 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCopy-Trasform-Paste: Zero-Shot Object-Object Alignment Guided by Vision-Language and Geometric Constraints
Jan 20, 2026We study zero-shot 3D alignment of two given meshes, using a text prompt describing their spatial relation -- an essential capability for content creation and scene assembly. Earlier approaches primarily rely on geometric alignment procedures, while recent work leverages pretrained 2D diffusion models to model language-conditioned object-object spatial relationships. In contrast, we directly optimize the relative pose at test time, updating translation, rotation, and isotropic scale with CLIP-driven gradients via a differentiable renderer, without training a new model. Our framework augments language supervision with geometry-aware objectives: a variant of soft-Iterative Closest Point (ICP) term to encourage surface attachment and a penetration loss to discourage interpenetration. A phased schedule strengthens contact constraints over time, and camera control concentrates the optimization on the interaction region. To enable evaluation, we curate a benchmark containing diverse categories and relations, and compare against baselines. Our method outperforms all alternatives, yielding semantically faithful and physically plausible alignments.
Express4D: Expressive, Friendly, and Extensible 4D Facial Motion Generation Benchmark
Aug 17, 2025Dynamic facial expression generation from natural language is a crucial task in Computer Graphics, with applications in Animation, Virtual Avatars, and Human-Computer Interaction. However, current generative models suffer from datasets that are either speech-driven or limited to coarse emotion labels, lacking the nuanced, expressive descriptions needed for fine-grained control, and were captured using elaborate and expensive equipment. We hence present a new dataset of facial motion sequences featuring nuanced performances and semantic annotation. The data is easily collected using commodity equipment and LLM-generated natural language instructions, in the popular ARKit blendshape format. This provides riggable motion, rich with expressive performances and labels. We accordingly train two baseline models, and evaluate their performance for future benchmarking. Using our Express4D dataset, the trained models can learn meaningful text-to-expression motion generation and capture the many-to-many mapping of the two modalities. The dataset, code, and video examples are available on our webpage: https://jaron1990.github.io/Express4D/
REED-VAE: RE-Encode Decode Training for Iterative Image Editing with Diffusion Models
Apr 26, 2025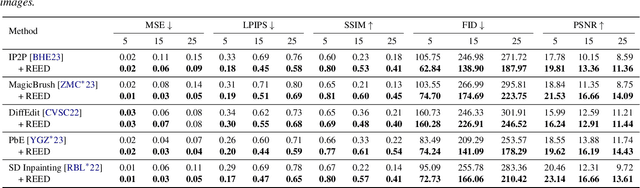



While latent diffusion models achieve impressive image editing results, their application to iterative editing of the same image is severely restricted. When trying to apply consecutive edit operations using current models, they accumulate artifacts and noise due to repeated transitions between pixel and latent spaces. Some methods have attempted to address this limitation by performing the entire edit chain within the latent space, sacrificing flexibility by supporting only a limited, predetermined set of diffusion editing operations. We present a RE-encode decode (REED) training scheme for variational autoencoders (VAEs), which promotes image quality preservation even after many iterations. Our work enables multi-method iterative image editing: users can perform a variety of iterative edit operations, with each operation building on the output of the previous one using both diffusion-based operations and conventional editing techniques. We demonstrate the advantage of REED-VAE across a range of image editing scenarios, including text-based and mask-based editing frameworks. In addition, we show how REED-VAE enhances the overall editability of images, increasing the likelihood of successful and precise edit operations. We hope that this work will serve as a benchmark for the newly introduced task of multi-method image editing. Our code and models will be available at https://github.com/galmog/REED-VAE
ImageRAG: Dynamic Image Retrieval for Reference-Guided Image Generation
Feb 13, 2025


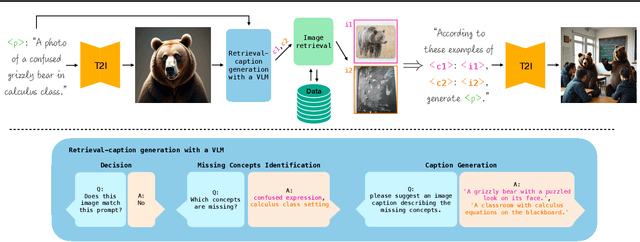
Diffusion models enable high-quality and diverse visual content synthesis. However, they struggle to generate rare or unseen concepts. To address this challenge, we explore the usage of Retrieval-Augmented Generation (RAG) with image generation models. We propose ImageRAG, a method that dynamically retrieves relevant images based on a given text prompt, and uses them as context to guide the generation process. Prior approaches that used retrieved images to improve generation, trained models specifically for retrieval-based generation. In contrast, ImageRAG leverages the capabilities of existing image conditioning models, and does not require RAG-specific training. Our approach is highly adaptable and can be applied across different model types, showing significant improvement in generating rare and fine-grained concepts using different base models. Our project page is available at: https://rotem-shalev.github.io/ImageRAG
Tiled Diffusion
Dec 19, 2024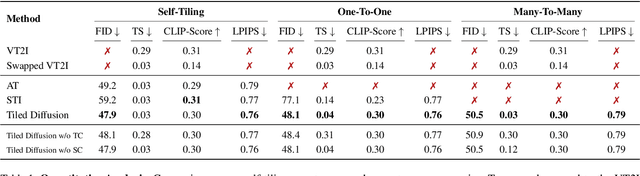
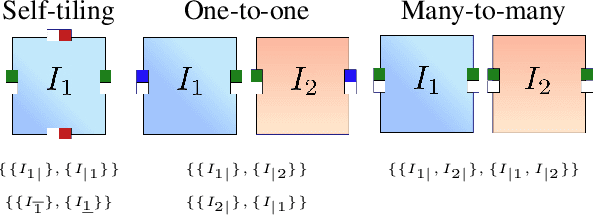


Image tiling -- the seamless connection of disparate images to create a coherent visual field -- is crucial for applications such as texture creation, video game asset development, and digital art. Traditionally, tiles have been constructed manually, a method that poses significant limitations in scalability and flexibility. Recent research has attempted to automate this process using generative models. However, current approaches primarily focus on tiling textures and manipulating models for single-image generation, without inherently supporting the creation of multiple interconnected tiles across diverse domains. This paper presents Tiled Diffusion, a novel approach that extends the capabilities of diffusion models to accommodate the generation of cohesive tiling patterns across various domains of image synthesis that require tiling. Our method supports a wide range of tiling scenarios, from self-tiling to complex many-to-many connections, enabling seamless integration of multiple images. Tiled Diffusion automates the tiling process, eliminating the need for manual intervention and enhancing creative possibilities in various applications, such as seamlessly tiling of existing images, tiled texture creation, and 360{\deg} synthesis.
Memories of Forgotten Concepts
Dec 01, 2024



Diffusion models dominate the space of text-to-image generation, yet they may produce undesirable outputs, including explicit content or private data. To mitigate this, concept ablation techniques have been explored to limit the generation of certain concepts. In this paper, we reveal that the erased concept information persists in the model and that erased concept images can be generated using the right latent. Utilizing inversion methods, we show that there exist latent seeds capable of generating high quality images of erased concepts. Moreover, we show that these latents have likelihoods that overlap with those of images outside the erased concept. We extend this to demonstrate that for every image from the erased concept set, we can generate many seeds that generate the erased concept. Given the vast space of latents capable of generating ablated concept images, our results suggest that fully erasing concept information may be intractable, highlighting possible vulnerabilities in current concept ablation techniques.
Stable Flow: Vital Layers for Training-Free Image Editing
Nov 21, 2024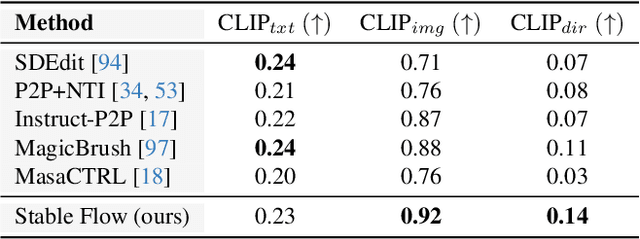

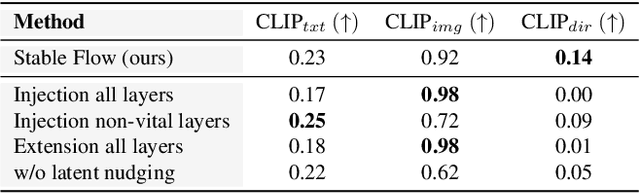
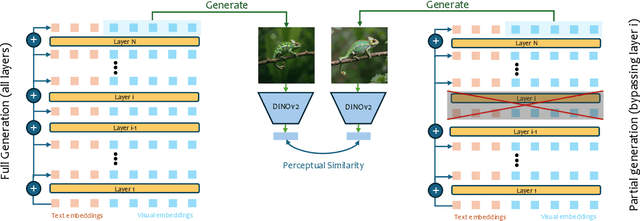
Diffusion models have revolutionized the field of content synthesis and editing. Recent models have replaced the traditional UNet architecture with the Diffusion Transformer (DiT), and employed flow-matching for improved training and sampling. However, they exhibit limited generation diversity. In this work, we leverage this limitation to perform consistent image edits via selective injection of attention features. The main challenge is that, unlike the UNet-based models, DiT lacks a coarse-to-fine synthesis structure, making it unclear in which layers to perform the injection. Therefore, we propose an automatic method to identify "vital layers" within DiT, crucial for image formation, and demonstrate how these layers facilitate a range of controlled stable edits, from non-rigid modifications to object addition, using the same mechanism. Next, to enable real-image editing, we introduce an improved image inversion method for flow models. Finally, we evaluate our approach through qualitative and quantitative comparisons, along with a user study, and demonstrate its effectiveness across multiple applications. The project page is available at https://omriavrahami.com/stable-flow
V-LASIK: Consistent Glasses-Removal from Videos Using Synthetic Data
Jun 20, 2024Diffusion-based generative models have recently shown remarkable image and video editing capabilities. However, local video editing, particularly removal of small attributes like glasses, remains a challenge. Existing methods either alter the videos excessively, generate unrealistic artifacts, or fail to perform the requested edit consistently throughout the video. In this work, we focus on consistent and identity-preserving removal of glasses in videos, using it as a case study for consistent local attribute removal in videos. Due to the lack of paired data, we adopt a weakly supervised approach and generate synthetic imperfect data, using an adjusted pretrained diffusion model. We show that despite data imperfection, by learning from our generated data and leveraging the prior of pretrained diffusion models, our model is able to perform the desired edit consistently while preserving the original video content. Furthermore, we exemplify the generalization ability of our method to other local video editing tasks by applying it successfully to facial sticker-removal. Our approach demonstrates significant improvement over existing methods, showcasing the potential of leveraging synthetic data and strong video priors for local video editing tasks.
Advancing Fine-Grained Classification by Structure and Subject Preserving Augmentation
Jun 20, 2024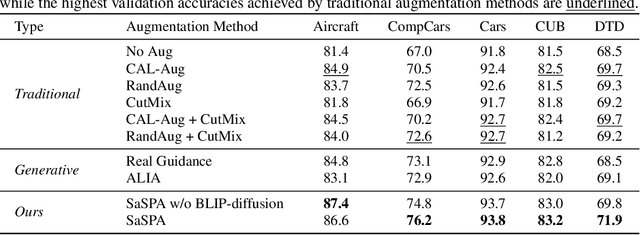
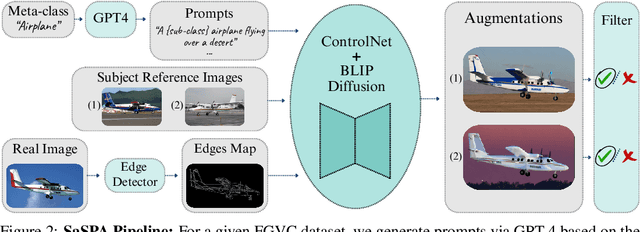
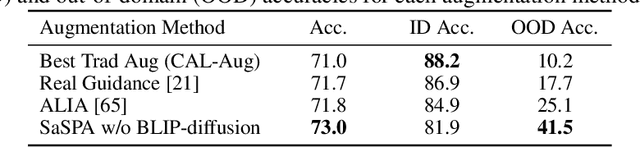

Fine-grained visual classification (FGVC) involves classifying closely related sub-classes. This task is difficult due to the subtle differences between classes and the high intra-class variance. Moreover, FGVC datasets are typically small and challenging to gather, thus highlighting a significant need for effective data augmentation. Recent advancements in text-to-image diffusion models offer new possibilities for augmenting classification datasets. While these models have been used to generate training data for classification tasks, their effectiveness in full-dataset training of FGVC models remains under-explored. Recent techniques that rely on Text2Image generation or Img2Img methods, often struggle to generate images that accurately represent the class while modifying them to a degree that significantly increases the dataset's diversity. To address these challenges, we present SaSPA: Structure and Subject Preserving Augmentation. Contrary to recent methods, our method does not use real images as guidance, thereby increasing generation flexibility and promoting greater diversity. To ensure accurate class representation, we employ conditioning mechanisms, specifically by conditioning on image edges and subject representation. We conduct extensive experiments and benchmark SaSPA against both traditional and recent generative data augmentation methods. SaSPA consistently outperforms all established baselines across multiple settings, including full dataset training, contextual bias, and few-shot classification. Additionally, our results reveal interesting patterns in using synthetic data for FGVC models; for instance, we find a relationship between the amount of real data used and the optimal proportion of synthetic data. Code is available at https://github.com/EyalMichaeli/SaSPA-Aug.
Monkey See, Monkey Do: Harnessing Self-attention in Motion Diffusion for Zero-shot Motion Transfer
Jun 10, 2024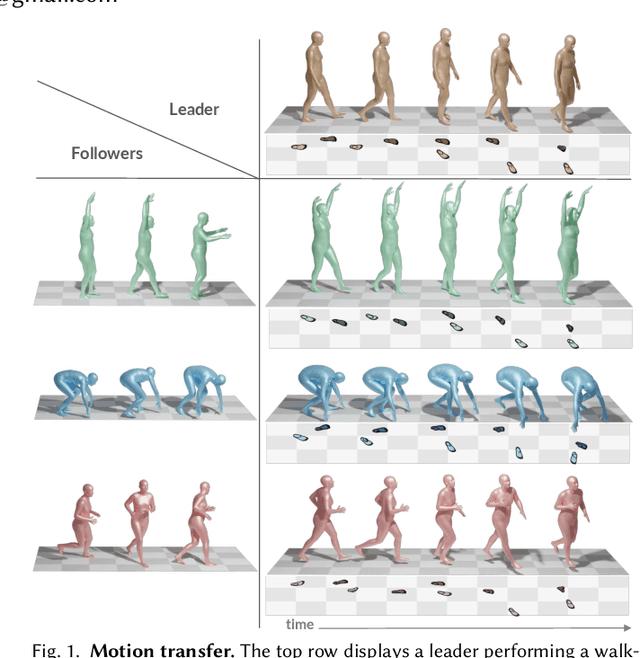
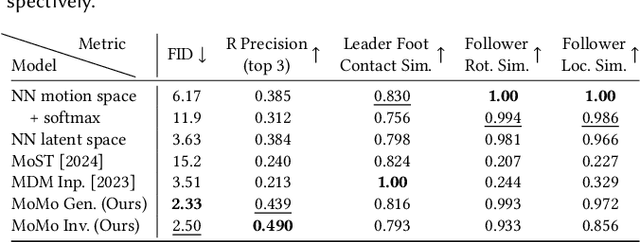
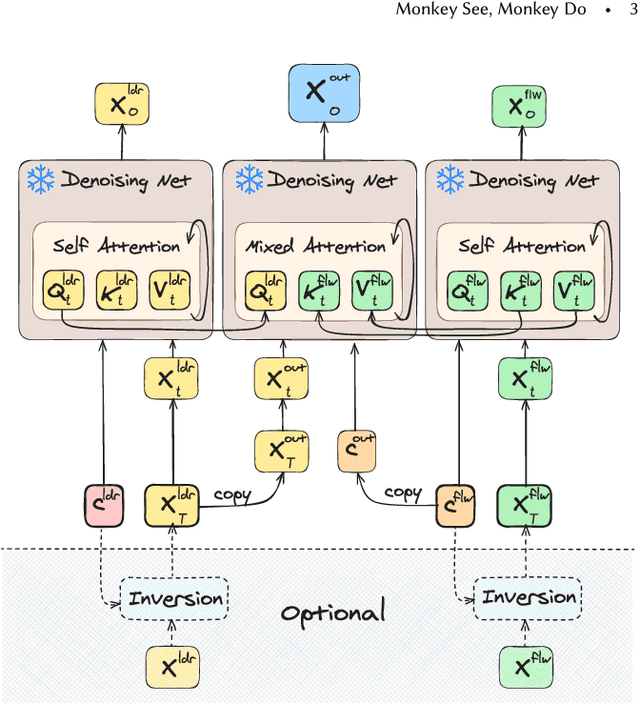
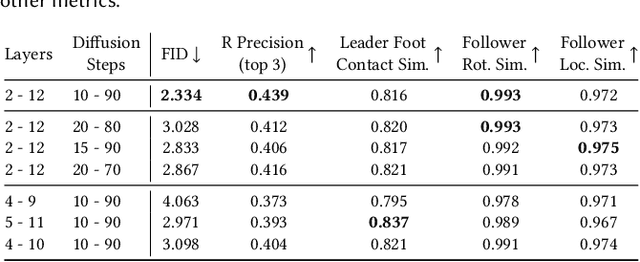
Given the remarkable results of motion synthesis with diffusion models, a natural question arises: how can we effectively leverage these models for motion editing? Existing diffusion-based motion editing methods overlook the profound potential of the prior embedded within the weights of pre-trained models, which enables manipulating the latent feature space; hence, they primarily center on handling the motion space. In this work, we explore the attention mechanism of pre-trained motion diffusion models. We uncover the roles and interactions of attention elements in capturing and representing intricate human motion patterns, and carefully integrate these elements to transfer a leader motion to a follower one while maintaining the nuanced characteristics of the follower, resulting in zero-shot motion transfer. Editing features associated with selected motions allows us to confront a challenge observed in prior motion diffusion approaches, which use general directives (e.g., text, music) for editing, ultimately failing to convey subtle nuances effectively. Our work is inspired by how a monkey closely imitates what it sees while maintaining its unique motion patterns; hence we call it Monkey See, Monkey Do, and dub it MoMo. Employing our technique enables accomplishing tasks such as synthesizing out-of-distribution motions, style transfer, and spatial editing. Furthermore, diffusion inversion is seldom employed for motions; as a result, editing efforts focus on generated motions, limiting the editability of real ones. MoMo harnesses motion inversion, extending its application to both real and generated motions. Experimental results show the advantage of our approach over the current art. In particular, unlike methods tailored for specific applications through training, our approach is applied at inference time, requiring no training. Our webpage is at https://monkeyseedocg.github.io.