 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAEs for Linear Inverse Problems: Improved Recovery with Provable Guarantees
Jan 13, 2021


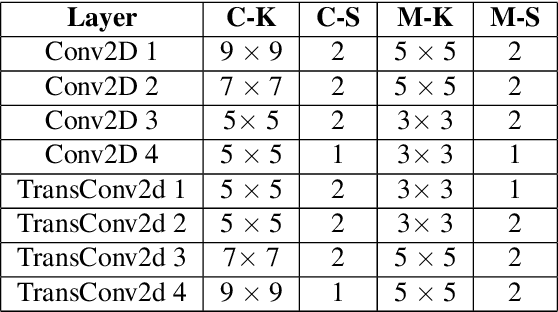
Generative priors have been shown to provide improved results over sparsity priors in linear inverse problems. However, current state of the art methods suffer from one or more of the following drawbacks: (a) speed of recovery is slow; (b) reconstruction quality is deficient; (c) reconstruction quality is contingent on a computationally expensive process of tuning hyperparameters. In this work, we address these issues by utilizing Denoising Auto Encoders (DAEs) as priors and a projected gradient descent algorithm for recovering the original signal. We provide rigorous theoretical guarantees for our method and experimentally demonstrate its superiority over existing state of the art methods in compressive sensing, inpainting, and super-resolution. We find that our algorithm speeds up recovery by two orders of magnitude (over 100x), improves quality of reconstruction by an order of magnitude (over 10x), and does not require tuning hyperparameters.
Recovery Guarantees for Compressible Signals with Adversarial Noise
Aug 07, 2019



We provide recovery guarantees for compressible signals that have been corrupted with noise and extend the framework introduced in \cite{bafna2018thwarting} to defend neural networks against $\ell_0$-norm, $\ell_2$-norm, and $\ell_{\infty}$-norm attacks. Our results are general as they can be applied to most unitary transforms used in practice and hold for $\ell_0$-norm, $\ell_2$-norm, and $\ell_\infty$-norm bounded noise. In the case of $\ell_0$-norm noise, we prove recovery guarantees for Iterative Hard Thresholding (IHT) and Basis Pursuit (BP). For $\ell_2$-norm bounded noise, we provide recovery guarantees for BP and for the case of $\ell_\infty$-norm bounded noise, we provide recovery guarantees for Dantzig Selector (DS). These guarantees theoretically bolster the defense framework introduced in \cite{bafna2018thwarting} for defending neural networks against adversarial inputs. Finally, we experimentally demonstrate the effectiveness of this defense framework against an array of $\ell_0$, $\ell_2$ and $\ell_\infty$ norm attacks.
Gradient Similarity: An Explainable Approach to Detect Adversarial Attacks against Deep Learning
Jun 27, 2018

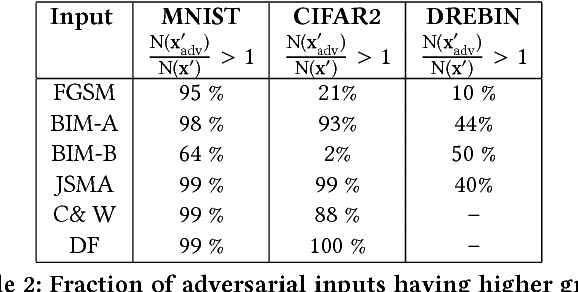
Deep neural networks are susceptible to small-but-specific adversarial perturbations capable of deceiving the network. This vulnerability can lead to potentially harmful consequences in security-critical applications. To address this vulnerability, we propose a novel metric called \emph{Gradient Similarity} that allows us to capture the influence of training data on test inputs. We show that \emph{Gradient Similarity} behaves differently for normal and adversarial inputs, and enables us to detect a variety of adversarial attacks with a near perfect ROC-AUC of 95-100\%. Even white-box adversaries equipped with perfect knowledge of the system cannot bypass our detector easily. On the MNIST dataset, white-box attacks are either detected with a high ROC-AUC of 87-96\%, or require very high distortion to bypass our detector.