 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoDi: Unconditional Motion Synthesis from Diverse Data
Paper and Code
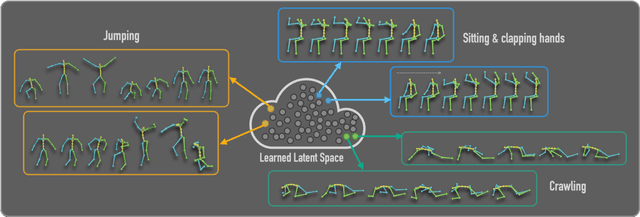
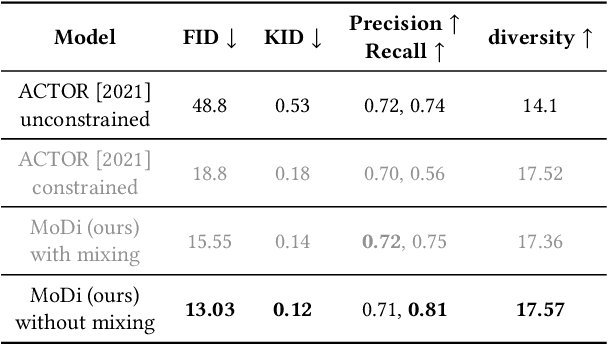
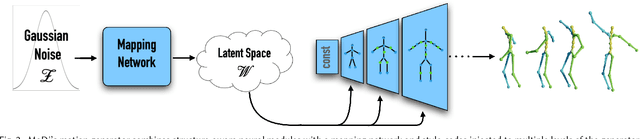
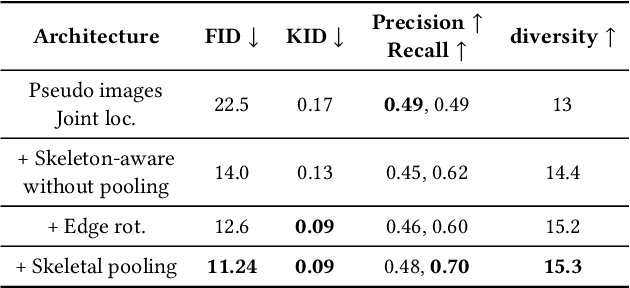
The emergence of neural networks has revolutionized the field of motion synthesis. Yet, learning to unconditionally synthesize motions from a given distribution remains a challenging task, especially when the motions are highly diverse. We present MoDi, an unconditional generative model that synthesizes diverse motions. Our model is trained in a completely unsupervised setting from a diverse, unstructured and unlabeled motion dataset and yields a well-behaved, highly semantic latent space. The design of our model follows the prolific architecture of StyleGAN and adapts two of its key technical components into the motion domain: a set of style-codes injected into each level of the generator hierarchy and a mapping function that learns and forms a disentangled latent space. We show that despite the lack of any structure in the dataset, the latent space can be semantically clustered, and facilitates semantic editing and motion interpolation. In addition, we propose a technique to invert unseen motions into the latent space, and demonstrate latent-based motion editing operations that otherwise cannot be achieved by naive manipulation of explicit motion representations. Our qualitative and quantitative experiments show that our framework achieves state-of-the-art synthesis quality that can follow the distribution of highly diverse motion datasets. Code and trained models will be released at https://sigal-raab.github.io/MoDi.