 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiveSVG: Zero-Shot SVG Animation via Video Generation
May 28, 2026We introduce LiveSVG, a zero-shot approach for generating Scalable Vector Graphics (SVG) animations using video diffusion models. Current SVG animation methods struggle with complex motions: LLM-based code synthesis fails to express fine, non-rigid Bézier deformations, while Score Distillation Sampling (SDS) provides noisy gradients and often requires category-specific priors like skeletons. In contrast, LiveSVG fits vector geometry directly to an explicitly generated target video. Given an input SVG image and a motion prompt, we generate a previewable target video using a frozen image-to-video model, then fit the original SVG to this video via differentiable rendering. Our fitting stage is skeleton-free, utilizing a dual-level motion representation that combines per-group homographies for coarse articulation with per-path Bézier control-point offsets for local deformations. To resolve color-induced correspondence ambiguities during pixel-wise fitting, we introduce a novel sphere-packing recolorization strategy. We also present ChallengeSVG, a benchmark of complex, multi-object scenes that exposes the limitations of prior work. Evaluations demonstrate that LiveSVG significantly outperforms existing methods on both AniClipart and ChallengeSVG, establishing direct reference-video fitting as a practical, robust route to prompt-aligned and fully editable vector animation.
Fast 4D Mesh Generation by Spatio-Temporal Attention Chains
May 19, 20264D mesh generation has recently emerged as a powerful paradigm for recovering dynamic 3D structure from videos, but existing methods remain slow, computationally expensive, and difficult to scale to longer sequences. We introduce a training-free approach that accelerates 4D mesh generation while improving temporal correspondence quality. Our key observation is that temporal correspondences emerge inside a 4D backbone long before its generated meshes become visually accurate. We exploit this with a general framework we call Spatio-Temporal Attention Chain which propagates information across space and time. Starting from vertices on an anchor mesh, the chain maps vertices to latent tokens. It then follows temporal correspondences in latent space, and recovers frame-specific vertices through latent-to-vertex attention. This design avoids expensive explicit matching while preserving anchor mesh details and thereby improving dynamic mesh geometry and temporal consistency. Compared to state-of-the-art, our method generates a 4D mesh in 9 seconds, achieving a $13\times$ speedup while producing higher-quality results. Moreover, our approach scales to videos up to $16\times$ longer without degrading mesh quality. Beyond generation, the improved correspondences enable competitive zero-shot performance on two downstream tasks: 2D object tracking and 4D tracking. We further show that our framework enables reliable camera estimation, a capability not supported by prior 4D mesh generation methods.
Retrieval-Augmented Gaussian Avatars: Improving Expression Generalization
Mar 09, 2026Template-free animatable head avatars can achieve high visual fidelity by learning expression-dependent facial deformation directly from a subject's capture, avoiding parametric face templates and hand-designed blendshape spaces. However, since learned deformation is supervised only by the expressions observed for a single identity, these models suffer from limited expression coverage and often struggle when driven by motions that deviate from the training distribution. We introduce RAF (Retrieval-Augmented Faces), a simple training-time augmentation designed for template-free head avatars that learn deformation from data. RAF constructs a large unlabeled expression bank and, during training, replaces a subset of the subject's expression features with nearest-neighbor expressions retrieved from this bank while still reconstructing the subject's original frames. This exposes the deformation field to a broader range of expression conditions, encouraging stronger identity-expression decoupling and improving robustness to expression distribution shift without requiring paired cross-identity data, additional annotations, or architectural changes. We further analyze how retrieval augmentation increases expression diversity and validate retrieval quality with a user study showing that retrieved neighbors are perceptually closer in expression and pose. Experiments on the NeRSemble benchmark demonstrate that RAF consistently improves expression fidelity over the baseline, in both self-driving and cross-driving scenarios.
VidVec: Unlocking Video MLLM Embeddings for Video-Text Retrieval
Feb 08, 2026Recent studies have adapted generative Multimodal Large Language Models (MLLMs) into embedding extractors for vision tasks, typically through fine-tuning to produce universal representations. However, their performance on video remains inferior to Video Foundation Models (VFMs). In this paper, we focus on leveraging MLLMs for video-text embedding and retrieval. We first conduct a systematic layer-wise analysis, showing that intermediate (pre-trained) MLLM layers already encode substantial task-relevant information. Leveraging this insight, we demonstrate that combining intermediate-layer embeddings with a calibrated MLLM head yields strong zero-shot retrieval performance without any training. Building on these findings, we introduce a lightweight text-based alignment strategy which maps dense video captions to short summaries and enables task-related video-text embedding learning without visual supervision. Remarkably, without any fine-tuning beyond text, our method outperforms current methods, often by a substantial margin, achieving state-of-the-art results across common video retrieval benchmarks.
Fast Autoregressive Video Diffusion and World Models with Temporal Cache Compression and Sparse Attention
Feb 02, 2026Autoregressive video diffusion models enable streaming generation, opening the door to long-form synthesis, video world models, and interactive neural game engines. However, their core attention layers become a major bottleneck at inference time: as generation progresses, the KV cache grows, causing both increasing latency and escalating GPU memory, which in turn restricts usable temporal context and harms long-range consistency. In this work, we study redundancy in autoregressive video diffusion and identify three persistent sources: near-duplicate cached keys across frames, slowly evolving (largely semantic) queries/keys that make many attention computations redundant, and cross-attention over long prompts where only a small subset of tokens matters per frame. Building on these observations, we propose a unified, training-free attention framework for autoregressive diffusion: TempCache compresses the KV cache via temporal correspondence to bound cache growth; AnnCA accelerates cross-attention by selecting frame-relevant prompt tokens using fast approximate nearest neighbor (ANN) matching; and AnnSA sparsifies self-attention by restricting each query to semantically matched keys, also using a lightweight ANN. Together, these modules reduce attention, compute, and memory and are compatible with existing autoregressive diffusion backbones and world models. Experiments demonstrate up to x5--x10 end-to-end speedups while preserving near-identical visual quality and, crucially, maintaining stable throughput and nearly constant peak GPU memory usage over long rollouts, where prior methods progressively slow down and suffer from increasing memory usage.
Story2Board: A Training-Free Approach for Expressive Storyboard Generation
Aug 13, 2025We present Story2Board, a training-free framework for expressive storyboard generation from natural language. Existing methods narrowly focus on subject identity, overlooking key aspects of visual storytelling such as spatial composition, background evolution, and narrative pacing. To address this, we introduce a lightweight consistency framework composed of two components: Latent Panel Anchoring, which preserves a shared character reference across panels, and Reciprocal Attention Value Mixing, which softly blends visual features between token pairs with strong reciprocal attention. Together, these mechanisms enhance coherence without architectural changes or fine-tuning, enabling state-of-the-art diffusion models to generate visually diverse yet consistent storyboards. To structure generation, we use an off-the-shelf language model to convert free-form stories into grounded panel-level prompts. To evaluate, we propose the Rich Storyboard Benchmark, a suite of open-domain narratives designed to assess layout diversity and background-grounded storytelling, in addition to consistency. We also introduce a new Scene Diversity metric that quantifies spatial and pose variation across storyboards. Our qualitative and quantitative results, as well as a user study, show that Story2Board produces more dynamic, coherent, and narratively engaging storyboards than existing baselines.
Per-Query Visual Concept Learning
Aug 12, 2025Visual concept learning, also known as Text-to-image personalization, is the process of teaching new concepts to a pretrained model. This has numerous applications from product placement to entertainment and personalized design. Here we show that many existing methods can be substantially augmented by adding a personalization step that is (1) specific to the prompt and noise seed, and (2) using two loss terms based on the self- and cross- attention, capturing the identity of the personalized concept. Specifically, we leverage PDM features -- previously designed to capture identity -- and show how they can be used to improve personalized semantic similarity. We evaluate the benefit that our method gains on top of six different personalization methods, and several base text-to-image models (both UNet- and DiT-based). We find significant improvements even over previous per-query personalization methods.
Find your Needle: Small Object Image Retrieval via Multi-Object Attention Optimization
Mar 10, 2025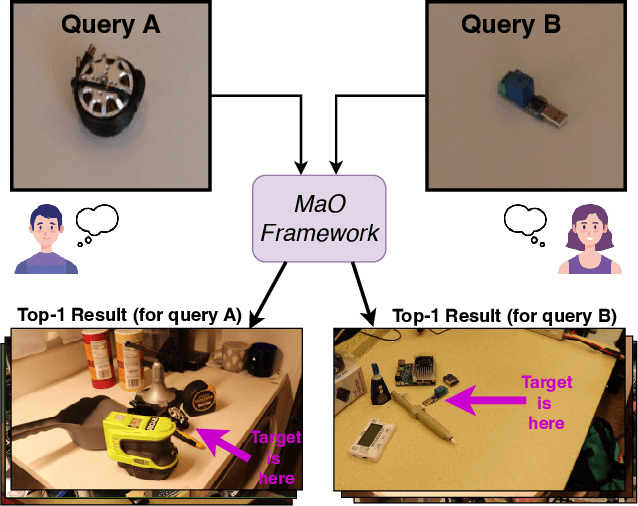
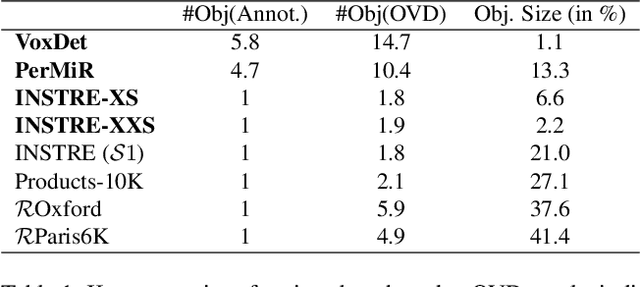
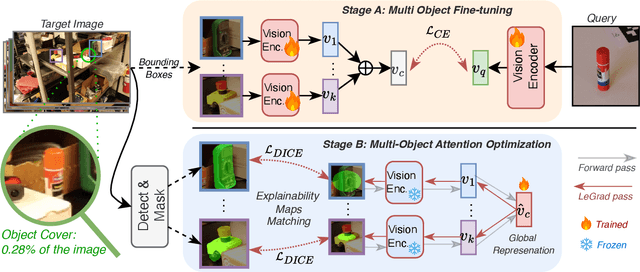
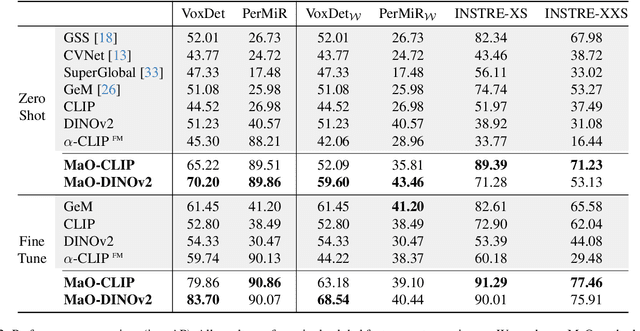
We address the challenge of Small Object Image Retrieval (SoIR), where the goal is to retrieve images containing a specific small object, in a cluttered scene. The key challenge in this setting is constructing a single image descriptor, for scalable and efficient search, that effectively represents all objects in the image. In this paper, we first analyze the limitations of existing methods on this challenging task and then introduce new benchmarks to support SoIR evaluation. Next, we introduce Multi-object Attention Optimization (MaO), a novel retrieval framework which incorporates a dedicated multi-object pre-training phase. This is followed by a refinement process that leverages attention-based feature extraction with object masks, integrating them into a single unified image descriptor. Our MaO approach significantly outperforms existing retrieval methods and strong baselines, achieving notable improvements in both zero-shot and lightweight multi-object fine-tuning. We hope this work will lay the groundwork and inspire further research to enhance retrieval performance for this highly practical task.
Task-Specific Adaptation with Restricted Model Access
Feb 02, 2025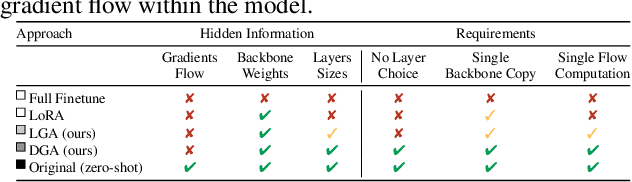
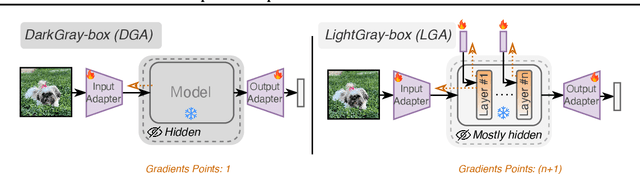
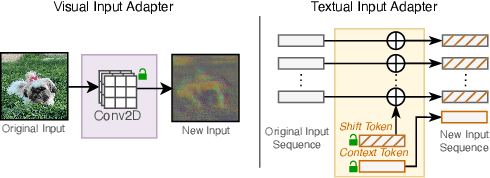
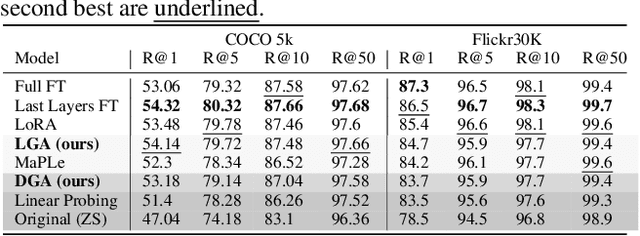
The emergence of foundational models has greatly improved performance across various downstream tasks, with fine-tuning often yielding even better results. However, existing fine-tuning approaches typically require access to model weights and layers, leading to challenges such as managing multiple model copies or inference pipelines, inefficiencies in edge device optimization, and concerns over proprietary rights, privacy, and exposure to unsafe model variants. In this paper, we address these challenges by exploring "Gray-box" fine-tuning approaches, where the model's architecture and weights remain hidden, allowing only gradient propagation. We introduce a novel yet simple and effective framework that adapts to new tasks using two lightweight learnable modules at the model's input and output. Additionally, we present a less restrictive variant that offers more entry points into the model, balancing performance with model exposure. We evaluate our approaches across several backbones on benchmarks such as text-image alignment, text-video alignment, and sketch-image alignment. Results show that our Gray-box approaches are competitive with full-access fine-tuning methods, despite having limited access to the model.
Bringing Objects to Life: 4D generation from 3D objects
Dec 29, 2024Recent advancements in generative modeling now enable the creation of 4D content (moving 3D objects) controlled with text prompts. 4D generation has large potential in applications like virtual worlds, media, and gaming, but existing methods provide limited control over the appearance and geometry of generated content. In this work, we introduce a method for animating user-provided 3D objects by conditioning on textual prompts to guide 4D generation, enabling custom animations while maintaining the identity of the original object. We first convert a 3D mesh into a ``static" 4D Neural Radiance Field (NeRF) that preserves the visual attributes of the input object. Then, we animate the object using an Image-to-Video diffusion model driven by text. To improve motion realism, we introduce an incremental viewpoint selection protocol for sampling perspectives to promote lifelike movement and a masked Score Distillation Sampling (SDS) loss, which leverages attention maps to focus optimization on relevant regions. We evaluate our model in terms of temporal coherence, prompt adherence, and visual fidelity and find that our method outperforms baselines that are based on other approaches, achieving up to threefold improvements in identity preservation measured using LPIPS scores, and effectively balancing visual quality with dynamic content.