 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Similarity: An Explainable Approach to Detect Adversarial Attacks against Deep Learning
Paper and Code
Jun 27, 2018

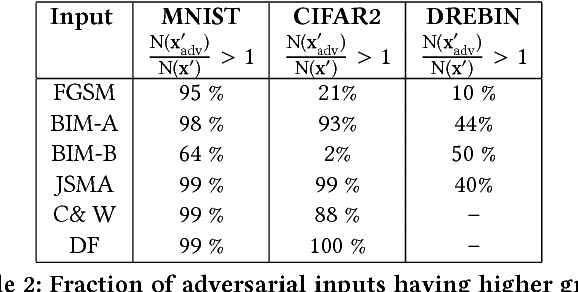
Deep neural networks are susceptible to small-but-specific adversarial perturbations capable of deceiving the network. This vulnerability can lead to potentially harmful consequences in security-critical applications. To address this vulnerability, we propose a novel metric called \emph{Gradient Similarity} that allows us to capture the influence of training data on test inputs. We show that \emph{Gradient Similarity} behaves differently for normal and adversarial inputs, and enables us to detect a variety of adversarial attacks with a near perfect ROC-AUC of 95-100\%. Even white-box adversaries equipped with perfect knowledge of the system cannot bypass our detector easily. On the MNIST dataset, white-box attacks are either detected with a high ROC-AUC of 87-96\%, or require very high distortion to bypass our detector.