 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSy-FAR: Symmetry-based Fair Adversarial Robustness
Sep 16, 2025Security-critical machine-learning (ML) systems, such as face-recognition systems, are susceptible to adversarial examples, including real-world physically realizable attacks. Various means to boost ML's adversarial robustness have been proposed; however, they typically induce unfair robustness: It is often easier to attack from certain classes or groups than from others. Several techniques have been developed to improve adversarial robustness while seeking perfect fairness between classes. Yet, prior work has focused on settings where security and fairness are less critical. Our insight is that achieving perfect parity in realistic fairness-critical tasks, such as face recognition, is often infeasible -- some classes may be highly similar, leading to more misclassifications between them. Instead, we suggest that seeking symmetry -- i.e., attacks from class $i$ to $j$ would be as successful as from $j$ to $i$ -- is more tractable. Intuitively, symmetry is a desirable because class resemblance is a symmetric relation in most domains. Additionally, as we prove theoretically, symmetry between individuals induces symmetry between any set of sub-groups, in contrast to other fairness notions where group-fairness is often elusive. We develop Sy-FAR, a technique to encourage symmetry while also optimizing adversarial robustness and extensively evaluate it using five datasets, with three model architectures, including against targeted and untargeted realistic attacks. The results show Sy-FAR significantly improves fair adversarial robustness compared to state-of-the-art methods. Moreover, we find that Sy-FAR is faster and more consistent across runs. Notably, Sy-FAR also ameliorates another type of unfairness we discover in this work -- target classes that adversarial examples are likely to be classified into become significantly less vulnerable after inducing symmetry.
GASLITEing the Retrieval: Exploring Vulnerabilities in Dense Embedding-based Search
Dec 30, 2024Dense embedding-based text retrieval$\unicode{x2013}$retrieval of relevant passages from corpora via deep learning encodings$\unicode{x2013}$has emerged as a powerful method attaining state-of-the-art search results and popularizing the use of Retrieval Augmented Generation (RAG). Still, like other search methods, embedding-based retrieval may be susceptible to search-engine optimization (SEO) attacks, where adversaries promote malicious content by introducing adversarial passages to corpora. To faithfully assess and gain insights into the susceptibility of such systems to SEO, this work proposes the GASLITE attack, a mathematically principled gradient-based search method for generating adversarial passages without relying on the corpus content or modifying the model. Notably, GASLITE's passages (1) carry adversary-chosen information while (2) achieving high retrieval ranking for a selected query distribution when inserted to corpora. We use GASLITE to extensively evaluate retrievers' robustness, testing nine advanced models under varied threat models, while focusing on realistic adversaries targeting queries on a specific concept (e.g., a public figure). We found GASLITE consistently outperformed baselines by $\geq$140% success rate, in all settings. Particularly, adversaries using GASLITE require minimal effort to manipulate search results$\unicode{x2013}$by injecting a negligible amount of adversarial passages ($\leq$0.0001% of the corpus), they could make them visible in the top-10 results for 61-100% of unseen concept-specific queries against most evaluated models. Inspecting variance in retrievers' robustness, we identify key factors that may contribute to models' susceptibility to SEO, including specific properties in the embedding space's geometry.
Impactful Bit-Flip Search on Full-precision Models
Nov 12, 2024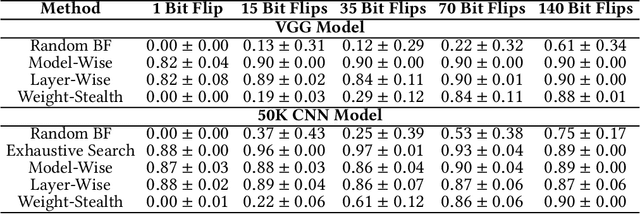
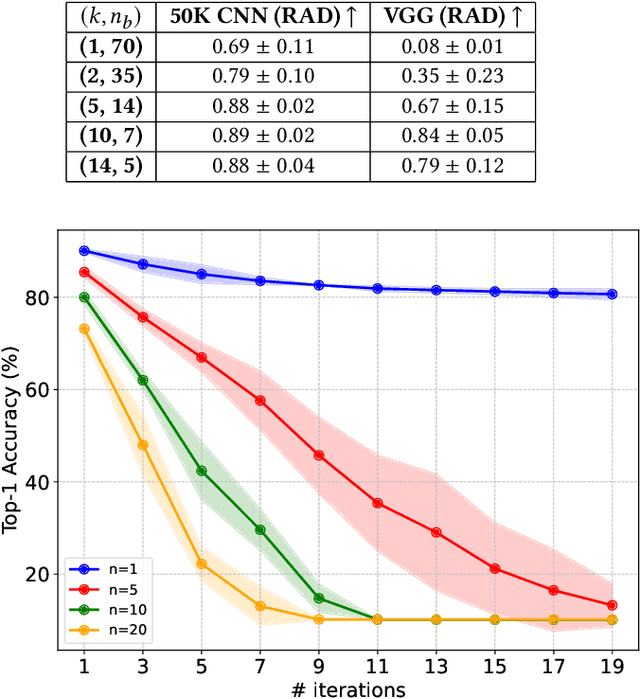
Neural networks have shown remarkable performance in various tasks, yet they remain susceptible to subtle changes in their input or model parameters. One particularly impactful vulnerability arises through the Bit-Flip Attack (BFA), where flipping a small number of critical bits in a model's parameters can severely degrade its performance. A common technique for inducing bit flips in DRAM is the Row-Hammer attack, which exploits frequent uncached memory accesses to alter data. Identifying susceptible bits can be achieved through exhaustive search or progressive layer-by-layer analysis, especially in quantized networks. In this work, we introduce Impactful Bit-Flip Search (IBS), a novel method for efficiently pinpointing and flipping critical bits in full-precision networks. Additionally, we propose a Weight-Stealth technique that strategically modifies the model's parameters in a way that maintains the float values within the original distribution, thereby bypassing simple range checks often used in tamper detection.
Adversarial Robustness Through Artifact Design
Feb 07, 2024Adversarial examples arose as a challenge for machine learning. To hinder them, most defenses alter how models are trained (e.g., adversarial training) or inference is made (e.g., randomized smoothing). Still, while these approaches markedly improve models' adversarial robustness, models remain highly susceptible to adversarial examples. Identifying that, in certain domains such as traffic-sign recognition, objects are implemented per standards specifying how artifacts (e.g., signs) should be designed, we propose a novel approach for improving adversarial robustness. Specifically, we offer a method to redefine standards, making minor changes to existing ones, to defend against adversarial examples. We formulate the problem of artifact design as a robust optimization problem, and propose gradient-based and greedy search methods to solve it. We evaluated our approach in the domain of traffic-sign recognition, allowing it to alter traffic-sign pictograms (i.e., symbols within the signs) and their colors. We found that, combined with adversarial training, our approach led to up to 25.18\% higher robust accuracy compared to state-of-the-art methods against two adversary types, while further increasing accuracy on benign inputs.
The Ultimate Combo: Boosting Adversarial Example Transferability by Composing Data Augmentations
Dec 18, 2023Transferring adversarial examples (AEs) from surrogate machine-learning (ML) models to target models is commonly used in black-box adversarial robustness evaluation. Attacks leveraging certain data augmentation, such as random resizing, have been found to help AEs generalize from surrogates to targets. Yet, prior work has explored limited augmentations and their composition. To fill the gap, we systematically studied how data augmentation affects transferability. Particularly, we explored 46 augmentation techniques of seven categories originally proposed to help ML models generalize to unseen benign samples, and assessed how they impact transferability, when applied individually or composed. Performing exhaustive search on a small subset of augmentation techniques and genetic search on all techniques, we identified augmentation combinations that can help promote transferability. Extensive experiments with the ImageNet and CIFAR-10 datasets and 18 models showed that simple color-space augmentations (e.g., color to greyscale) outperform the state of the art when combined with standard augmentations, such as translation and scaling. Additionally, we discovered that composing augmentations impacts transferability mostly monotonically (i.e., more methods composed $\rightarrow$ $\ge$ transferability). We also found that the best composition significantly outperformed the state of the art (e.g., 93.7% vs. $\le$ 82.7% average transferability on ImageNet from normally trained surrogates to adversarially trained targets). Lastly, our theoretical analysis, backed up by empirical evidence, intuitively explain why certain augmentations help improve transferability.
Group-based Robustness: A General Framework for Customized Robustness in the Real World
Jun 29, 2023Machine-learning models are known to be vulnerable to evasion attacks that perturb model inputs to induce misclassifications. In this work, we identify real-world scenarios where the true threat cannot be assessed accurately by existing attacks. Specifically, we find that conventional metrics measuring targeted and untargeted robustness do not appropriately reflect a model's ability to withstand attacks from one set of source classes to another set of target classes. To address the shortcomings of existing methods, we formally define a new metric, termed group-based robustness, that complements existing metrics and is better-suited for evaluating model performance in certain attack scenarios. We show empirically that group-based robustness allows us to distinguish between models' vulnerability against specific threat models in situations where traditional robustness metrics do not apply. Moreover, to measure group-based robustness efficiently and accurately, we 1) propose two loss functions and 2) identify three new attack strategies. We show empirically that with comparable success rates, finding evasive samples using our new loss functions saves computation by a factor as large as the number of targeted classes, and finding evasive samples using our new attack strategies saves time by up to 99\% compared to brute-force search methods. Finally, we propose a defense method that increases group-based robustness by up to 3.52$\times$.
Scalable Verification of GNN-based Job Schedulers
Mar 07, 2022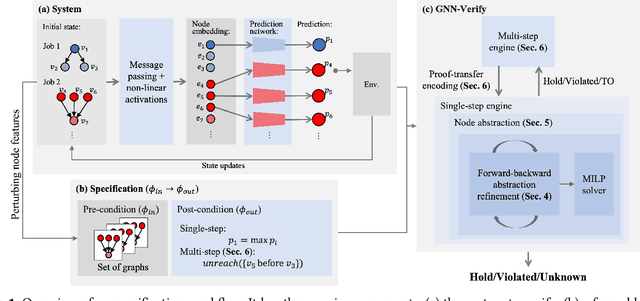
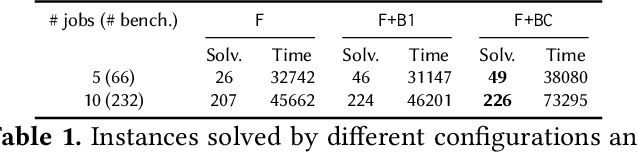
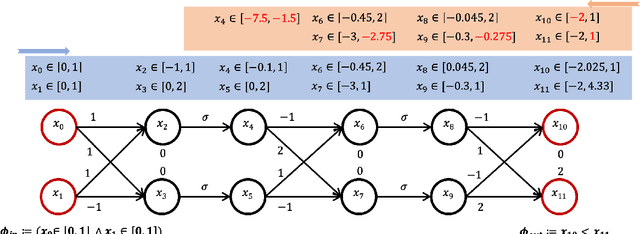

Recently, Graph Neural Networks (GNNs) have been applied for scheduling jobs over clusters achieving better performance than hand-crafted heuristics. Despite their impressive performance, concerns remain over their trustworthiness when deployed in a real-world environment due to their black-box nature. To address these limitations, we consider formal verification of their expected properties such as strategy proofness and locality in this work. We address several domain-specific challenges such as deeper networks and richer specifications not encountered by existing verifiers for image and NLP classifiers. We develop GNN-Verify, the first general framework for verifying both single-step and multi-step properties of these schedulers based on carefully designed algorithms that combine abstractions, refinements, solvers, and proof transfer. Our experimental results on challenging benchmarks show that our approach can provide precise and scalable formal guarantees on the trustworthiness of state-of-the-art GNN-based scheduler.
Constrained Gradient Descent: A Powerful and Principled Evasion Attack Against Neural Networks
Dec 28, 2021
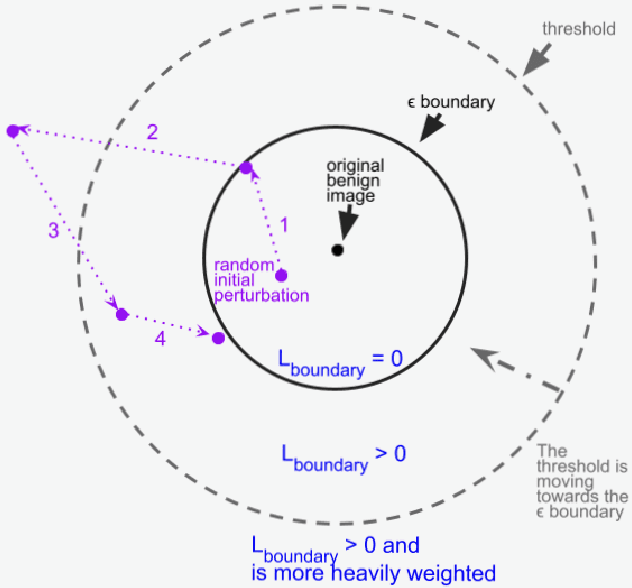
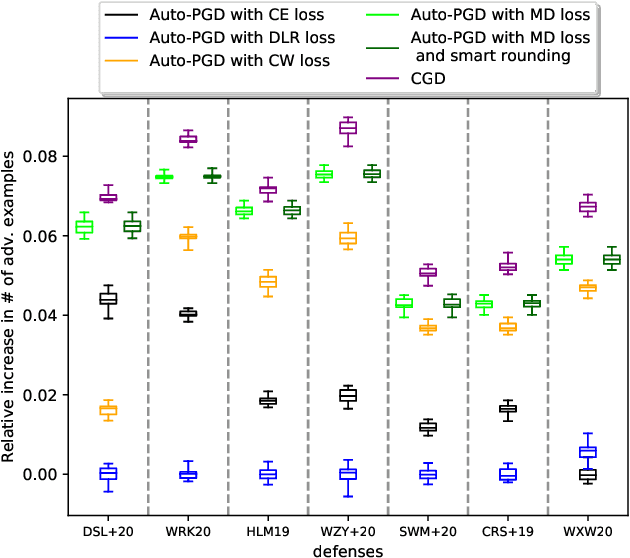
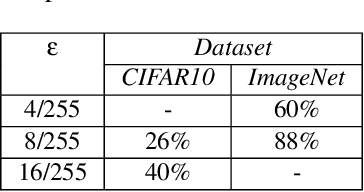
Minimal adversarial perturbations added to inputs have been shown to be effective at fooling deep neural networks. In this paper, we introduce several innovations that make white-box targeted attacks follow the intuition of the attacker's goal: to trick the model to assign a higher probability to the target class than to any other, while staying within a specified distance from the original input. First, we propose a new loss function that explicitly captures the goal of targeted attacks, in particular, by using the logits of all classes instead of just a subset, as is common. We show that Auto-PGD with this loss function finds more adversarial examples than it does with other commonly used loss functions. Second, we propose a new attack method that uses a further developed version of our loss function capturing both the misclassification objective and the $L_{\infty}$ distance limit $\epsilon$. This new attack method is relatively 1.5--4.2% more successful on the CIFAR10 dataset and relatively 8.2--14.9% more successful on the ImageNet dataset, than the next best state-of-the-art attack. We confirm using statistical tests that our attack outperforms state-of-the-art attacks on different datasets and values of $\epsilon$ and against different defenses.
Optimization-Guided Binary Diversification to Mislead Neural Networks for Malware Detection
Dec 19, 2019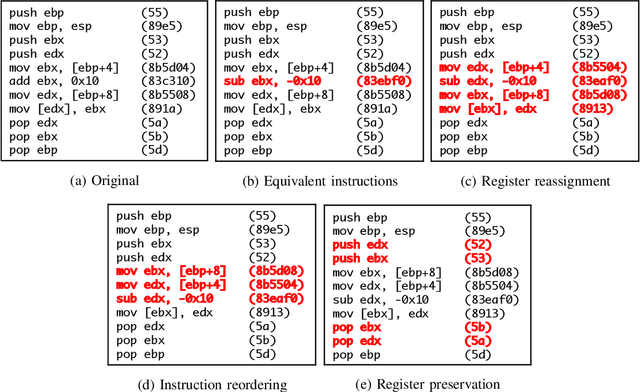

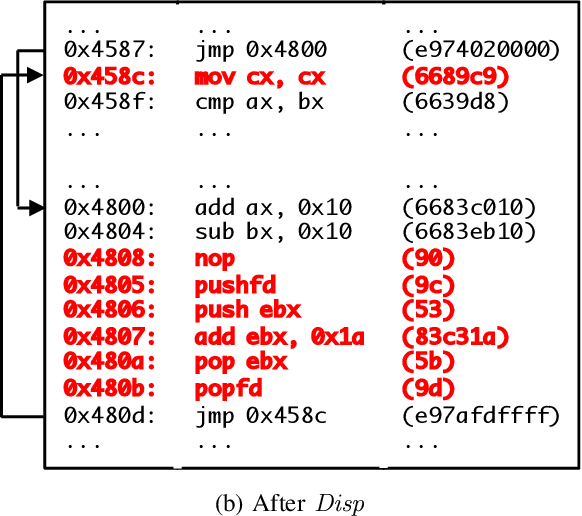
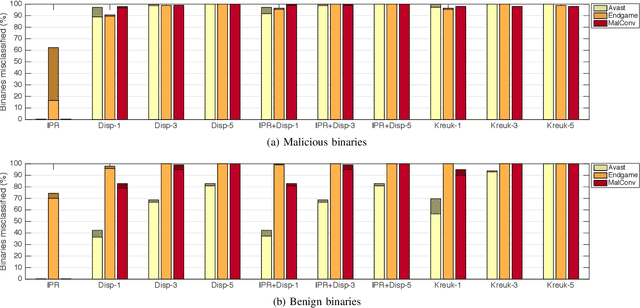
Motivated by the transformative impact of deep neural networks (DNNs) on different areas (e.g., image and speech recognition), researchers and anti-virus vendors are proposing end-to-end DNNs for malware detection from raw bytes that do not require manual feature engineering. Given the security sensitivity of the task that these DNNs aim to solve, it is important to assess their susceptibility to evasion. In this work, we propose an attack that guides binary-diversification tools via optimization to mislead DNNs for malware detection while preserving the functionality of binaries. Unlike previous attacks on such DNNs, ours manipulates instructions that are a functional part of the binary, which makes it particularly challenging to defend against. We evaluated our attack against three DNNs in white-box and black-box settings, and found that it can often achieve success rates near 100%. Moreover, we found that our attack can fool some commercial anti-viruses, in certain cases with a success rate of 85%. We explored several defenses, both new and old, and identified some that can successfully prevent over 80% of our evasion attempts. However, these defenses may still be susceptible to evasion by adaptive attackers, and so we advocate for augmenting malware-detection systems with methods that do not rely on machine learning.
$n$-ML: Mitigating Adversarial Examples via Ensembles of Topologically Manipulated Classifiers
Dec 19, 2019

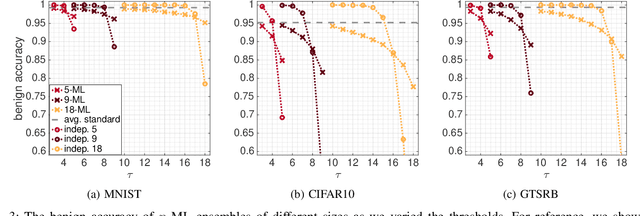
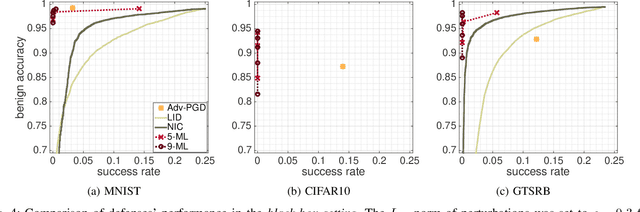
This paper proposes a new defense called $n$-ML against adversarial examples, i.e., inputs crafted by perturbing benign inputs by small amounts to induce misclassifications by classifiers. Inspired by $n$-version programming, $n$-ML trains an ensemble of $n$ classifiers, and inputs are classified by a vote of the classifiers in the ensemble. Unlike prior such approaches, however, the classifiers in the ensemble are trained specifically to classify adversarial examples differently, rendering it very difficult for an adversarial example to obtain enough votes to be misclassified. We show that $n$-ML roughly retains the benign classification accuracies of state-of-the-art models on the MNIST, CIFAR10, and GTSRB datasets, while simultaneously defending against adversarial examples with better resilience than the best defenses known to date and, in most cases, with lower classification-time overhead.