 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyTop: Character Animation Diffusion with Any Topology
Feb 24, 2025Generating motion for arbitrary skeletons is a longstanding challenge in computer graphics, remaining largely unexplored due to the scarcity of diverse datasets and the irregular nature of the data. In this work, we introduce AnyTop, a diffusion model that generates motions for diverse characters with distinct motion dynamics, using only their skeletal structure as input. Our work features a transformer-based denoising network, tailored for arbitrary skeleton learning, integrating topology information into the traditional attention mechanism. Additionally, by incorporating textual joint descriptions into the latent feature representation, AnyTop learns semantic correspondences between joints across diverse skeletons. Our evaluation demonstrates that AnyTop generalizes well, even with as few as three training examples per topology, and can produce motions for unseen skeletons as well. Furthermore, our model's latent space is highly informative, enabling downstream tasks such as joint correspondence, temporal segmentation and motion editing. Our webpage, https://anytop2025.github.io/Anytop-page, includes links to videos and code.
CLoSD: Closing the Loop between Simulation and Diffusion for multi-task character control
Oct 04, 2024



Motion diffusion models and Reinforcement Learning (RL) based control for physics-based simulations have complementary strengths for human motion generation. The former is capable of generating a wide variety of motions, adhering to intuitive control such as text, while the latter offers physically plausible motion and direct interaction with the environment. In this work, we present a method that combines their respective strengths. CLoSD is a text-driven RL physics-based controller, guided by diffusion generation for various tasks. Our key insight is that motion diffusion can serve as an on-the-fly universal planner for a robust RL controller. To this end, CLoSD maintains a closed-loop interaction between two modules -- a Diffusion Planner (DiP), and a tracking controller. DiP is a fast-responding autoregressive diffusion model, controlled by textual prompts and target locations, and the controller is a simple and robust motion imitator that continuously receives motion plans from DiP and provides feedback from the environment. CLoSD is capable of seamlessly performing a sequence of different tasks, including navigation to a goal location, striking an object with a hand or foot as specified in a text prompt, sitting down, and getting up. https://guytevet.github.io/CLoSD-page/
Monkey See, Monkey Do: Harnessing Self-attention in Motion Diffusion for Zero-shot Motion Transfer
Jun 10, 2024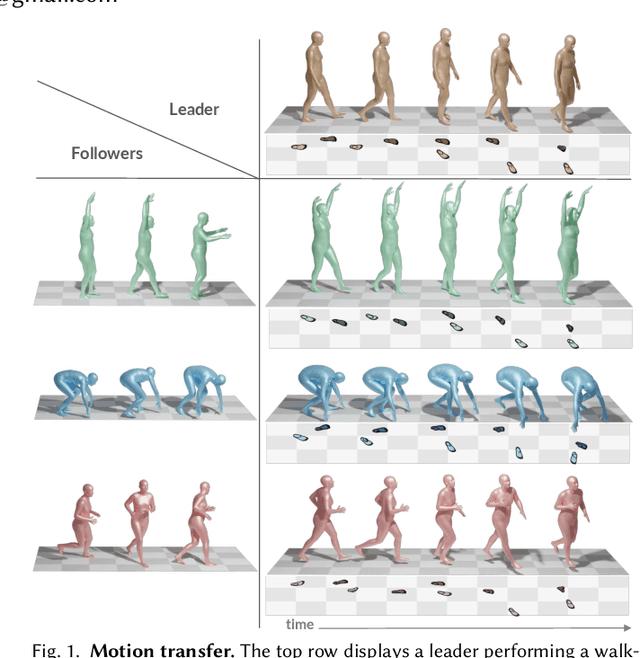
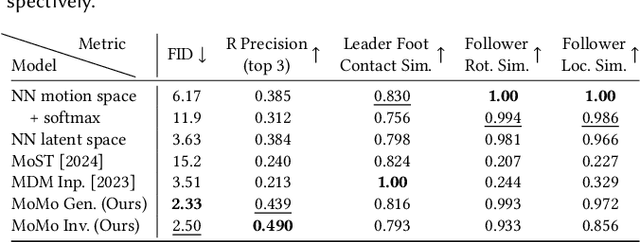
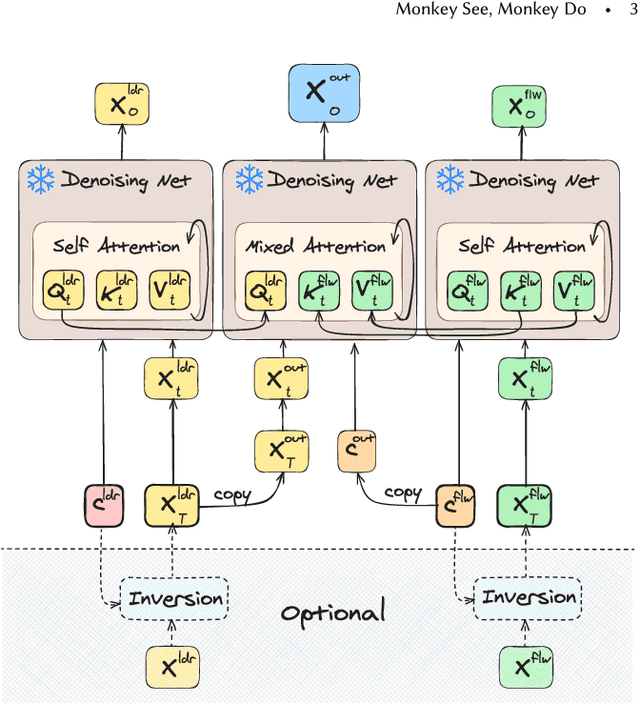
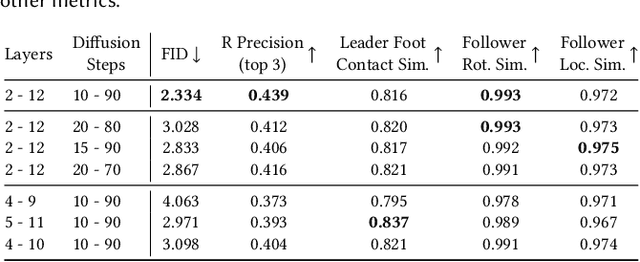
Given the remarkable results of motion synthesis with diffusion models, a natural question arises: how can we effectively leverage these models for motion editing? Existing diffusion-based motion editing methods overlook the profound potential of the prior embedded within the weights of pre-trained models, which enables manipulating the latent feature space; hence, they primarily center on handling the motion space. In this work, we explore the attention mechanism of pre-trained motion diffusion models. We uncover the roles and interactions of attention elements in capturing and representing intricate human motion patterns, and carefully integrate these elements to transfer a leader motion to a follower one while maintaining the nuanced characteristics of the follower, resulting in zero-shot motion transfer. Editing features associated with selected motions allows us to confront a challenge observed in prior motion diffusion approaches, which use general directives (e.g., text, music) for editing, ultimately failing to convey subtle nuances effectively. Our work is inspired by how a monkey closely imitates what it sees while maintaining its unique motion patterns; hence we call it Monkey See, Monkey Do, and dub it MoMo. Employing our technique enables accomplishing tasks such as synthesizing out-of-distribution motions, style transfer, and spatial editing. Furthermore, diffusion inversion is seldom employed for motions; as a result, editing efforts focus on generated motions, limiting the editability of real ones. MoMo harnesses motion inversion, extending its application to both real and generated motions. Experimental results show the advantage of our approach over the current art. In particular, unlike methods tailored for specific applications through training, our approach is applied at inference time, requiring no training. Our webpage is at https://monkeyseedocg.github.io.
Single Motion Diffusion
Feb 12, 2023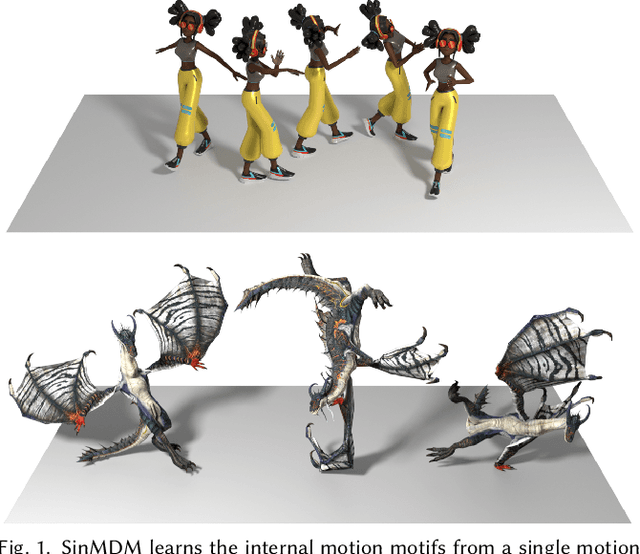
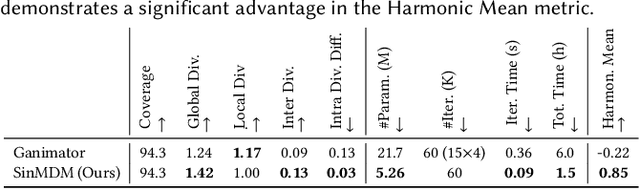
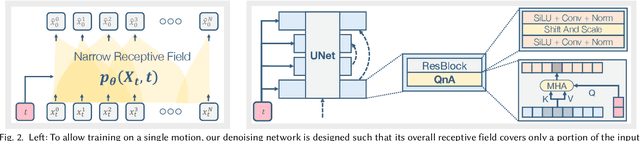
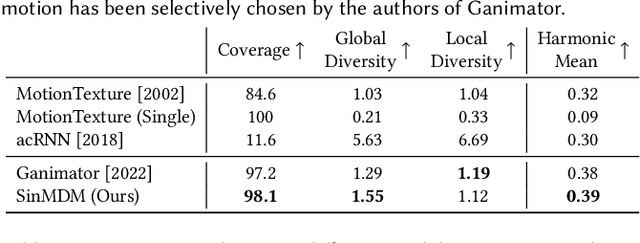
Synthesizing realistic animations of humans, animals, and even imaginary creatures, has long been a goal for artists and computer graphics professionals. Compared to the imaging domain, which is rich with large available datasets, the number of data instances for the motion domain is limited, particularly for the animation of animals and exotic creatures (e.g., dragons), which have unique skeletons and motion patterns. In this work, we present a Single Motion Diffusion Model, dubbed SinMDM, a model designed to learn the internal motifs of a single motion sequence with arbitrary topology and synthesize motions of arbitrary length that are faithful to them. We harness the power of diffusion models and present a denoising network designed specifically for the task of learning from a single input motion. Our transformer-based architecture avoids overfitting by using local attention layers that narrow the receptive field, and encourages motion diversity by using relative positional embedding. SinMDM can be applied in a variety of contexts, including spatial and temporal in-betweening, motion expansion, style transfer, and crowd animation. Our results show that SinMDM outperforms existing methods both in quality and time-space efficiency. Moreover, while current approaches require additional training for different applications, our work facilitates these applications at inference time. Our code and trained models are available at https://sinmdm.github.io/SinMDM-page.
Human Motion Diffusion Model
Oct 03, 2022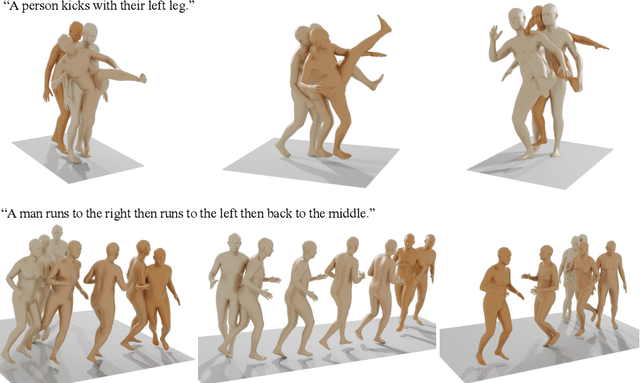
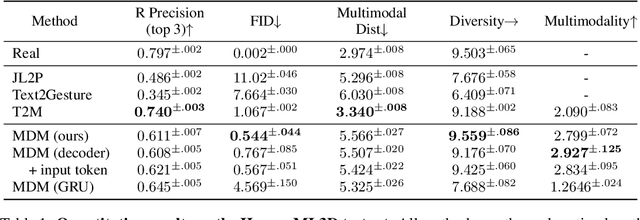
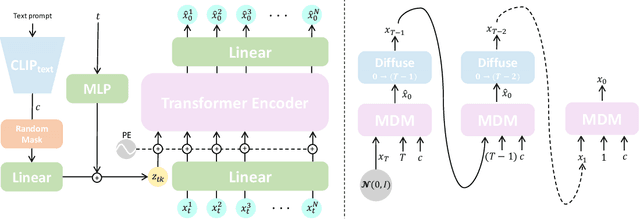
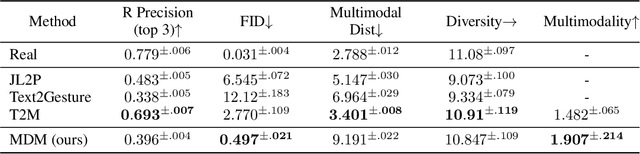
Natural and expressive human motion generation is the holy grail of computer animation. It is a challenging task, due to the diversity of possible motion, human perceptual sensitivity to it, and the difficulty of accurately describing it. Therefore, current generative solutions are either low-quality or limited in expressiveness. Diffusion models, which have already shown remarkable generative capabilities in other domains, are promising candidates for human motion due to their many-to-many nature, but they tend to be resource hungry and hard to control. In this paper, we introduce Motion Diffusion Model (MDM), a carefully adapted classifier-free diffusion-based generative model for the human motion domain. MDM is transformer-based, combining insights from motion generation literature. A notable design-choice is the prediction of the sample, rather than the noise, in each diffusion step. This facilitates the use of established geometric losses on the locations and velocities of the motion, such as the foot contact loss. As we demonstrate, MDM is a generic approach, enabling different modes of conditioning, and different generation tasks. We show that our model is trained with lightweight resources and yet achieves state-of-the-art results on leading benchmarks for text-to-motion and action-to-motion. https://guytevet.github.io/mdm-page/ .
MoDi: Unconditional Motion Synthesis from Diverse Data
Jun 16, 2022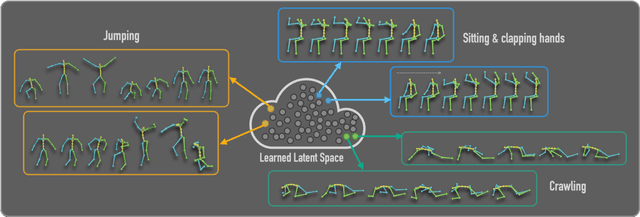
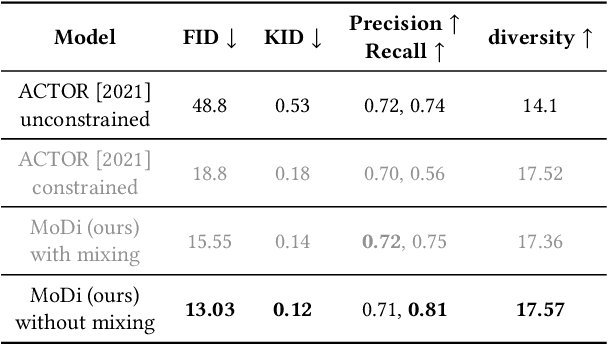
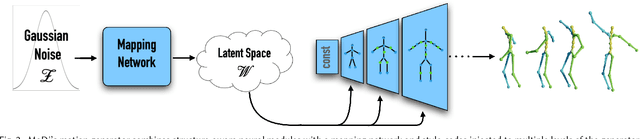
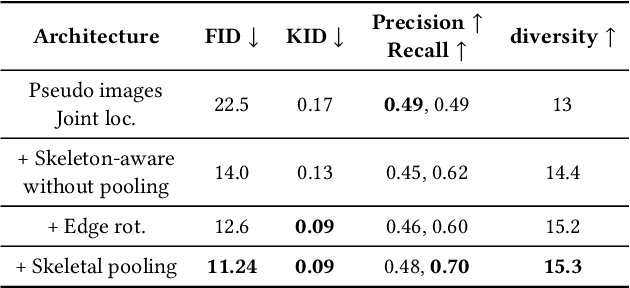
The emergence of neural networks has revolutionized the field of motion synthesis. Yet, learning to unconditionally synthesize motions from a given distribution remains a challenging task, especially when the motions are highly diverse. We present MoDi, an unconditional generative model that synthesizes diverse motions. Our model is trained in a completely unsupervised setting from a diverse, unstructured and unlabeled motion dataset and yields a well-behaved, highly semantic latent space. The design of our model follows the prolific architecture of StyleGAN and adapts two of its key technical components into the motion domain: a set of style-codes injected into each level of the generator hierarchy and a mapping function that learns and forms a disentangled latent space. We show that despite the lack of any structure in the dataset, the latent space can be semantically clustered, and facilitates semantic editing and motion interpolation. In addition, we propose a technique to invert unseen motions into the latent space, and demonstrate latent-based motion editing operations that otherwise cannot be achieved by naive manipulation of explicit motion representations. Our qualitative and quantitative experiments show that our framework achieves state-of-the-art synthesis quality that can follow the distribution of highly diverse motion datasets. Code and trained models will be released at https://sigal-raab.github.io/MoDi.
FLEX: Parameter-free Multi-view 3D Human Motion Reconstruction
May 05, 2021

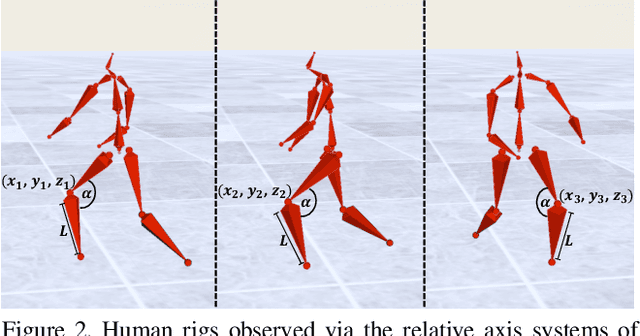
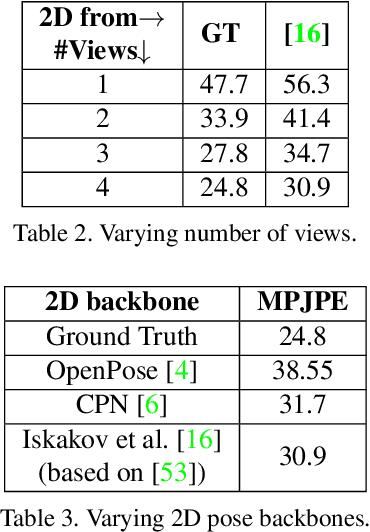
The increasing availability of video recordings made by multiple cameras has offered new means for mitigating occlusion and depth ambiguities in pose and motion reconstruction methods. Yet, multi-view algorithms strongly depend on camera parameters, in particular, the relative positions among the cameras. Such dependency becomes a hurdle once shifting to dynamic capture in uncontrolled settings. We introduce FLEX (Free muLti-view rEconstruXion), an end-to-end parameter-free multi-view model. FLEX is parameter-free in the sense that it does not require any camera parameters, neither intrinsic nor extrinsic. Our key idea is that the 3D angles between skeletal parts, as well as bone lengths, are invariant to the camera position. Hence, learning 3D rotations and bone lengths rather than locations allows predicting common values for all camera views. Our network takes multiple video streams, learns fused deep features through a novel multi-view fusion layer, and reconstructs a single consistent skeleton with temporally coherent joint rotations. We demonstrate quantitative and qualitative results on the Human3.6M and KTH Multi-view Football II datasets. We compare our model to state-of-the-art methods that are not parameter-free and show that in the absence of camera parameters, we outperform them by a large margin while obtaining comparable results when camera parameters are available. Code, trained models, video demonstration, and additional materials will be available on our project page.