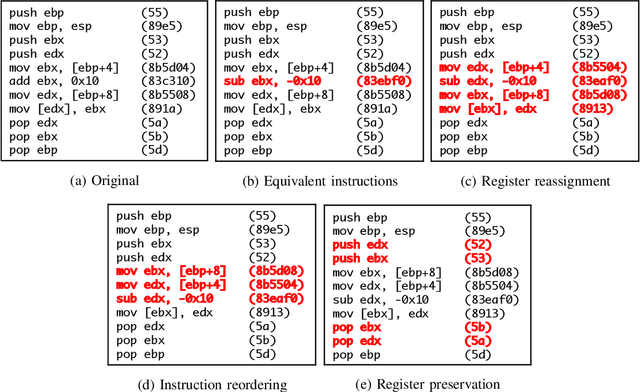

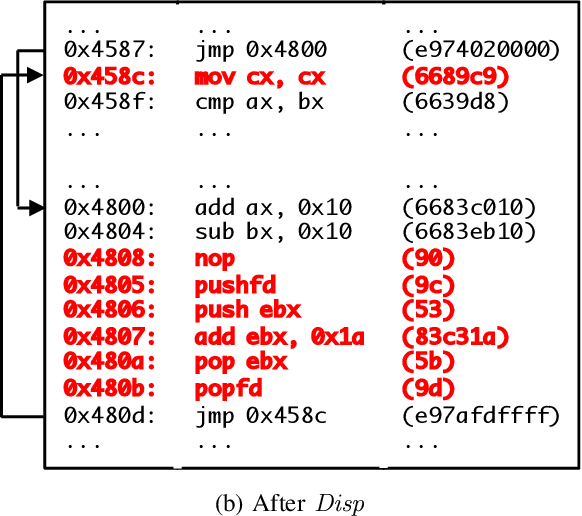
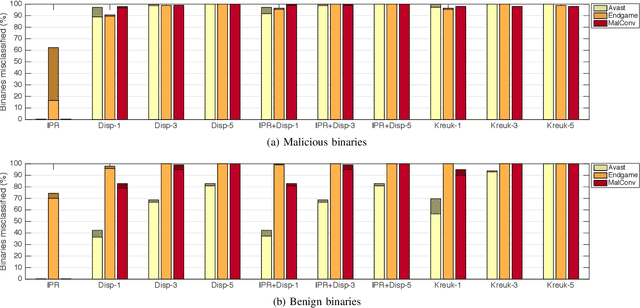
Motivated by the transformative impact of deep neural networks (DNNs) on different areas (e.g., image and speech recognition), researchers and anti-virus vendors are proposing end-to-end DNNs for malware detection from raw bytes that do not require manual feature engineering. Given the security sensitivity of the task that these DNNs aim to solve, it is important to assess their susceptibility to evasion. In this work, we propose an attack that guides binary-diversification tools via optimization to mislead DNNs for malware detection while preserving the functionality of binaries. Unlike previous attacks on such DNNs, ours manipulates instructions that are a functional part of the binary, which makes it particularly challenging to defend against. We evaluated our attack against three DNNs in white-box and black-box settings, and found that it can often achieve success rates near 100%. Moreover, we found that our attack can fool some commercial anti-viruses, in certain cases with a success rate of 85%. We explored several defenses, both new and old, and identified some that can successfully prevent over 80% of our evasion attempts. However, these defenses may still be susceptible to evasion by adaptive attackers, and so we advocate for augmenting malware-detection systems with methods that do not rely on machine learning.
Deep Detector Health Management under Adversarial Campaigns
Nov 19, 2019
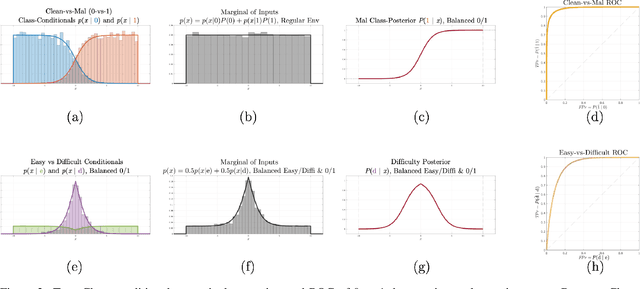
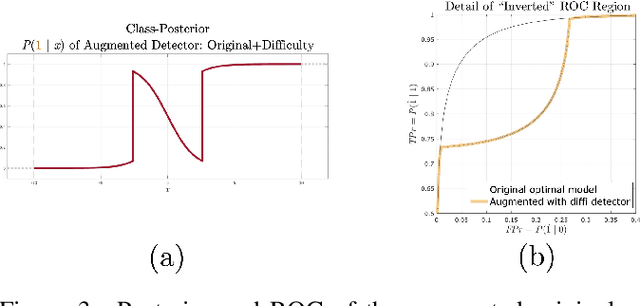
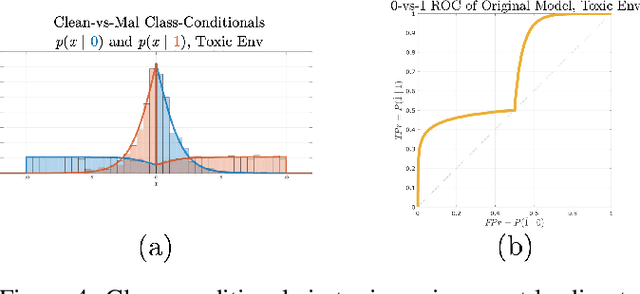
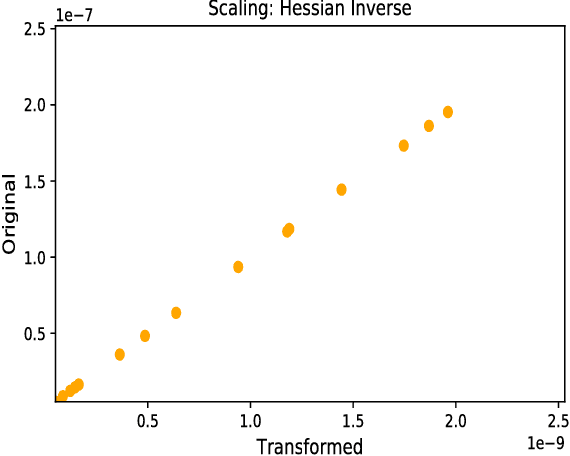
Machine learning models are vulnerable to adversarial inputs that induce seemingly unjustifiable errors. As automated classifiers are increasingly used in industrial control systems and machinery, these adversarial errors could grow to be a serious problem. Despite numerous studies over the past few years, the field of adversarial ML is still considered alchemy, with no practical unbroken defenses demonstrated to date, leaving PHM practitioners with few meaningful ways of addressing the problem. We introduce turbidity detection as a practical superset of the adversarial input detection problem, coping with adversarial campaigns rather than statistically invisible one-offs. This perspective is coupled with ROC-theoretic design guidance that prescribes an inexpensive domain adaptation layer at the output of a deep learning model during an attack campaign. The result aims to approximate the Bayes optimal mitigation that ameliorates the detection model's degraded health. A proactively reactive type of prognostics is achieved via Monte Carlo simulation of various adversarial campaign scenarios, by sampling from the model's own turbidity distribution to quickly deploy the correct mitigation during a real-world campaign.
Gradient Similarity: An Explainable Approach to Detect Adversarial Attacks against Deep Learning
Jun 27, 2018

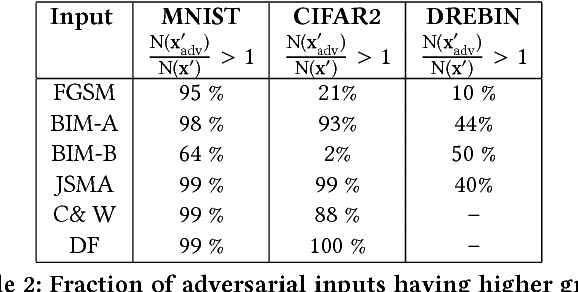
Deep neural networks are susceptible to small-but-specific adversarial perturbations capable of deceiving the network. This vulnerability can lead to potentially harmful consequences in security-critical applications. To address this vulnerability, we propose a novel metric called \emph{Gradient Similarity} that allows us to capture the influence of training data on test inputs. We show that \emph{Gradient Similarity} behaves differently for normal and adversarial inputs, and enables us to detect a variety of adversarial attacks with a near perfect ROC-AUC of 95-100\%. Even white-box adversaries equipped with perfect knowledge of the system cannot bypass our detector easily. On the MNIST dataset, white-box attacks are either detected with a high ROC-AUC of 87-96\%, or require very high distortion to bypass our detector.
Detecting Adversarial Samples from Artifacts
Nov 15, 2017


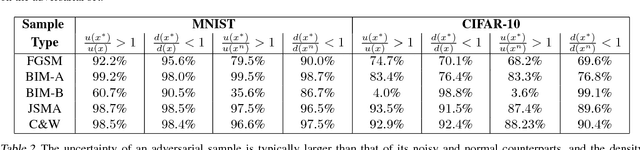
Deep neural networks (DNNs) are powerful nonlinear architectures that are known to be robust to random perturbations of the input. However, these models are vulnerable to adversarial perturbations--small input changes crafted explicitly to fool the model. In this paper, we ask whether a DNN can distinguish adversarial samples from their normal and noisy counterparts. We investigate model confidence on adversarial samples by looking at Bayesian uncertainty estimates, available in dropout neural networks, and by performing density estimation in the subspace of deep features learned by the model. The result is a method for implicit adversarial detection that is oblivious to the attack algorithm. We evaluate this method on a variety of standard datasets including MNIST and CIFAR-10 and show that it generalizes well across different architectures and attacks. Our findings report that 85-93% ROC-AUC can be achieved on a number of standard classification tasks with a negative class that consists of both normal and noisy samples.