 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZipf-Gramming: Scaling Byte N-Grams Up to Production Sized Malware Corpora
Nov 17, 2025A classifier using byte n-grams as features is the only approach we have found fast enough to meet requirements in size (sub 2 MB), speed (multiple GB/s), and latency (sub 10 ms) for deployment in numerous malware detection scenarios. However, we've consistently found that 6-8 grams achieve the best accuracy on our production deployments but have been unable to deploy regularly updated models due to the high cost of finding the top-k most frequent n-grams over terabytes of executable programs. Because the Zipfian distribution well models the distribution of n-grams, we exploit its properties to develop a new top-k n-gram extractor that is up to $35\times$ faster than the previous best alternative. Using our new Zipf-Gramming algorithm, we are able to scale up our production training set and obtain up to 30\% improvement in AUC at detecting new malware. We show theoretically and empirically that our approach will select the top-k items with little error and the interplay between theory and engineering required to achieve these results.
* Published in CIKM 2025
High-Dimensional Distributed Sparse Classification with Scalable Communication-Efficient Global Updates
Jul 08, 2024



As the size of datasets used in statistical learning continues to grow, distributed training of models has attracted increasing attention. These methods partition the data and exploit parallelism to reduce memory and runtime, but suffer increasingly from communication costs as the data size or the number of iterations grows. Recent work on linear models has shown that a surrogate likelihood can be optimized locally to iteratively improve on an initial solution in a communication-efficient manner. However, existing versions of these methods experience multiple shortcomings as the data size becomes massive, including diverging updates and efficiently handling sparsity. In this work we develop solutions to these problems which enable us to learn a communication-efficient distributed logistic regression model even beyond millions of features. In our experiments we demonstrate a large improvement in accuracy over distributed algorithms with only a few distributed update steps needed, and similar or faster runtimes. Our code is available at \url{https://github.com/FutureComputing4AI/ProxCSL}.
Optimizing the Optimal Weighted Average: Efficient Distributed Sparse Classification
Jun 03, 2024While distributed training is often viewed as a solution to optimizing linear models on increasingly large datasets, inter-machine communication costs of popular distributed approaches can dominate as data dimensionality increases. Recent work on non-interactive algorithms shows that approximate solutions for linear models can be obtained efficiently with only a single round of communication among machines. However, this approximation often degenerates as the number of machines increases. In this paper, building on the recent optimal weighted average method, we introduce a new technique, ACOWA, that allows an extra round of communication to achieve noticeably better approximation quality with minor runtime increases. Results show that for sparse distributed logistic regression, ACOWA obtains solutions that are more faithful to the empirical risk minimizer and attain substantially higher accuracy than other distributed algorithms.
Flexible numerical optimization with ensmallen
Mar 23, 2020



This report provides an introduction to the ensmallen numerical optimization library, as well as a deep dive into the technical details of how it works. The library provides a fast and flexible C++ framework for mathematical optimization of arbitrary user-supplied functions. A large set of pre-built optimizers is provided, including many variants of Stochastic Gradient Descent and Quasi-Newton optimizers. Several types of objective functions are supported, including differentiable, separable, constrained, and categorical objective functions. Implementation of a new optimizer requires only one method, while a new objective function requires typically only one or two C++ methods. Through internal use of C++ template metaprogramming, ensmallen provides support for arbitrary user-supplied callbacks and automatic inference of unsupplied methods without any runtime overhead. Empirical comparisons show that ensmallen outperforms other optimization frameworks (such as Julia and SciPy), sometimes by large margins. The library is available at https://ensmallen.org and is distributed under the permissive BSD license.
On Coresets for Regularized Loss Minimization
May 31, 2019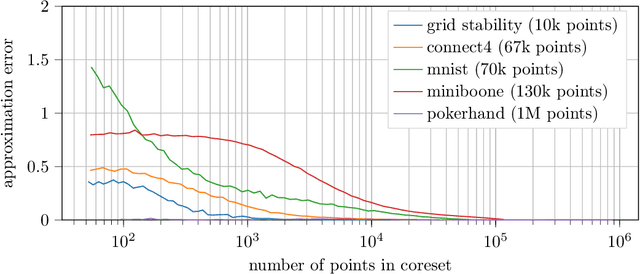

We design and mathematically analyze sampling-based algorithms for regularized loss minimization problems that are implementable in popular computational models for large data, in which the access to the data is restricted in some way. Our main result is that if the regularizer's effect does not become negligible as the norm of the hypothesis scales, and as the data scales, then a uniform sample of modest size is with high probability a coreset. In the case that the loss function is either logistic regression or soft-margin support vector machines, and the regularizer is one of the common recommended choices, this result implies that a uniform sample of size $O(d \sqrt{n})$ is with high probability a coreset of $n$ points in $\Re^d$. We contrast this upper bound with two lower bounds. The first lower bound shows that our analysis of uniform sampling is tight; that is, a smaller uniform sample will likely not be a core set. The second lower bound shows that in some sense uniform sampling is close to optimal, as significantly smaller core sets do not generally exist.
On Functional Aggregate Queries with Additive Inequalities
Dec 22, 2018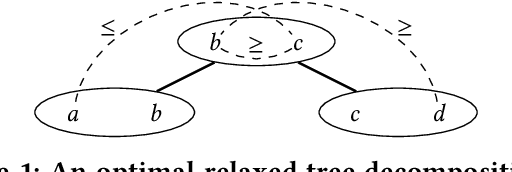
Motivated by fundamental applications in databases and relational machine learning, we formulate and study the problem of answering Functional Aggregate Queries (FAQ) in which some of the input factors are defined by a collection of Additive Inequalities between variables. We refer to these queries as FAQ-AI for short. To answer FAQ-AI in the Boolean semiring, we define "relaxed" tree decompositions and "relaxed" submodular and fractional hypertree width parameters. We show that an extension of the InsideOut algorithm using Chazelle's geometric data structure for solving the semigroup range search problem can answer Boolean FAQ-AI in time given by these new width parameters. This new algorithm achieves lower complexity than known solutions for FAQ-AI. It also recovers some known results in database query answering. Our second contribution is a relaxation of the set of polymatroids that gives rise to the counting version of the submodular width, denoted by "#subw". This new width is sandwiched between the submodular and the fractional hypertree widths. Any FAQ and FAQ-AI over one semiring can be answered in time proportional to #subw and respectively to the relaxed version of #subw. We present three applications of our FAQ-AI framework to relational machine learning: k-means clustering, training linear support vector machines, and training models using non-polynomial loss. These optimization problems can be solved over a database asymptotically faster than computing the join of the database relations.
ensmallen: a flexible C++ library for efficient function optimization
Oct 22, 2018

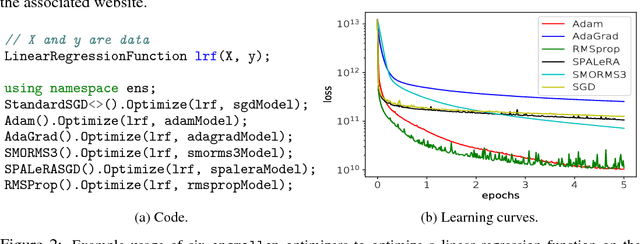

We present ensmallen, a fast and flexible C++ library for mathematical optimization of arbitrary user-supplied functions, which can be applied to many machine learning problems. Several types of optimizations are supported, including differentiable, separable, constrained, and categorical objective functions. The library provides many pre-built optimizers (including numerous variants of SGD and Quasi-Newton optimizers) as well as a flexible framework for implementing new optimizers and objective functions. Implementation of a new optimizer requires only one method and a new objective function requires typically one or two C++ functions. This can aid in the quick implementation and prototyping of new machine learning algorithms. Due to the use of C++ template metaprogramming, ensmallen is able to support compiler optimizations that provide fast runtimes. Empirical comparisons show that ensmallen is able to outperform other optimization frameworks (like Julia and SciPy), sometimes by large margins. The library is distributed under the BSD license and is ready for use in production environments.
Detecting DGA domains with recurrent neural networks and side information
Oct 04, 2018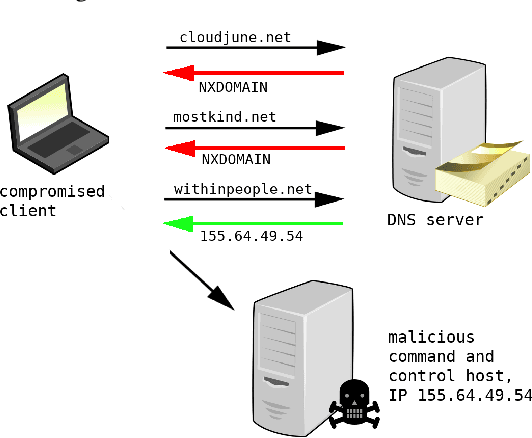
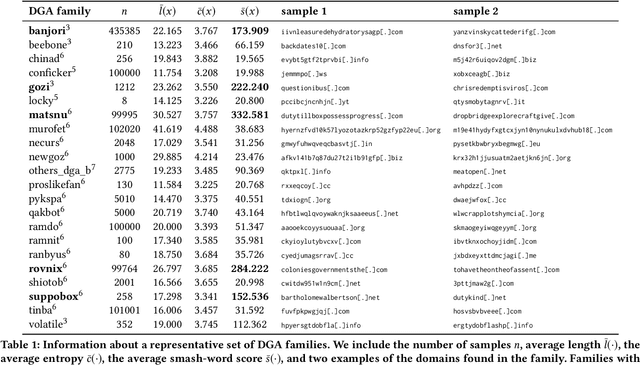
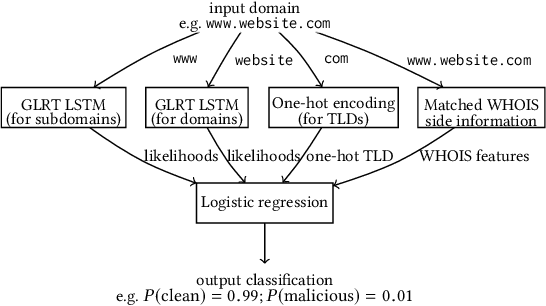

Modern malware typically makes use of a domain generation algorithm (DGA) to avoid command and control domains or IPs being seized or sinkholed. This means that an infected system may attempt to access many domains in an attempt to contact the command and control server. Therefore, the automatic detection of DGA domains is an important task, both for the sake of blocking malicious domains and identifying compromised hosts. However, many DGAs use English wordlists to generate plausibly clean-looking domain names; this makes automatic detection difficult. In this work, we devise a notion of difficulty for DGA families called the smashword score; this measures how much a DGA family looks like English words. We find that this measure accurately reflects how much a DGA family's domains look like they are made from natural English words. We then describe our new modeling approach, which is a combination of a novel recurrent neural network architecture with domain registration side information. Our experiments show the model is capable of effectively identifying domains generated by difficult DGA families. Our experiments also show that our model outperforms existing approaches, and is able to reliably detect difficult DGA families such as matsnu, suppobox, rovnix, and others. The model's performance compared to the state of the art is best for DGA families that resemble English words. We believe that this model could either be used in a standalone DGA domain detector---such as an endpoint security application---or alternately the model could be used as a part of a larger malware detection system.
A generic and fast C++ optimization framework
Nov 17, 2017
The development of the mlpack C++ machine learning library (http://www.mlpack.org/) has required the design and implementation of a flexible, robust optimization system that is able to solve the types of arbitrary optimization problems that may arise all throughout machine learning problems. In this paper, we present the generic optimization framework that we have designed for mlpack. A key priority in the design was ease of implementation of both new optimizers and new objective functions to be optimized; therefore, implementation of a new optimizer requires only one method and implementation of a new objective function requires at most four functions. This leads to simple and intuitive code, which, for fast prototyping and experimentation, is of paramount importance. When compared to optimization frameworks of other libraries, we find that mlpack's supports more types of objective functions, is able to make optimizations that other frameworks do not, and seamlessly supports user-defined objective functions and optimizers.
Detecting Adversarial Samples from Artifacts
Nov 15, 2017


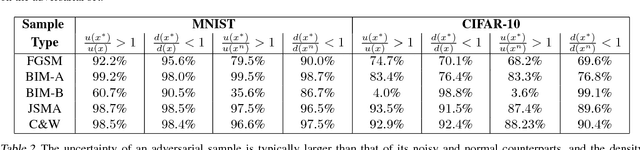
Deep neural networks (DNNs) are powerful nonlinear architectures that are known to be robust to random perturbations of the input. However, these models are vulnerable to adversarial perturbations--small input changes crafted explicitly to fool the model. In this paper, we ask whether a DNN can distinguish adversarial samples from their normal and noisy counterparts. We investigate model confidence on adversarial samples by looking at Bayesian uncertainty estimates, available in dropout neural networks, and by performing density estimation in the subspace of deep features learned by the model. The result is a method for implicit adversarial detection that is oblivious to the attack algorithm. We evaluate this method on a variety of standard datasets including MNIST and CIFAR-10 and show that it generalizes well across different architectures and attacks. Our findings report that 85-93% ROC-AUC can be achieved on a number of standard classification tasks with a negative class that consists of both normal and noisy samples.