 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Transport Flow Matching by Design
Jun 02, 2026Flow matching models learn to transport samples from a simple prior distribution to a complex data distribution. When prior-data pairs are coupled via optimal transport (OT), the learned trajectories are straight and non-crossing, enabling fast, even single-step, generation. However, computing the OT coupling in high dimensions is intractable, and existing methods attempt to solve the OT problem, at the cost of persistent bias or significant overhead. Rather than solving for the OT coupling, we reformulate the problem. Once the prior is treated as a design choice rather than a fixed input, the OT coupling between prior and data is no longer unique. Many priors admit an OT-optimal identity coupling to the data, leaving us free to choose one that is also tractable to sample. We identify low-frequency projection of natural images as such a choice. The identity coupling between data and its low-frequency representation is empirically OT-optimal, the prior is structured enough to be sampled by a lightweight model at inference, and the remaining flow-matching task reduces to synthesizing high-frequency detail. Interpolating the prior with Gaussian noise further improves generation quality while preserving the OT coupling. The approach requires no modifications to the flow model itself, and integrates naturally with latent-space models, classifier-free guidance, and one-step generation frameworks. Across all benchmarks, our method reduces trajectory curvature by more than $2\times$ compared to existing flow matching methods, yielding better generation quality in the few-step regime.
Scene Grounding In the Wild
Mar 27, 2026Reconstructing accurate 3D models of large-scale real-world scenes from unstructured, in-the-wild imagery remains a core challenge in computer vision, especially when the input views have little or no overlap. In such cases, existing reconstruction pipelines often produce multiple disconnected partial reconstructions or erroneously merge non-overlapping regions into overlapping geometry. In this work, we propose a framework that grounds each partial reconstruction to a complete reference model of the scene, enabling globally consistent alignment even in the absence of visual overlap. We obtain reference models from dense, geospatially accurate pseudo-synthetic renderings derived from Google Earth Studio. These renderings provide full scene coverage but differ substantially in appearance from real-world photographs. Our key insight is that, despite this significant domain gap, both domains share the same underlying scene semantics. We represent the reference model using 3D Gaussian Splatting, augmenting each Gaussian with semantic features, and formulate alignment as an inverse feature-based optimization scheme that estimates a global 6DoF pose and scale while keeping the reference model fixed. Furthermore, we introduce the WikiEarth dataset, which registers existing partial 3D reconstructions with pseudo-synthetic reference models. We demonstrate that our approach consistently improves global alignment when initialized with various classical and learning-based pipelines, while mitigating failure modes of state-of-the-art end-to-end models. All code and data will be released.
DeepShare: Sharing ReLU Across Channels and Layers for Efficient Private Inference
Dec 19, 2025



Private Inference (PI) uses cryptographic primitives to perform privacy preserving machine learning. In this setting, the owner of the network runs inference on the data of the client without learning anything about the data and without revealing any information about the model. It has been observed that a major computational bottleneck of PI is the calculation of the gate (i.e., ReLU), so a considerable amount of effort have been devoted to reducing the number of ReLUs in a given network. We focus on the DReLU, which is the non-linear step function of the ReLU and show that one DReLU can serve many ReLU operations. We suggest a new activation module where the DReLU operation is only performed on a subset of the channels (Prototype channels), while the rest of the channels (replicate channels) replicates the DReLU of each of their neurons from the corresponding neurons in one of the prototype channels. We then extend this idea to work across different layers. We show that this formulation can drastically reduce the number of DReLU operations in resnet type network. Furthermore, our theoretical analysis shows that this new formulation can solve an extended version of the XOR problem, using just one non-linearity and two neurons, something that traditional formulations and some PI specific methods cannot achieve. We achieve new SOTA results on several classification setups, and achieve SOTA results on image segmentation.
Multi-View Foundation Models
Dec 17, 2025



Foundation models are vital tools in various Computer Vision applications. They take as input a single RGB image and output a deep feature representation that is useful for various applications. However, in case we have multiple views of the same 3D scene, they operate on each image independently and do not always produce consistent features for the same 3D point. We propose a way to convert a Foundation Model into a Multi-View Foundation Model. Such a model takes as input a set of images and outputs a feature map for each image such that the features of corresponding points are as consistent as possible. This approach bypasses the need to build a consistent 3D model of the features and allows direct manipulation in the image space. Specifically, we show how to augment Transformers-based foundation models (i.e., DINO, SAM, CLIP) with intermediate 3D-aware attention layers that help match features across different views. As leading examples, we show surface normal estimation and multi-view segmentation tasks. Quantitative experiments show that our method improves feature matching considerably compared to current foundation models.
Coordinate Descent for Network Linearization
Nov 14, 2025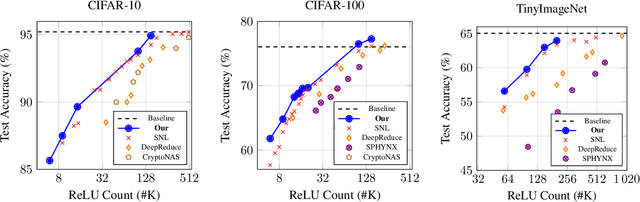
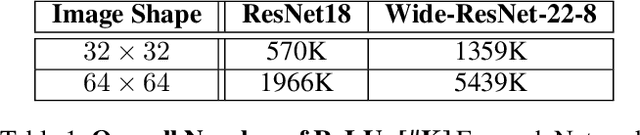
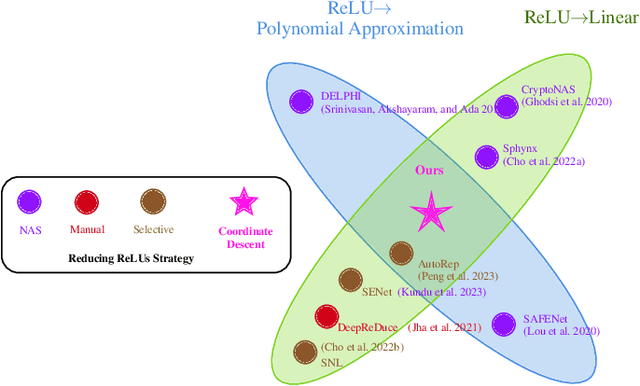
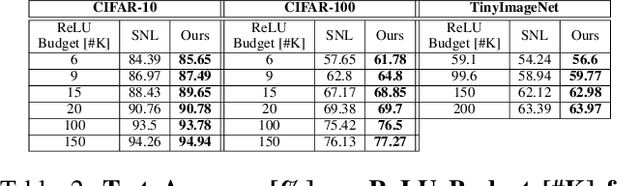
ReLU activations are the main bottleneck in Private Inference that is based on ResNet networks. This is because they incur significant inference latency. Reducing ReLU count is a discrete optimization problem, and there are two common ways to approach it. Most current state-of-the-art methods are based on a smooth approximation that jointly optimizes network accuracy and ReLU budget at once. However, the last hard thresholding step of the optimization usually introduces a large performance loss. We take an alternative approach that works directly in the discrete domain by leveraging Coordinate Descent as our optimization framework. In contrast to previous methods, this yields a sparse solution by design. We demonstrate, through extensive experiments, that our method is State of the Art on common benchmarks.
TextureSAM: Towards a Texture Aware Foundation Model for Segmentation
May 22, 2025Segment Anything Models (SAM) have achieved remarkable success in object segmentation tasks across diverse datasets. However, these models are predominantly trained on large-scale semantic segmentation datasets, which introduce a bias toward object shape rather than texture cues in the image. This limitation is critical in domains such as medical imaging, material classification, and remote sensing, where texture changes define object boundaries. In this study, we investigate SAM's bias toward semantics over textures and introduce a new texture-aware foundation model, TextureSAM, which performs superior segmentation in texture-dominant scenarios. To achieve this, we employ a novel fine-tuning approach that incorporates texture augmentation techniques, incrementally modifying training images to emphasize texture features. By leveraging a novel texture-alternation of the ADE20K dataset, we guide TextureSAM to prioritize texture-defined regions, thereby mitigating the inherent shape bias present in the original SAM model. Our extensive experiments demonstrate that TextureSAM significantly outperforms SAM-2 on both natural (+0.2 mIoU) and synthetic (+0.18 mIoU) texture-based segmentation datasets. The code and texture-augmented dataset will be publicly available.
Frequency-Aware Gaussian Splatting Decomposition
Mar 27, 2025



3D Gaussian Splatting (3D-GS) has revolutionized novel view synthesis with its efficient, explicit representation. However, it lacks frequency interpretability, making it difficult to separate low-frequency structures from fine details. We introduce a frequency-decomposed 3D-GS framework that groups 3D Gaussians that correspond to subbands in the Laplacian Pyrmaids of the input images. Our approach enforces coherence within each subband (i.e., group of 3D Gaussians) through dedicated regularization, ensuring well-separated frequency components. We extend color values to both positive and negative ranges, allowing higher-frequency layers to add or subtract residual details. To stabilize optimization, we employ a progressive training scheme that refines details in a coarse-to-fine manner. Beyond interpretability, this frequency-aware design unlocks a range of practical benefits. Explicit frequency separation enables advanced 3D editing and stylization, allowing precise manipulation of specific frequency bands. It also supports dynamic level-of-detail control for progressive rendering, streaming, foveated rendering and fast geometry interaction. Through extensive experiments, we demonstrate that our method provides improved control and flexibility for emerging applications in scene editing and interactive rendering. Our code will be made publicly available.
Optimize the Unseen -- Fast NeRF Cleanup with Free Space Prior
Dec 18, 2024



Neural Radiance Fields (NeRF) have advanced photorealistic novel view synthesis, but their reliance on photometric reconstruction introduces artifacts, commonly known as "floaters". These artifacts degrade novel view quality, especially in areas unseen by the training cameras. We present a fast, post-hoc NeRF cleanup method that eliminates such artifacts by enforcing our Free Space Prior, effectively minimizing floaters without disrupting the NeRF's representation of observed regions. Unlike existing approaches that rely on either Maximum Likelihood (ML) estimation to fit the data or a complex, local data-driven prior, our method adopts a Maximum-a-Posteriori (MAP) approach, selecting the optimal model parameters under a simple global prior assumption that unseen regions should remain empty. This enables our method to clean artifacts in both seen and unseen areas, enhancing novel view quality even in challenging scene regions. Our method is comparable with existing NeRF cleanup models while being 2.5x faster in inference time, requires no additional memory beyond the original NeRF, and achieves cleanup training in less than 30 seconds. Our code will be made publically available.
Sifting through the haystack -- efficiently finding rare animal behaviors in large-scale datasets
Dec 04, 2024In the study of animal behavior, researchers often record long continuous videos, accumulating into large-scale datasets. However, the behaviors of interest are often rare compared to routine behaviors. This incurs a heavy cost on manual annotation, forcing users to sift through many samples before finding their needles. We propose a pipeline to efficiently sample rare behaviors from large datasets, enabling the creation of training datasets for rare behavior classifiers. Our method only needs an unlabeled animal pose or acceleration dataset as input and makes no assumptions regarding the type, number, or characteristics of the rare behaviors. Our pipeline is based on a recent graph-based anomaly detection model for human behavior, which we apply to this new data domain. It leverages anomaly scores to automatically label normal samples while directing human annotation efforts toward anomalies. In research data, anomalies may come from many different sources (e.g., signal noise versus true rare instances). Hence, the entire labeling budget is focused on the abnormal classes, letting the user review and label samples according to their needs. We tested our approach on three datasets of freely-moving animals, acquired in the laboratory and the field. We found that graph-based models are particularly useful when studying motion-based behaviors in animals, yielding good results while using a small labeling budget. Our method consistently outperformed traditional random sampling, offering an average improvement of 70% in performance and creating datasets even when the behavior of interest was only 0.02% of the data. Even when the performance gain was minor (e.g., when the behavior is not rare), our method still reduced the annotation effort by half
Memories of Forgotten Concepts
Dec 01, 2024



Diffusion models dominate the space of text-to-image generation, yet they may produce undesirable outputs, including explicit content or private data. To mitigate this, concept ablation techniques have been explored to limit the generation of certain concepts. In this paper, we reveal that the erased concept information persists in the model and that erased concept images can be generated using the right latent. Utilizing inversion methods, we show that there exist latent seeds capable of generating high quality images of erased concepts. Moreover, we show that these latents have likelihoods that overlap with those of images outside the erased concept. We extend this to demonstrate that for every image from the erased concept set, we can generate many seeds that generate the erased concept. Given the vast space of latents capable of generating ablated concept images, our results suggest that fully erasing concept information may be intractable, highlighting possible vulnerabilities in current concept ablation techniques.