 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-Augmented Gaussian Avatars: Improving Expression Generalization
Mar 09, 2026Template-free animatable head avatars can achieve high visual fidelity by learning expression-dependent facial deformation directly from a subject's capture, avoiding parametric face templates and hand-designed blendshape spaces. However, since learned deformation is supervised only by the expressions observed for a single identity, these models suffer from limited expression coverage and often struggle when driven by motions that deviate from the training distribution. We introduce RAF (Retrieval-Augmented Faces), a simple training-time augmentation designed for template-free head avatars that learn deformation from data. RAF constructs a large unlabeled expression bank and, during training, replaces a subset of the subject's expression features with nearest-neighbor expressions retrieved from this bank while still reconstructing the subject's original frames. This exposes the deformation field to a broader range of expression conditions, encouraging stronger identity-expression decoupling and improving robustness to expression distribution shift without requiring paired cross-identity data, additional annotations, or architectural changes. We further analyze how retrieval augmentation increases expression diversity and validate retrieval quality with a user study showing that retrieved neighbors are perceptually closer in expression and pose. Experiments on the NeRSemble benchmark demonstrate that RAF consistently improves expression fidelity over the baseline, in both self-driving and cross-driving scenarios.
Fast Autoregressive Video Diffusion and World Models with Temporal Cache Compression and Sparse Attention
Feb 02, 2026Autoregressive video diffusion models enable streaming generation, opening the door to long-form synthesis, video world models, and interactive neural game engines. However, their core attention layers become a major bottleneck at inference time: as generation progresses, the KV cache grows, causing both increasing latency and escalating GPU memory, which in turn restricts usable temporal context and harms long-range consistency. In this work, we study redundancy in autoregressive video diffusion and identify three persistent sources: near-duplicate cached keys across frames, slowly evolving (largely semantic) queries/keys that make many attention computations redundant, and cross-attention over long prompts where only a small subset of tokens matters per frame. Building on these observations, we propose a unified, training-free attention framework for autoregressive diffusion: TempCache compresses the KV cache via temporal correspondence to bound cache growth; AnnCA accelerates cross-attention by selecting frame-relevant prompt tokens using fast approximate nearest neighbor (ANN) matching; and AnnSA sparsifies self-attention by restricting each query to semantically matched keys, also using a lightweight ANN. Together, these modules reduce attention, compute, and memory and are compatible with existing autoregressive diffusion backbones and world models. Experiments demonstrate up to x5--x10 end-to-end speedups while preserving near-identical visual quality and, crucially, maintaining stable throughput and nearly constant peak GPU memory usage over long rollouts, where prior methods progressively slow down and suffer from increasing memory usage.
Story2Board: A Training-Free Approach for Expressive Storyboard Generation
Aug 13, 2025We present Story2Board, a training-free framework for expressive storyboard generation from natural language. Existing methods narrowly focus on subject identity, overlooking key aspects of visual storytelling such as spatial composition, background evolution, and narrative pacing. To address this, we introduce a lightweight consistency framework composed of two components: Latent Panel Anchoring, which preserves a shared character reference across panels, and Reciprocal Attention Value Mixing, which softly blends visual features between token pairs with strong reciprocal attention. Together, these mechanisms enhance coherence without architectural changes or fine-tuning, enabling state-of-the-art diffusion models to generate visually diverse yet consistent storyboards. To structure generation, we use an off-the-shelf language model to convert free-form stories into grounded panel-level prompts. To evaluate, we propose the Rich Storyboard Benchmark, a suite of open-domain narratives designed to assess layout diversity and background-grounded storytelling, in addition to consistency. We also introduce a new Scene Diversity metric that quantifies spatial and pose variation across storyboards. Our qualitative and quantitative results, as well as a user study, show that Story2Board produces more dynamic, coherent, and narratively engaging storyboards than existing baselines.
Find your Needle: Small Object Image Retrieval via Multi-Object Attention Optimization
Mar 10, 2025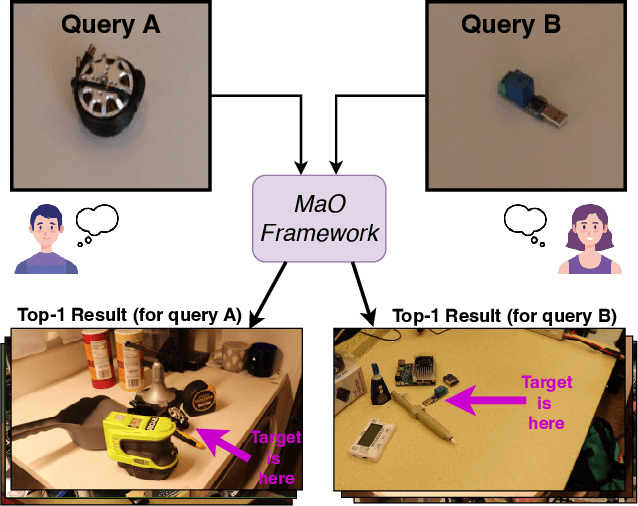
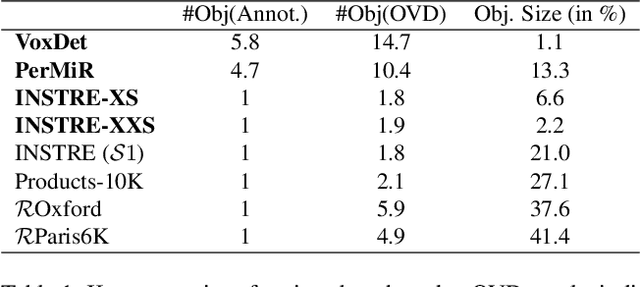
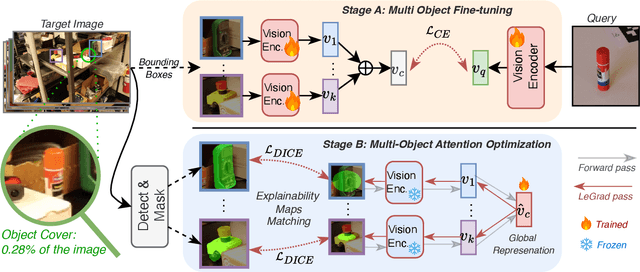
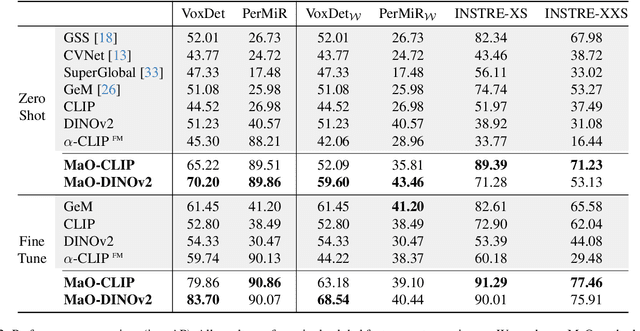
We address the challenge of Small Object Image Retrieval (SoIR), where the goal is to retrieve images containing a specific small object, in a cluttered scene. The key challenge in this setting is constructing a single image descriptor, for scalable and efficient search, that effectively represents all objects in the image. In this paper, we first analyze the limitations of existing methods on this challenging task and then introduce new benchmarks to support SoIR evaluation. Next, we introduce Multi-object Attention Optimization (MaO), a novel retrieval framework which incorporates a dedicated multi-object pre-training phase. This is followed by a refinement process that leverages attention-based feature extraction with object masks, integrating them into a single unified image descriptor. Our MaO approach significantly outperforms existing retrieval methods and strong baselines, achieving notable improvements in both zero-shot and lightweight multi-object fine-tuning. We hope this work will lay the groundwork and inspire further research to enhance retrieval performance for this highly practical task.
Task-Specific Adaptation with Restricted Model Access
Feb 02, 2025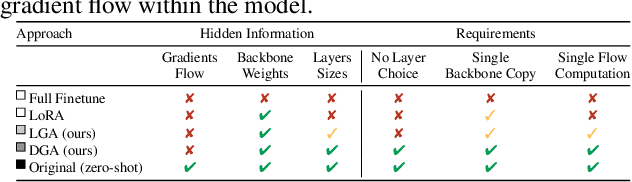
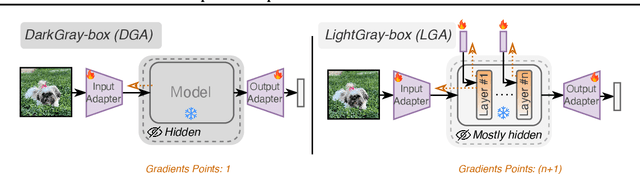
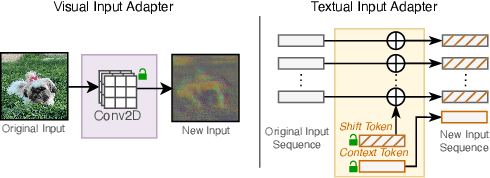
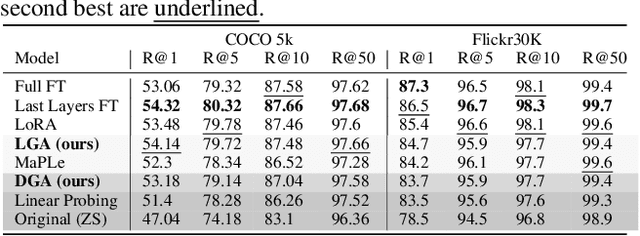
The emergence of foundational models has greatly improved performance across various downstream tasks, with fine-tuning often yielding even better results. However, existing fine-tuning approaches typically require access to model weights and layers, leading to challenges such as managing multiple model copies or inference pipelines, inefficiencies in edge device optimization, and concerns over proprietary rights, privacy, and exposure to unsafe model variants. In this paper, we address these challenges by exploring "Gray-box" fine-tuning approaches, where the model's architecture and weights remain hidden, allowing only gradient propagation. We introduce a novel yet simple and effective framework that adapts to new tasks using two lightweight learnable modules at the model's input and output. Additionally, we present a less restrictive variant that offers more entry points into the model, balancing performance with model exposure. We evaluate our approaches across several backbones on benchmarks such as text-image alignment, text-video alignment, and sketch-image alignment. Results show that our Gray-box approaches are competitive with full-access fine-tuning methods, despite having limited access to the model.
Impactful Bit-Flip Search on Full-precision Models
Nov 12, 2024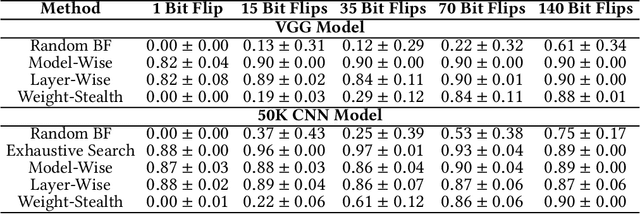
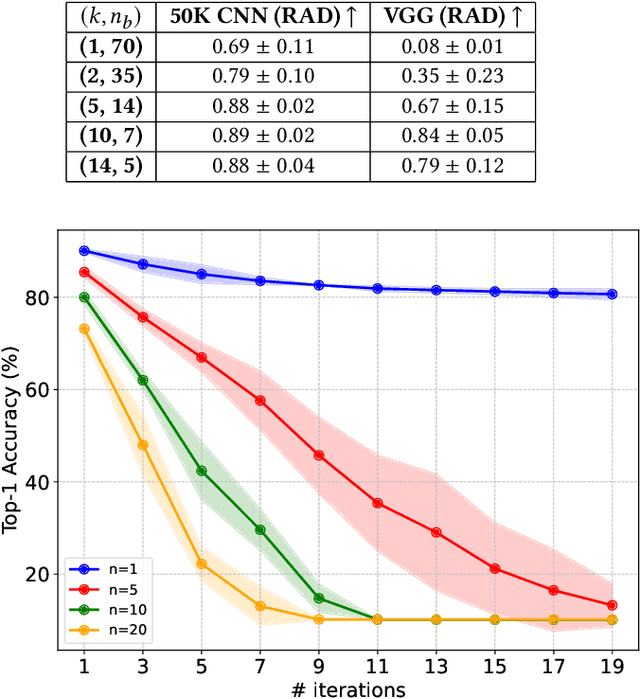
Neural networks have shown remarkable performance in various tasks, yet they remain susceptible to subtle changes in their input or model parameters. One particularly impactful vulnerability arises through the Bit-Flip Attack (BFA), where flipping a small number of critical bits in a model's parameters can severely degrade its performance. A common technique for inducing bit flips in DRAM is the Row-Hammer attack, which exploits frequent uncached memory accesses to alter data. Identifying susceptible bits can be achieved through exhaustive search or progressive layer-by-layer analysis, especially in quantized networks. In this work, we introduce Impactful Bit-Flip Search (IBS), a novel method for efficiently pinpointing and flipping critical bits in full-precision networks. Additionally, we propose a Weight-Stealth technique that strategically modifies the model's parameters in a way that maintains the float values within the original distribution, thereby bypassing simple range checks often used in tamper detection.
Accelerating Error Correction Code Transformers
Oct 08, 2024Error correction codes (ECC) are crucial for ensuring reliable information transmission in communication systems. Choukroun & Wolf (2022b) recently introduced the Error Correction Code Transformer (ECCT), which has demonstrated promising performance across various transmission channels and families of codes. However, its high computational and memory demands limit its practical applications compared to traditional decoding algorithms. Achieving effective quantization of the ECCT presents significant challenges due to its inherently small architecture, since existing, very low-precision quantization techniques often lead to performance degradation in compact neural networks. In this paper, we introduce a novel acceleration method for transformer-based decoders. We first propose a ternary weight quantization method specifically designed for the ECCT, inducing a decoder with multiplication-free linear layers. We present an optimized self-attention mechanism to reduce computational complexity via codeaware multi-heads processing. Finally, we provide positional encoding via the Tanner graph eigendecomposition, enabling a richer representation of the graph connectivity. The approach not only matches or surpasses ECCT's performance but also significantly reduces energy consumption, memory footprint, and computational complexity. Our method brings transformer-based error correction closer to practical implementation in resource-constrained environments, achieving a 90% compression ratio and reducing arithmetic operation energy consumption by at least 224 times on modern hardware.
EffoVPR: Effective Foundation Model Utilization for Visual Place Recognition
May 28, 2024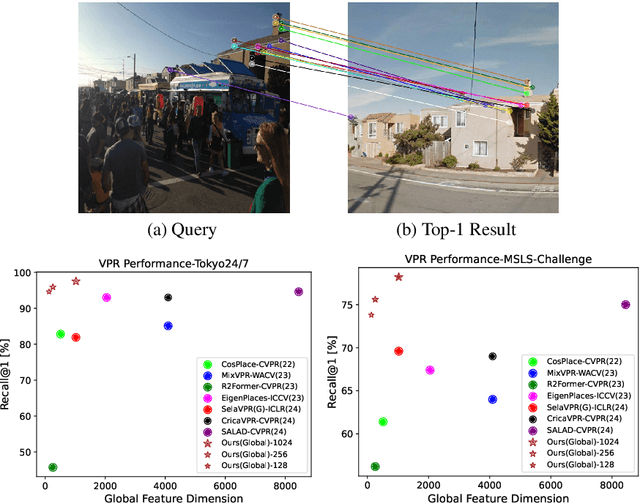
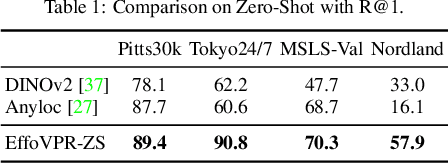
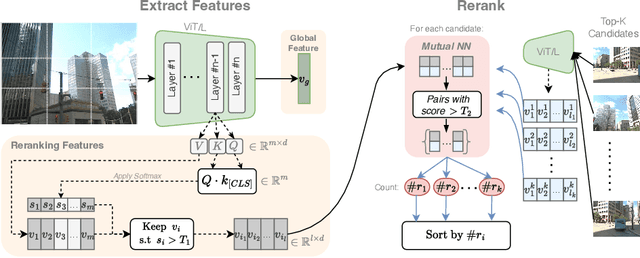
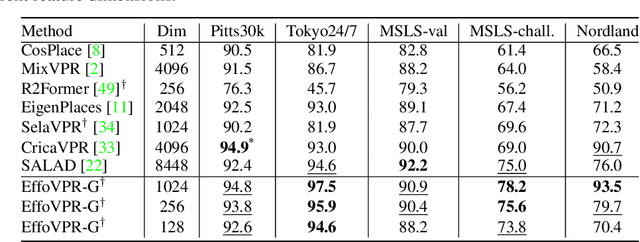
The task of Visual Place Recognition (VPR) is to predict the location of a query image from a database of geo-tagged images. Recent studies in VPR have highlighted the significant advantage of employing pre-trained foundation models like DINOv2 for the VPR task. However, these models are often deemed inadequate for VPR without further fine-tuning on task-specific data. In this paper, we propose a simple yet powerful approach to better exploit the potential of a foundation model for VPR. We first demonstrate that features extracted from self-attention layers can serve as a powerful re-ranker for VPR. Utilizing these features in a zero-shot manner, our method surpasses previous zero-shot methods and achieves competitive results compared to supervised methods across multiple datasets. Subsequently, we demonstrate that a single-stage method leveraging internal ViT layers for pooling can generate global features that achieve state-of-the-art results, even when reduced to a dimensionality as low as 128D. Nevertheless, incorporating our local foundation features for re-ranking, expands this gap. Our approach further demonstrates remarkable robustness and generalization, achieving state-of-the-art results, with a significant gap, in challenging scenarios, involving occlusion, day-night variations, and seasonal changes.
Unveiling the Power of Diffusion Features For Personalized Segmentation and Retrieval
May 28, 2024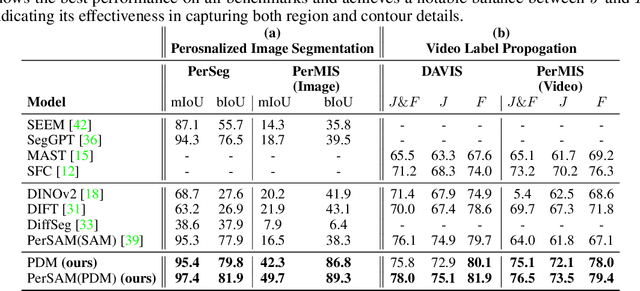

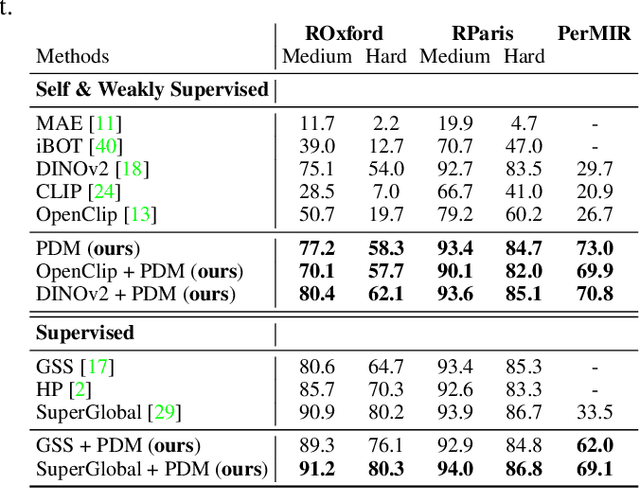
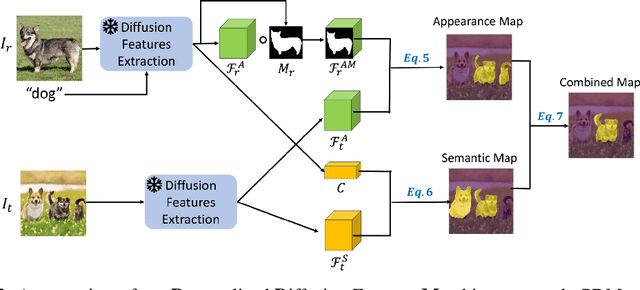
Personalized retrieval and segmentation aim to locate specific instances within a dataset based on an input image and a short description of the reference instance. While supervised methods are effective, they require extensive labeled data for training. Recently, self-supervised foundation models have been introduced to these tasks showing comparable results to supervised methods. However, a significant flaw in these models is evident: they struggle to locate a desired instance when other instances within the same class are presented. In this paper, we explore text-to-image diffusion models for these tasks. Specifically, we propose a novel approach called PDM for Personalized Features Diffusion Matching, that leverages intermediate features of pre-trained text-to-image models for personalization tasks without any additional training. PDM demonstrates superior performance on popular retrieval and segmentation benchmarks, outperforming even supervised methods. We also highlight notable shortcomings in current instance and segmentation datasets and propose new benchmarks for these tasks.
Chatting Makes Perfect -- Chat-based Image Retrieval
May 31, 2023



Chats emerge as an effective user-friendly approach for information retrieval, and are successfully employed in many domains, such as customer service, healthcare, and finance. However, existing image retrieval approaches typically address the case of a single query-to-image round, and the use of chats for image retrieval has been mostly overlooked. In this work, we introduce ChatIR: a chat-based image retrieval system that engages in a conversation with the user to elicit information, in addition to an initial query, in order to clarify the user's search intent. Motivated by the capabilities of today's foundation models, we leverage Large Language Models to generate follow-up questions to an initial image description. These questions form a dialog with the user in order to retrieve the desired image from a large corpus. In this study, we explore the capabilities of such a system tested on a large dataset and reveal that engaging in a dialog yields significant gains in image retrieval. We start by building an evaluation pipeline from an existing manually generated dataset and explore different modules and training strategies for ChatIR. Our comparison includes strong baselines derived from related applications trained with Reinforcement Learning. Our system is capable of retrieving the target image from a pool of 50K images with over 78% success rate after 5 dialogue rounds, compared to 75% when questions are asked by humans, and 64% for a single shot text-to-image retrieval. Extensive evaluations reveal the strong capabilities and examine the limitations of CharIR under different settings.