 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpactful Bit-Flip Search on Full-precision Models
Nov 12, 2024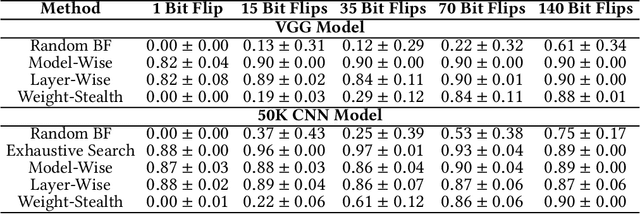
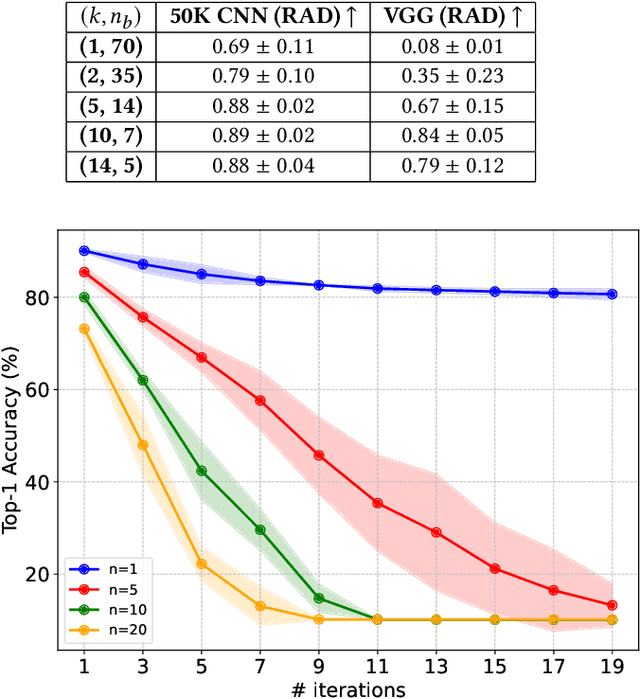
Neural networks have shown remarkable performance in various tasks, yet they remain susceptible to subtle changes in their input or model parameters. One particularly impactful vulnerability arises through the Bit-Flip Attack (BFA), where flipping a small number of critical bits in a model's parameters can severely degrade its performance. A common technique for inducing bit flips in DRAM is the Row-Hammer attack, which exploits frequent uncached memory accesses to alter data. Identifying susceptible bits can be achieved through exhaustive search or progressive layer-by-layer analysis, especially in quantized networks. In this work, we introduce Impactful Bit-Flip Search (IBS), a novel method for efficiently pinpointing and flipping critical bits in full-precision networks. Additionally, we propose a Weight-Stealth technique that strategically modifies the model's parameters in a way that maintains the float values within the original distribution, thereby bypassing simple range checks often used in tamper detection.
PRILoRA: Pruned and Rank-Increasing Low-Rank Adaptation
Jan 20, 2024With the proliferation of large pre-trained language models (PLMs), fine-tuning all model parameters becomes increasingly inefficient, particularly when dealing with numerous downstream tasks that entail substantial training and storage costs. Several approaches aimed at achieving parameter-efficient fine-tuning (PEFT) have been proposed. Among them, Low-Rank Adaptation (LoRA) stands out as an archetypal method, incorporating trainable rank decomposition matrices into each target module. Nevertheless, LoRA does not consider the varying importance of each layer. To address these challenges, we introduce PRILoRA, which linearly allocates a different rank for each layer, in an increasing manner, and performs pruning throughout the training process, considering both the temporary magnitude of weights and the accumulated statistics of the input to any given layer. We validate the effectiveness of PRILoRA through extensive experiments on eight GLUE benchmarks, setting a new state of the art.