 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordinate Descent for Network Linearization
Nov 14, 2025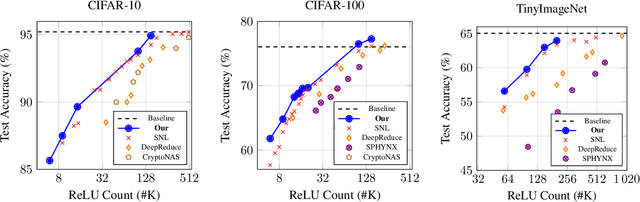
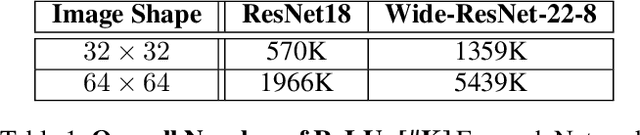
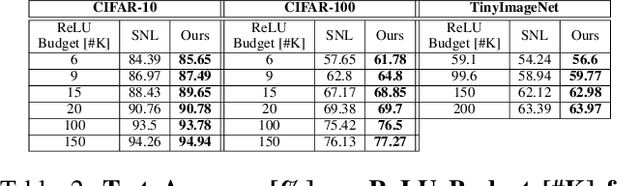
ReLU activations are the main bottleneck in Private Inference that is based on ResNet networks. This is because they incur significant inference latency. Reducing ReLU count is a discrete optimization problem, and there are two common ways to approach it. Most current state-of-the-art methods are based on a smooth approximation that jointly optimizes network accuracy and ReLU budget at once. However, the last hard thresholding step of the optimization usually introduces a large performance loss. We take an alternative approach that works directly in the discrete domain by leveraging Coordinate Descent as our optimization framework. In contrast to previous methods, this yields a sparse solution by design. We demonstrate, through extensive experiments, that our method is State of the Art on common benchmarks.
Memories of Forgotten Concepts
Dec 01, 2024



Diffusion models dominate the space of text-to-image generation, yet they may produce undesirable outputs, including explicit content or private data. To mitigate this, concept ablation techniques have been explored to limit the generation of certain concepts. In this paper, we reveal that the erased concept information persists in the model and that erased concept images can be generated using the right latent. Utilizing inversion methods, we show that there exist latent seeds capable of generating high quality images of erased concepts. Moreover, we show that these latents have likelihoods that overlap with those of images outside the erased concept. We extend this to demonstrate that for every image from the erased concept set, we can generate many seeds that generate the erased concept. Given the vast space of latents capable of generating ablated concept images, our results suggest that fully erasing concept information may be intractable, highlighting possible vulnerabilities in current concept ablation techniques.
Optimize and Reduce: A Top-Down Approach for Image Vectorization
Dec 18, 2023Vector image representation is a popular choice when editability and flexibility in resolution are desired. However, most images are only available in raster form, making raster-to-vector image conversion (vectorization) an important task. Classical methods for vectorization are either domain-specific or yield an abundance of shapes which limits editability and interpretability. Learning-based methods, that use differentiable rendering, have revolutionized vectorization, at the cost of poor generalization to out-of-training distribution domains, and optimization-based counterparts are either slow or produce non-editable and redundant shapes. In this work, we propose Optimize & Reduce (O&R), a top-down approach to vectorization that is both fast and domain-agnostic. O&R aims to attain a compact representation of input images by iteratively optimizing B\'ezier curve parameters and significantly reducing the number of shapes, using a devised importance measure. We contribute a benchmark of five datasets comprising images from a broad spectrum of image complexities - from emojis to natural-like images. Through extensive experiments on hundreds of images, we demonstrate that our method is domain agnostic and outperforms existing works in both reconstruction and perceptual quality for a fixed number of shapes. Moreover, we show that our algorithm is $\times 10$ faster than the state-of-the-art optimization-based method.
Aggregating Layers for Deepfake Detection
Oct 11, 2022

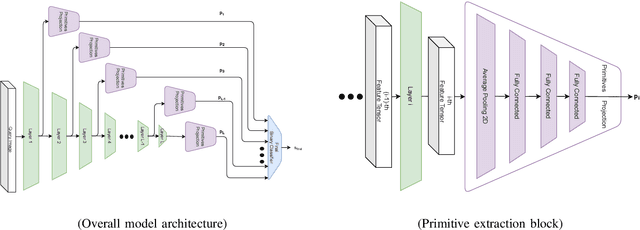
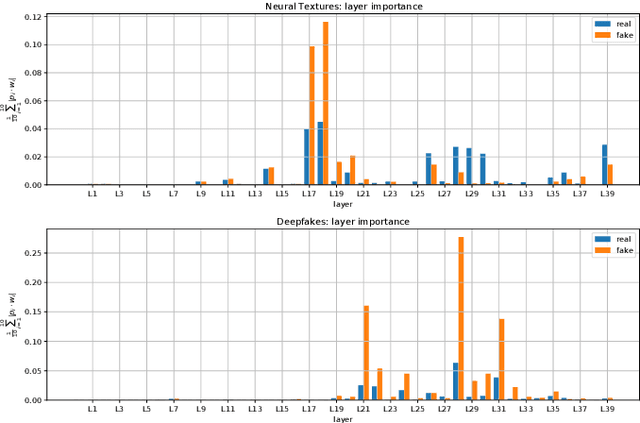
The increasing popularity of facial manipulation (Deepfakes) and synthetic face creation raises the need to develop robust forgery detection solutions. Crucially, most work in this domain assume that the Deepfakes in the test set come from the same Deepfake algorithms that were used for training the network. This is not how things work in practice. Instead, we consider the case where the network is trained on one Deepfake algorithm, and tested on Deepfakes generated by another algorithm. Typically, supervised techniques follow a pipeline of visual feature extraction from a deep backbone, followed by a binary classification head. Instead, our algorithm aggregates features extracted across all layers of one backbone network to detect a fake. We evaluate our approach on two domains of interest - Deepfake detection and Synthetic image detection, and find that we achieve SOTA results.