 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffoVPR: Effective Foundation Model Utilization for Visual Place Recognition
May 28, 2024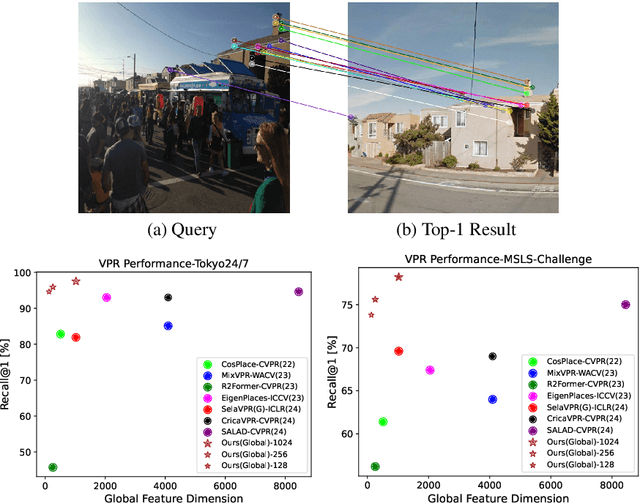
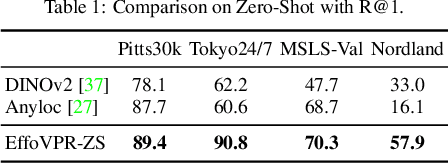
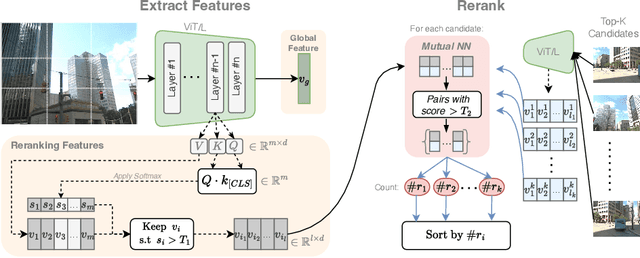
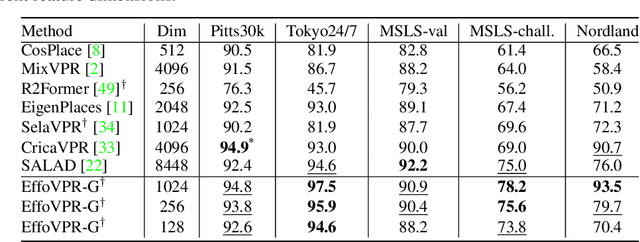
The task of Visual Place Recognition (VPR) is to predict the location of a query image from a database of geo-tagged images. Recent studies in VPR have highlighted the significant advantage of employing pre-trained foundation models like DINOv2 for the VPR task. However, these models are often deemed inadequate for VPR without further fine-tuning on task-specific data. In this paper, we propose a simple yet powerful approach to better exploit the potential of a foundation model for VPR. We first demonstrate that features extracted from self-attention layers can serve as a powerful re-ranker for VPR. Utilizing these features in a zero-shot manner, our method surpasses previous zero-shot methods and achieves competitive results compared to supervised methods across multiple datasets. Subsequently, we demonstrate that a single-stage method leveraging internal ViT layers for pooling can generate global features that achieve state-of-the-art results, even when reduced to a dimensionality as low as 128D. Nevertheless, incorporating our local foundation features for re-ranking, expands this gap. Our approach further demonstrates remarkable robustness and generalization, achieving state-of-the-art results, with a significant gap, in challenging scenarios, involving occlusion, day-night variations, and seasonal changes.
MISS GAN: A Multi-IlluStrator Style Generative Adversarial Network for image to illustration translation
Aug 12, 2021
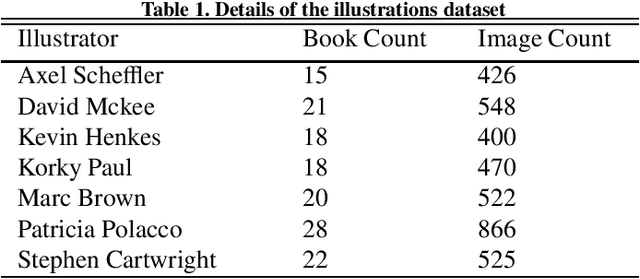
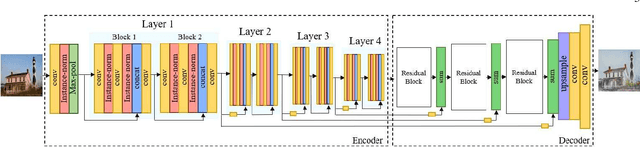

Unsupervised style transfer that supports diverse input styles using only one trained generator is a challenging and interesting task in computer vision. This paper proposes a Multi-IlluStrator Style Generative Adversarial Network (MISS GAN) that is a multi-style framework for unsupervised image-to-illustration translation, which can generate styled yet content preserving images. The illustrations dataset is a challenging one since it is comprised of illustrations of seven different illustrators, hence contains diverse styles. Existing methods require to train several generators (as the number of illustrators) to handle the different illustrators' styles, which limits their practical usage, or require to train an image specific network, which ignores the style information provided in other images of the illustrator. MISS GAN is both input image specific and uses the information of other images using only one trained model.