 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Control of Editing Models via Adaptive-Origin Guidance
Feb 03, 2026Diffusion-based editing models have emerged as a powerful tool for semantic image and video manipulation. However, existing models lack a mechanism for smoothly controlling the intensity of text-guided edits. In standard text-conditioned generation, Classifier-Free Guidance (CFG) impacts prompt adherence, suggesting it as a potential control for edit intensity in editing models. However, we show that scaling CFG in these models does not produce a smooth transition between the input and the edited result. We attribute this behavior to the unconditional prediction, which serves as the guidance origin and dominates the generation at low guidance scales, while representing an arbitrary manipulation of the input content. To enable continuous control, we introduce Adaptive-Origin Guidance (AdaOr), a method that adjusts this standard guidance origin with an identity-conditioned adaptive origin, using an identity instruction corresponding to the identity manipulation. By interpolating this identity prediction with the standard unconditional prediction according to the edit strength, we ensure a continuous transition from the input to the edited result. We evaluate our method on image and video editing tasks, demonstrating that it provides smoother and more consistent control compared to current slider-based editing approaches. Our method incorporates an identity instruction into the standard training framework, enabling fine-grained control at inference time without per-edit procedure or reliance on specialized datasets.
Scaling Group Inference for Diverse and High-Quality Generation
Aug 21, 2025Generative models typically sample outputs independently, and recent inference-time guidance and scaling algorithms focus on improving the quality of individual samples. However, in real-world applications, users are often presented with a set of multiple images (e.g., 4-8) for each prompt, where independent sampling tends to lead to redundant results, limiting user choices and hindering idea exploration. In this work, we introduce a scalable group inference method that improves both the diversity and quality of a group of samples. We formulate group inference as a quadratic integer assignment problem: candidate outputs are modeled as graph nodes, and a subset is selected to optimize sample quality (unary term) while maximizing group diversity (binary term). To substantially improve runtime efficiency, we progressively prune the candidate set using intermediate predictions, allowing our method to scale up to large candidate sets. Extensive experiments show that our method significantly improves group diversity and quality compared to independent sampling baselines and recent inference algorithms. Our framework generalizes across a wide range of tasks, including text-to-image, image-to-image, image prompting, and video generation, enabling generative models to treat multiple outputs as cohesive groups rather than independent samples.
Zero-Shot Dynamic Concept Personalization with Grid-Based LoRA
Jul 23, 2025
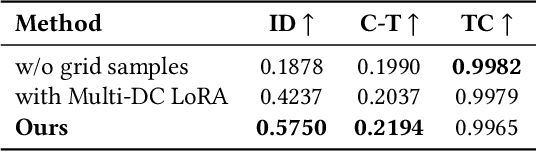
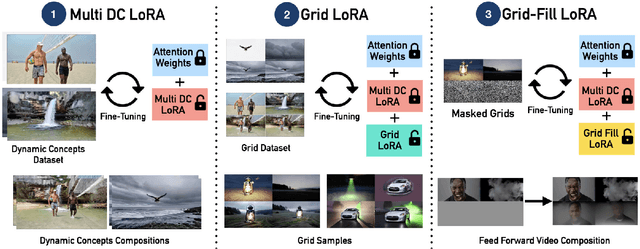
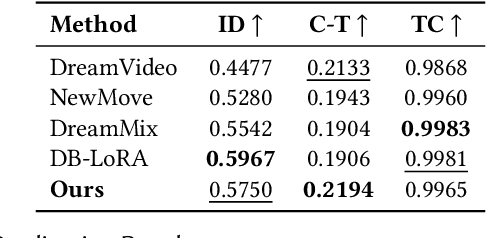
Recent advances in text-to-video generation have enabled high-quality synthesis from text and image prompts. While the personalization of dynamic concepts, which capture subject-specific appearance and motion from a single video, is now feasible, most existing methods require per-instance fine-tuning, limiting scalability. We introduce a fully zero-shot framework for dynamic concept personalization in text-to-video models. Our method leverages structured 2x2 video grids that spatially organize input and output pairs, enabling the training of lightweight Grid-LoRA adapters for editing and composition within these grids. At inference, a dedicated Grid Fill module completes partially observed layouts, producing temporally coherent and identity preserving outputs. Once trained, the entire system operates in a single forward pass, generalizing to previously unseen dynamic concepts without any test-time optimization. Extensive experiments demonstrate high-quality and consistent results across a wide range of subjects beyond trained concepts and editing scenarios.
Be Decisive: Noise-Induced Layouts for Multi-Subject Generation
May 27, 2025Generating multiple distinct subjects remains a challenge for existing text-to-image diffusion models. Complex prompts often lead to subject leakage, causing inaccuracies in quantities, attributes, and visual features. Preventing leakage among subjects necessitates knowledge of each subject's spatial location. Recent methods provide these spatial locations via an external layout control. However, enforcing such a prescribed layout often conflicts with the innate layout dictated by the sampled initial noise, leading to misalignment with the model's prior. In this work, we introduce a new approach that predicts a spatial layout aligned with the prompt, derived from the initial noise, and refines it throughout the denoising process. By relying on this noise-induced layout, we avoid conflicts with externally imposed layouts and better preserve the model's prior. Our method employs a small neural network to predict and refine the evolving noise-induced layout at each denoising step, ensuring clear boundaries between subjects while maintaining consistency. Experimental results show that this noise-aligned strategy achieves improved text-image alignment and more stable multi-subject generation compared to existing layout-guided techniques, while preserving the rich diversity of the model's original distribution.
Dynamic Concepts Personalization from Single Videos
Feb 20, 2025
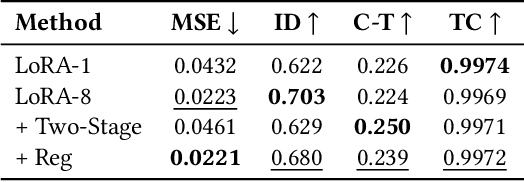
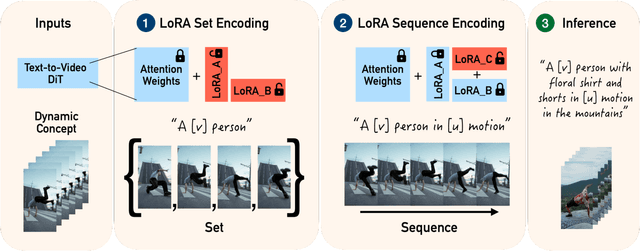
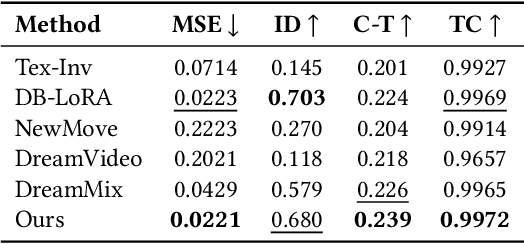
Personalizing generative text-to-image models has seen remarkable progress, but extending this personalization to text-to-video models presents unique challenges. Unlike static concepts, personalizing text-to-video models has the potential to capture dynamic concepts, i.e., entities defined not only by their appearance but also by their motion. In this paper, we introduce Set-and-Sequence, a novel framework for personalizing Diffusion Transformers (DiTs)-based generative video models with dynamic concepts. Our approach imposes a spatio-temporal weight space within an architecture that does not explicitly separate spatial and temporal features. This is achieved in two key stages. First, we fine-tune Low-Rank Adaptation (LoRA) layers using an unordered set of frames from the video to learn an identity LoRA basis that represents the appearance, free from temporal interference. In the second stage, with the identity LoRAs frozen, we augment their coefficients with Motion Residuals and fine-tune them on the full video sequence, capturing motion dynamics. Our Set-and-Sequence framework results in a spatio-temporal weight space that effectively embeds dynamic concepts into the video model's output domain, enabling unprecedented editability and compositionality while setting a new benchmark for personalizing dynamic concepts.
Multi-subject Open-set Personalization in Video Generation
Jan 10, 2025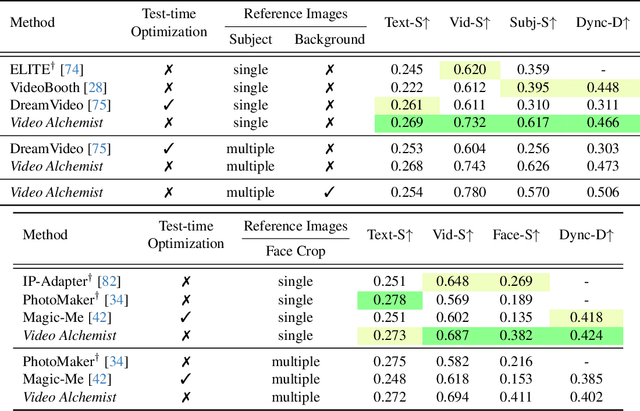
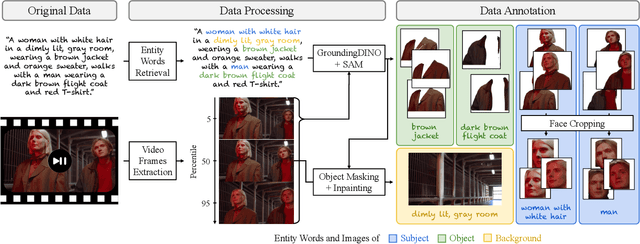
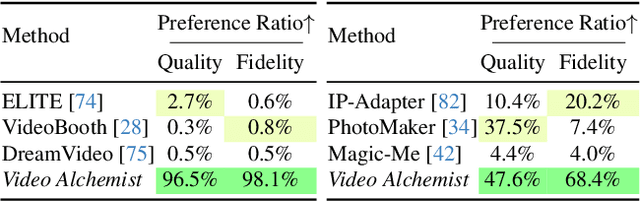
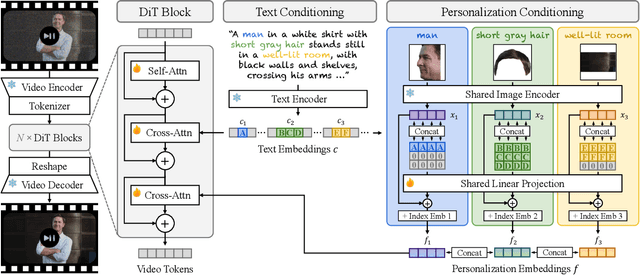
Video personalization methods allow us to synthesize videos with specific concepts such as people, pets, and places. However, existing methods often focus on limited domains, require time-consuming optimization per subject, or support only a single subject. We present Video Alchemist $-$ a video model with built-in multi-subject, open-set personalization capabilities for both foreground objects and background, eliminating the need for time-consuming test-time optimization. Our model is built on a new Diffusion Transformer module that fuses each conditional reference image and its corresponding subject-level text prompt with cross-attention layers. Developing such a large model presents two main challenges: dataset and evaluation. First, as paired datasets of reference images and videos are extremely hard to collect, we sample selected video frames as reference images and synthesize a clip of the target video. However, while models can easily denoise training videos given reference frames, they fail to generalize to new contexts. To mitigate this issue, we design a new automatic data construction pipeline with extensive image augmentations. Second, evaluating open-set video personalization is a challenge in itself. To address this, we introduce a personalization benchmark that focuses on accurate subject fidelity and supports diverse personalization scenarios. Finally, our extensive experiments show that our method significantly outperforms existing personalization methods in both quantitative and qualitative evaluations.
Nested Attention: Semantic-aware Attention Values for Concept Personalization
Jan 02, 2025Personalizing text-to-image models to generate images of specific subjects across diverse scenes and styles is a rapidly advancing field. Current approaches often face challenges in maintaining a balance between identity preservation and alignment with the input text prompt. Some methods rely on a single textual token to represent a subject, which limits expressiveness, while others employ richer representations but disrupt the model's prior, diminishing prompt alignment. In this work, we introduce Nested Attention, a novel mechanism that injects a rich and expressive image representation into the model's existing cross-attention layers. Our key idea is to generate query-dependent subject values, derived from nested attention layers that learn to select relevant subject features for each region in the generated image. We integrate these nested layers into an encoder-based personalization method, and show that they enable high identity preservation while adhering to input text prompts. Our approach is general and can be trained on various domains. Additionally, its prior preservation allows us to combine multiple personalized subjects from different domains in a single image.
Object-level Visual Prompts for Compositional Image Generation
Jan 02, 2025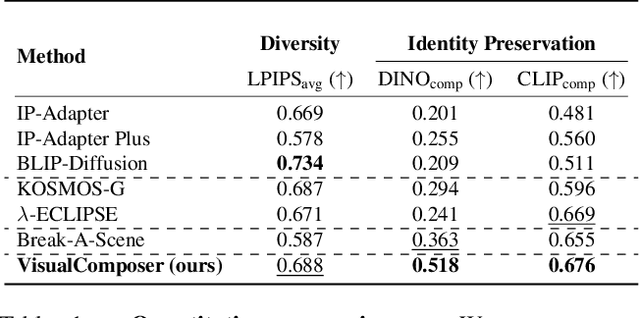


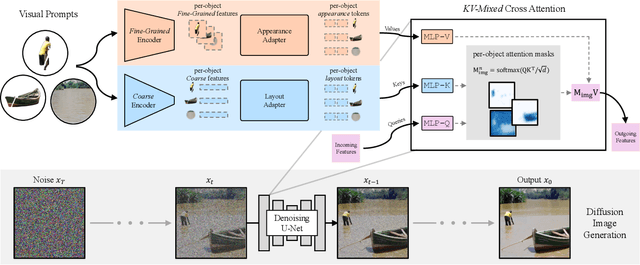
We introduce a method for composing object-level visual prompts within a text-to-image diffusion model. Our approach addresses the task of generating semantically coherent compositions across diverse scenes and styles, similar to the versatility and expressiveness offered by text prompts. A key challenge in this task is to preserve the identity of the objects depicted in the input visual prompts, while also generating diverse compositions across different images. To address this challenge, we introduce a new KV-mixed cross-attention mechanism, in which keys and values are learned from distinct visual representations. The keys are derived from an encoder with a small bottleneck for layout control, whereas the values come from a larger bottleneck encoder that captures fine-grained appearance details. By mixing keys and values from these complementary sources, our model preserves the identity of the visual prompts while supporting flexible variations in object arrangement, pose, and composition. During inference, we further propose object-level compositional guidance to improve the method's identity preservation and layout correctness. Results show that our technique produces diverse scene compositions that preserve the unique characteristics of each visual prompt, expanding the creative potential of text-to-image generation.
Omni-ID: Holistic Identity Representation Designed for Generative Tasks
Dec 12, 2024We introduce Omni-ID, a novel facial representation designed specifically for generative tasks. Omni-ID encodes holistic information about an individual's appearance across diverse expressions and poses within a fixed-size representation. It consolidates information from a varied number of unstructured input images into a structured representation, where each entry represents certain global or local identity features. Our approach uses a few-to-many identity reconstruction training paradigm, where a limited set of input images is used to reconstruct multiple target images of the same individual in various poses and expressions. A multi-decoder framework is further employed to leverage the complementary strengths of diverse decoders during training. Unlike conventional representations, such as CLIP and ArcFace, which are typically learned through discriminative or contrastive objectives, Omni-ID is optimized with a generative objective, resulting in a more comprehensive and nuanced identity capture for generative tasks. Trained on our MFHQ dataset -- a multi-view facial image collection, Omni-ID demonstrates substantial improvements over conventional representations across various generative tasks.
InstantRestore: Single-Step Personalized Face Restoration with Shared-Image Attention
Dec 09, 2024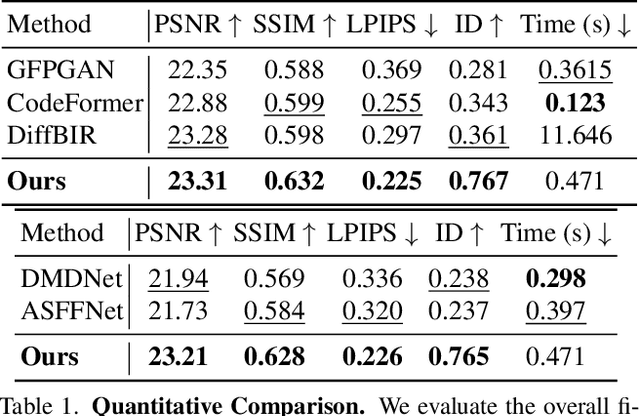
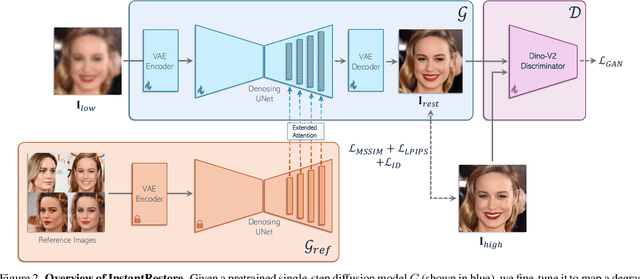
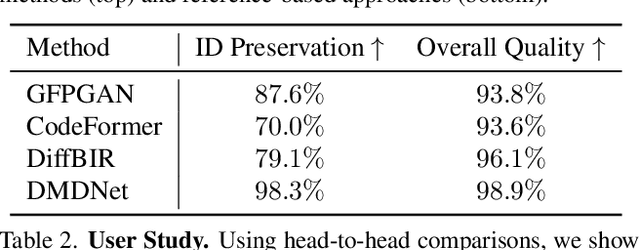
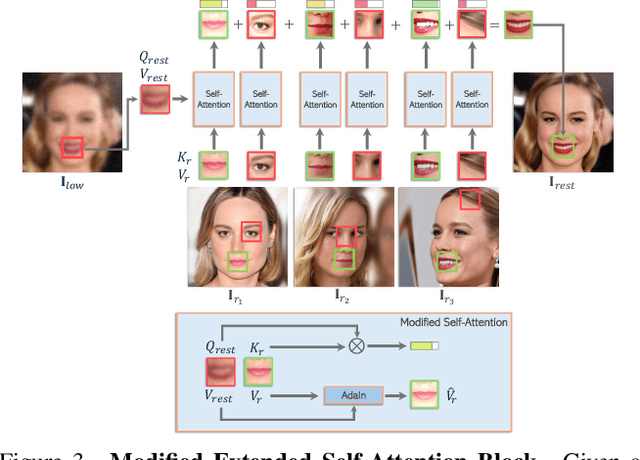
Face image restoration aims to enhance degraded facial images while addressing challenges such as diverse degradation types, real-time processing demands, and, most crucially, the preservation of identity-specific features. Existing methods often struggle with slow processing times and suboptimal restoration, especially under severe degradation, failing to accurately reconstruct finer-level identity details. To address these issues, we introduce InstantRestore, a novel framework that leverages a single-step image diffusion model and an attention-sharing mechanism for fast and personalized face restoration. Additionally, InstantRestore incorporates a novel landmark attention loss, aligning key facial landmarks to refine the attention maps, enhancing identity preservation. At inference time, given a degraded input and a small (~4) set of reference images, InstantRestore performs a single forward pass through the network to achieve near real-time performance. Unlike prior approaches that rely on full diffusion processes or per-identity model tuning, InstantRestore offers a scalable solution suitable for large-scale applications. Extensive experiments demonstrate that InstantRestore outperforms existing methods in quality and speed, making it an appealing choice for identity-preserving face restoration.