 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Detector Health Management under Adversarial Campaigns
Nov 19, 2019
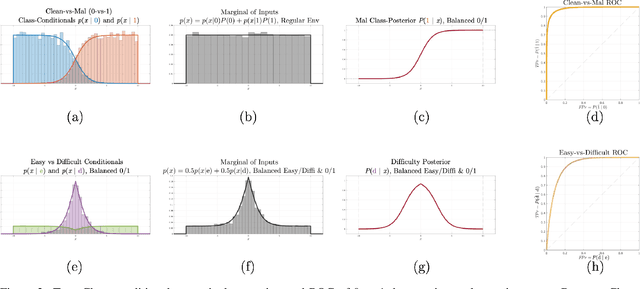
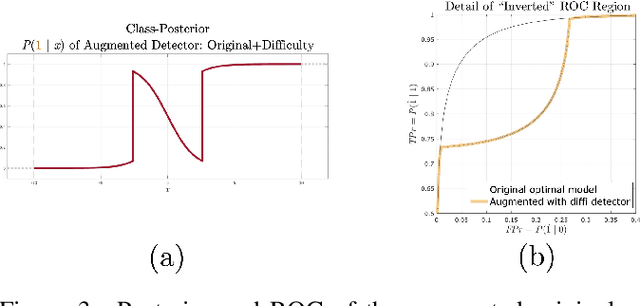
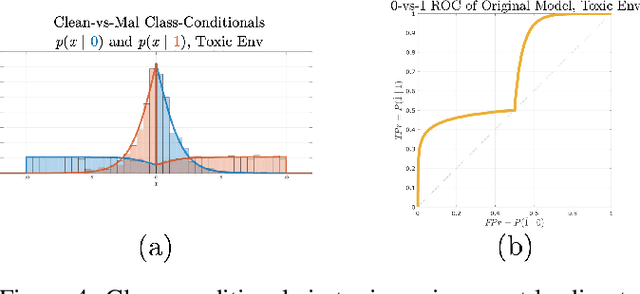
Machine learning models are vulnerable to adversarial inputs that induce seemingly unjustifiable errors. As automated classifiers are increasingly used in industrial control systems and machinery, these adversarial errors could grow to be a serious problem. Despite numerous studies over the past few years, the field of adversarial ML is still considered alchemy, with no practical unbroken defenses demonstrated to date, leaving PHM practitioners with few meaningful ways of addressing the problem. We introduce turbidity detection as a practical superset of the adversarial input detection problem, coping with adversarial campaigns rather than statistically invisible one-offs. This perspective is coupled with ROC-theoretic design guidance that prescribes an inexpensive domain adaptation layer at the output of a deep learning model during an attack campaign. The result aims to approximate the Bayes optimal mitigation that ameliorates the detection model's degraded health. A proactively reactive type of prognostics is achieved via Monte Carlo simulation of various adversarial campaign scenarios, by sampling from the model's own turbidity distribution to quickly deploy the correct mitigation during a real-world campaign.