 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting DGA domains with recurrent neural networks and side information
Oct 04, 2018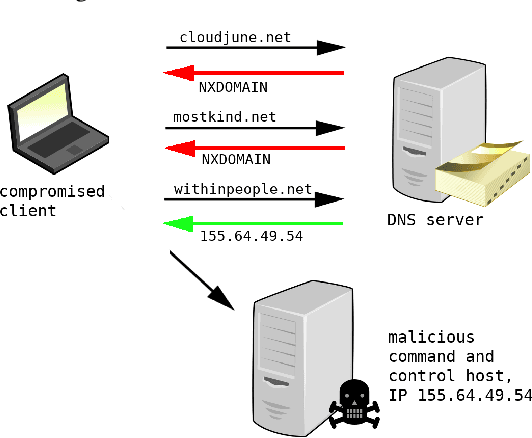
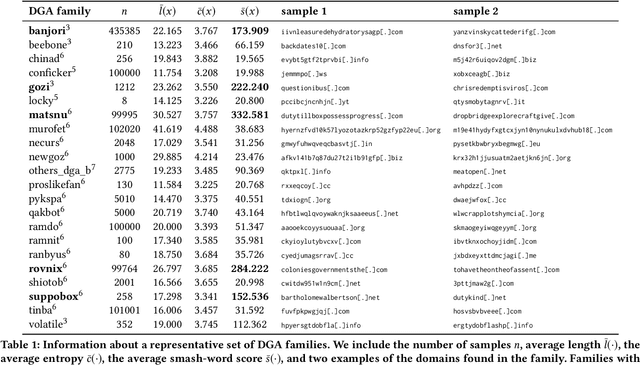
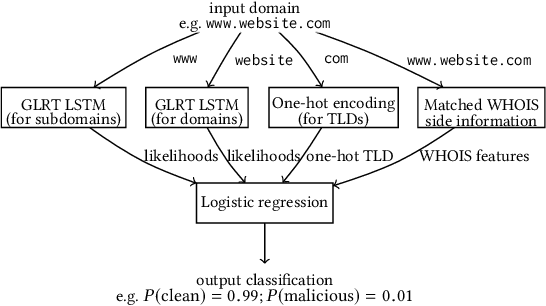

Modern malware typically makes use of a domain generation algorithm (DGA) to avoid command and control domains or IPs being seized or sinkholed. This means that an infected system may attempt to access many domains in an attempt to contact the command and control server. Therefore, the automatic detection of DGA domains is an important task, both for the sake of blocking malicious domains and identifying compromised hosts. However, many DGAs use English wordlists to generate plausibly clean-looking domain names; this makes automatic detection difficult. In this work, we devise a notion of difficulty for DGA families called the smashword score; this measures how much a DGA family looks like English words. We find that this measure accurately reflects how much a DGA family's domains look like they are made from natural English words. We then describe our new modeling approach, which is a combination of a novel recurrent neural network architecture with domain registration side information. Our experiments show the model is capable of effectively identifying domains generated by difficult DGA families. Our experiments also show that our model outperforms existing approaches, and is able to reliably detect difficult DGA families such as matsnu, suppobox, rovnix, and others. The model's performance compared to the state of the art is best for DGA families that resemble English words. We believe that this model could either be used in a standalone DGA domain detector---such as an endpoint security application---or alternately the model could be used as a part of a larger malware detection system.
On Detecting Messaging Abuse in Short Text Messages using Linguistic and Behavioral patterns
Aug 18, 2014

The use of short text messages in social media and instant messaging has become a popular communication channel during the last years. This rising popularity has caused an increment in messaging threats such as spam, phishing or malware as well as other threats. The processing of these short text message threats could pose additional challenges such as the presence of lexical variants, SMS-like contractions or advanced obfuscations which can degrade the performance of traditional filtering solutions. By using a real-world SMS data set from a large telecommunications operator from the US and a social media corpus, in this paper we analyze the effectiveness of machine learning filters based on linguistic and behavioral patterns in order to detect short text spam and abusive users in the network. We have also explored different ways to deal with short text message challenges such as tokenization and entity detection by using text normalization and substring clustering techniques. The obtained results show the validity of the proposed solution by enhancing baseline approaches.