 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDVERGE: Diversifying Vulnerabilities for Enhanced Robust Generation of Ensembles
Oct 18, 2020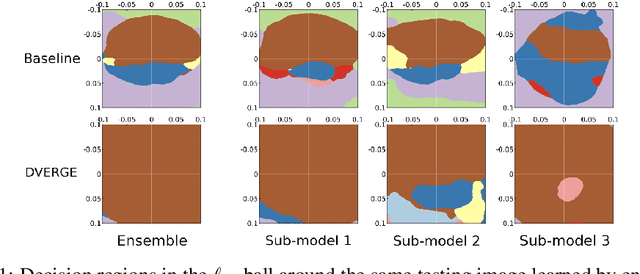

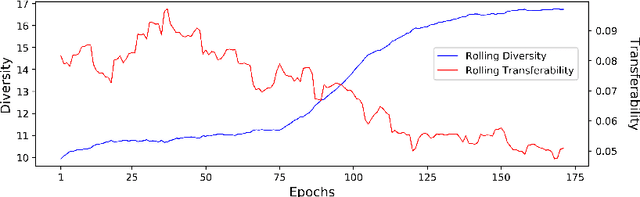

Recent research finds CNN models for image classification demonstrate overlapped adversarial vulnerabilities: adversarial attacks can mislead CNN models with small perturbations, which can effectively transfer between different models trained on the same dataset. Adversarial training, as a general robustness improvement technique, eliminates the vulnerability in a single model by forcing it to learn robust features. The process is hard, often requires models with large capacity, and suffers from significant loss on clean data accuracy. Alternatively, ensemble methods are proposed to induce sub-models with diverse outputs against a transfer adversarial example, making the ensemble robust against transfer attacks even if each sub-model is individually non-robust. Only small clean accuracy drop is observed in the process. However, previous ensemble training methods are not efficacious in inducing such diversity and thus ineffective on reaching robust ensemble. We propose DVERGE, which isolates the adversarial vulnerability in each sub-model by distilling non-robust features, and diversifies the adversarial vulnerability to induce diverse outputs against a transfer attack. The novel diversity metric and training procedure enables DVERGE to achieve higher robustness against transfer attacks comparing to previous ensemble methods, and enables the improved robustness when more sub-models are added to the ensemble. The code of this work is available at https://github.com/zjysteven/DVERGE
Deep Detector Health Management under Adversarial Campaigns
Nov 19, 2019
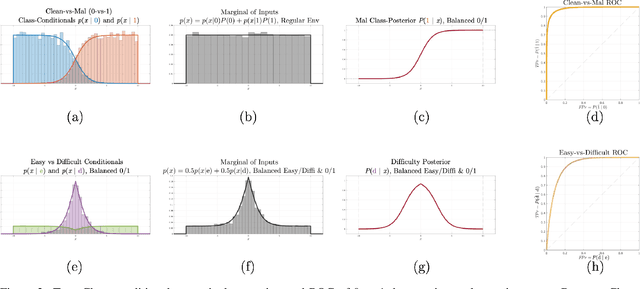
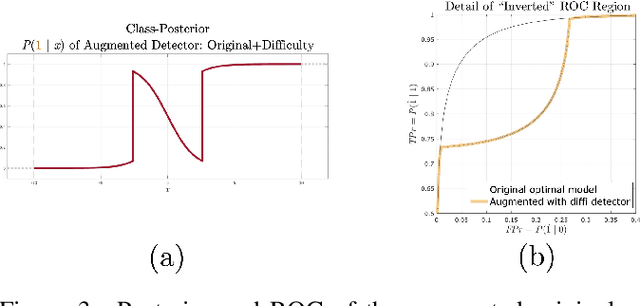
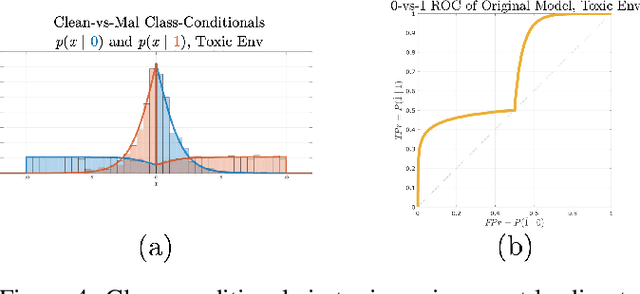
Machine learning models are vulnerable to adversarial inputs that induce seemingly unjustifiable errors. As automated classifiers are increasingly used in industrial control systems and machinery, these adversarial errors could grow to be a serious problem. Despite numerous studies over the past few years, the field of adversarial ML is still considered alchemy, with no practical unbroken defenses demonstrated to date, leaving PHM practitioners with few meaningful ways of addressing the problem. We introduce turbidity detection as a practical superset of the adversarial input detection problem, coping with adversarial campaigns rather than statistically invisible one-offs. This perspective is coupled with ROC-theoretic design guidance that prescribes an inexpensive domain adaptation layer at the output of a deep learning model during an attack campaign. The result aims to approximate the Bayes optimal mitigation that ameliorates the detection model's degraded health. A proactively reactive type of prognostics is achieved via Monte Carlo simulation of various adversarial campaign scenarios, by sampling from the model's own turbidity distribution to quickly deploy the correct mitigation during a real-world campaign.
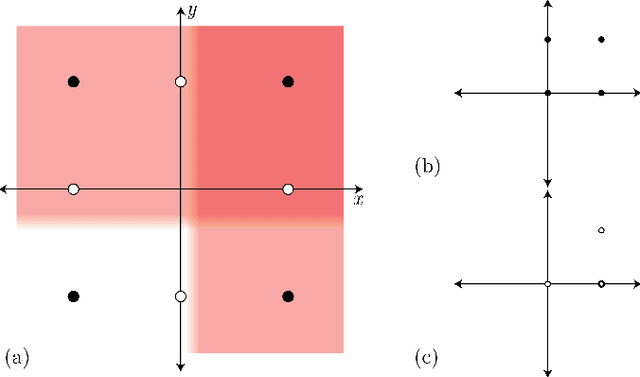
On the Definiteness of Earth Mover's Distance and Its Relation to Set Intersection
Aug 21, 2018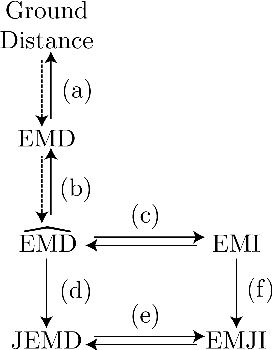
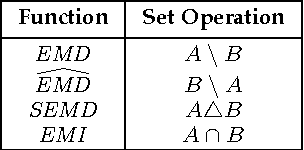
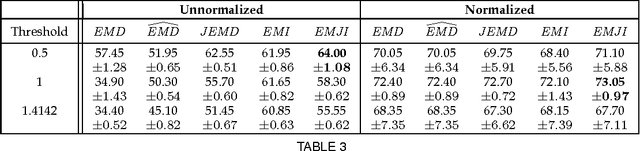
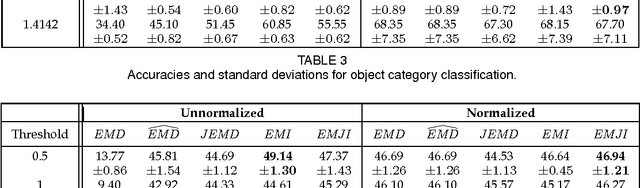
Positive definite kernels are an important tool in machine learning that enable efficient solutions to otherwise difficult or intractable problems by implicitly linearizing the problem geometry. In this paper we develop a set-theoretic interpretation of the Earth Mover's Distance (EMD) and propose Earth Mover's Intersection (EMI), a positive definite analog to EMD for sets of different sizes. We provide conditions under which EMD or certain approximations to EMD are negative definite. We also present a positive-definite-preserving transformation that can be applied to any kernel and can also be used to derive positive definite EMD-based kernels and show that the Jaccard index is simply the result of this transformation. Finally, we evaluate kernels based on EMI and the proposed transformation versus EMD in various computer vision tasks and show that EMD is generally inferior even with indefinite kernel techniques.
Classifying Unordered Feature Sets with Convolutional Deep Averaging Networks
Sep 10, 2017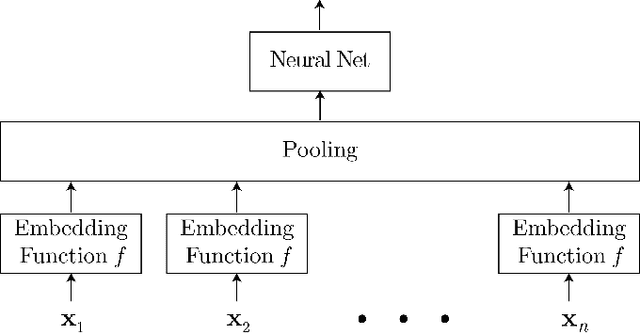
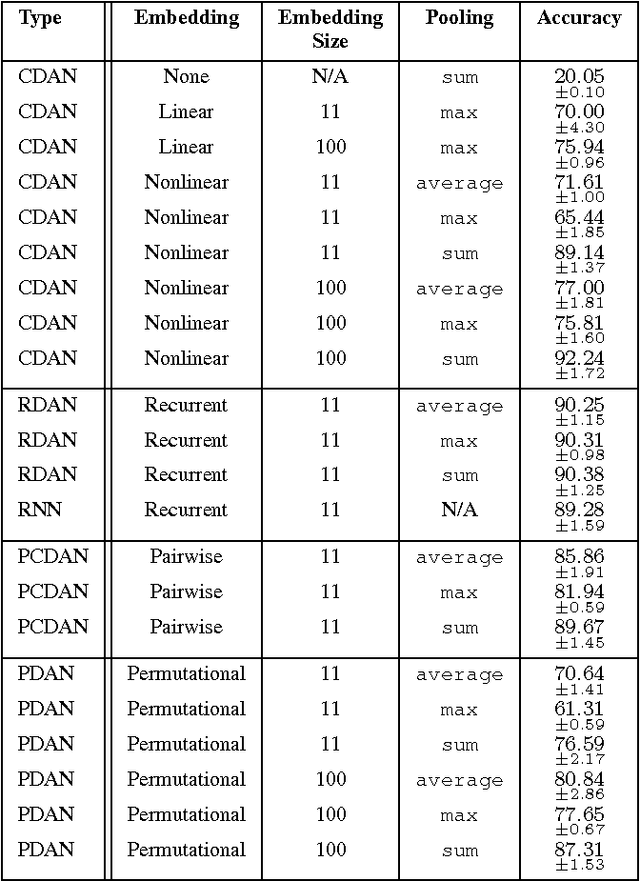
Unordered feature sets are a nonstandard data structure that traditional neural networks are incapable of addressing in a principled manner. Providing a concatenation of features in an arbitrary order may lead to the learning of spurious patterns or biases that do not actually exist. Another complication is introduced if the number of features varies between each set. We propose convolutional deep averaging networks (CDANs) for classifying and learning representations of datasets whose instances comprise variable-size, unordered feature sets. CDANs are efficient, permutation-invariant, and capable of accepting sets of arbitrary size. We emphasize the importance of nonlinear feature embeddings for obtaining effective CDAN classifiers and illustrate their advantages in experiments versus linear embeddings and alternative permutation-invariant and -equivariant architectures.