 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDash2Sim: Closed-Loop Driving Simulation from in-the-wild Dashcam Videos
Jun 05, 2026Self-driving simulations typically rely on data collected in a small number of cities or on hand-authored synthetic scenarios. Dashcam videos cover a far broader range of locations and situations, including rare or long-tailed scenarios. They are considered less usable for simulation because it is difficult to recover accurate 4D scenes from monocular in-the-wild videos. Work zones are one such class of long-tailed situations that dashcams capture. We present Dash2Sim, a framework that turns in-the-wild monocular dashcam videos into metric, geo-referenced 4D driving logs compatible with existing simulators, and verifies eachone against an independently maintained map without annotations. We apply Dash2Sim to a large video corpus to create the ROADWork4D benchmark dataset, which spans 4,244 scenes with 2.7M 3D objects across 17 cities. On a verified subset ROADWork4D-CL (2,201 scenes), we study privileged closed-loop planners and find that work zone scenarios are difficult: while rule-based and hybrid planners generalize better than learning-based ones, all fall short, failing to make the lane changes that temporary work zone channels require. Beyond planning, dense depth recovered by Dash2Sim improves novel-view synthesis quality by up to 19% on perceptual metrics, suggesting its potential to provide rich conditioning for closed-loop sensor simulation from monocular videos.
Novel View Synthesis as Video Completion
Apr 09, 2026We tackle the problem of sparse novel view synthesis (NVS) using video diffusion models; given $K$ ($\approx 5$) multi-view images of a scene and their camera poses, we predict the view from a target camera pose. Many prior approaches leverage generative image priors encoded via diffusion models. However, models trained on single images lack multi-view knowledge. We instead argue that video models already contain implicit multi-view knowledge and so should be easier to adapt for NVS. Our key insight is to formulate sparse NVS as a low frame-rate video completion task. However, one challenge is that sparse NVS is defined over an unordered set of inputs, often too sparse to admit a meaningful order, so the models should be $\textit{invariant}$ to permutations of that input set. To this end, we present FrameCrafter, which adapts video models (naturally trained with coherent frame orderings) to permutation-invariant NVS through several architectural modifications, including per-frame latent encodings and removal of temporal positional embeddings. Our results suggest that video models can be easily trained to "forget" about time with minimal supervision, producing competitive performance on sparse-view NVS benchmarks. Project page: https://frame-crafter.github.io/
RAD-LAD: Rule and Language Grounded Autonomous Driving in Real-Time
Mar 31, 2026We present LAD, a real-time language--action planner with an interruptible architecture that produces a motion plan in a single forward pass (~20 Hz) or generates textual reasoning alongside a motion plan (~10 Hz). LAD is fast enough for real-time closed-loop deployment, achieving ~3x lower latency than prior driving language models while setting a new learning-based state of the art on nuPlan Test14-Hard and InterPlan. We also introduce RAD, a rule-based planner designed to address structural limitations of PDM-Closed. RAD achieves state-of-the-art performance among rule-based planners on nuPlan Test14-Hard and InterPlan. Finally, we show that combining RAD and LAD enables hybrid planning that captures the strengths of both approaches. This hybrid system demonstrates that rules and learning provide complementary capabilities: rules support reliable maneuvering, while language enables adaptive and explainable decision-making.
Scaling Group Inference for Diverse and High-Quality Generation
Aug 21, 2025Generative models typically sample outputs independently, and recent inference-time guidance and scaling algorithms focus on improving the quality of individual samples. However, in real-world applications, users are often presented with a set of multiple images (e.g., 4-8) for each prompt, where independent sampling tends to lead to redundant results, limiting user choices and hindering idea exploration. In this work, we introduce a scalable group inference method that improves both the diversity and quality of a group of samples. We formulate group inference as a quadratic integer assignment problem: candidate outputs are modeled as graph nodes, and a subset is selected to optimize sample quality (unary term) while maximizing group diversity (binary term). To substantially improve runtime efficiency, we progressively prune the candidate set using intermediate predictions, allowing our method to scale up to large candidate sets. Extensive experiments show that our method significantly improves group diversity and quality compared to independent sampling baselines and recent inference algorithms. Our framework generalizes across a wide range of tasks, including text-to-image, image-to-image, image prompting, and video generation, enabling generative models to treat multiple outputs as cohesive groups rather than independent samples.
AerialMegaDepth: Learning Aerial-Ground Reconstruction and View Synthesis
Apr 17, 2025We explore the task of geometric reconstruction of images captured from a mixture of ground and aerial views. Current state-of-the-art learning-based approaches fail to handle the extreme viewpoint variation between aerial-ground image pairs. Our hypothesis is that the lack of high-quality, co-registered aerial-ground datasets for training is a key reason for this failure. Such data is difficult to assemble precisely because it is difficult to reconstruct in a scalable way. To overcome this challenge, we propose a scalable framework combining pseudo-synthetic renderings from 3D city-wide meshes (e.g., Google Earth) with real, ground-level crowd-sourced images (e.g., MegaDepth). The pseudo-synthetic data simulates a wide range of aerial viewpoints, while the real, crowd-sourced images help improve visual fidelity for ground-level images where mesh-based renderings lack sufficient detail, effectively bridging the domain gap between real images and pseudo-synthetic renderings. Using this hybrid dataset, we fine-tune several state-of-the-art algorithms and achieve significant improvements on real-world, zero-shot aerial-ground tasks. For example, we observe that baseline DUSt3R localizes fewer than 5% of aerial-ground pairs within 5 degrees of camera rotation error, while fine-tuning with our data raises accuracy to nearly 56%, addressing a major failure point in handling large viewpoint changes. Beyond camera estimation and scene reconstruction, our dataset also improves performance on downstream tasks like novel-view synthesis in challenging aerial-ground scenarios, demonstrating the practical value of our approach in real-world applications.
Accenture-NVS1: A Novel View Synthesis Dataset
Mar 24, 2025This paper introduces ACC-NVS1, a specialized dataset designed for research on Novel View Synthesis specifically for airborne and ground imagery. Data for ACC-NVS1 was collected in Austin, TX and Pittsburgh, PA in 2023 and 2024. The collection encompasses six diverse real-world scenes captured from both airborne and ground cameras, resulting in a total of 148,000 images. ACC-NVS1 addresses challenges such as varying altitudes and transient objects. This dataset is intended to supplement existing datasets, providing additional resources for comprehensive research, rather than serving as a benchmark.
Indoor Light and Heat Estimation from a Single Panorama
Feb 10, 2025



This paper presents a novel application for directly estimating indoor light and heat maps from captured indoor-outdoor High Dynamic Range (HDR) panoramas. In our image-based rendering method, the indoor panorama is used to estimate the 3D room layout, while the corresponding outdoor panorama serves as an environment map to infer spatially-varying light and material properties. We establish a connection between indoor light transport and heat transport and implement transient heat simulation to generate indoor heat panoramas. The sensitivity analysis of various thermal parameters is conducted, and the resulting heat maps are compared with the images captured by the thermal camera in real-world scenarios. This digital application enables automatic indoor light and heat estimation without manual inputs and cumbersome field measurements.
Object-level Visual Prompts for Compositional Image Generation
Jan 02, 2025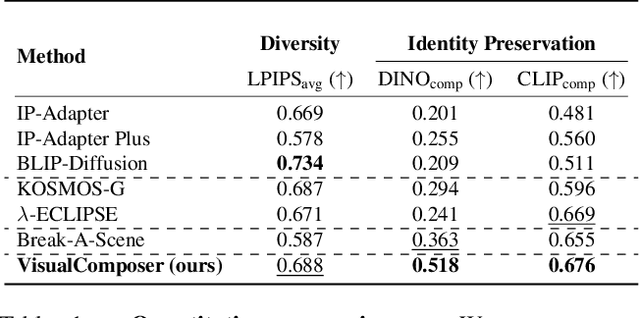


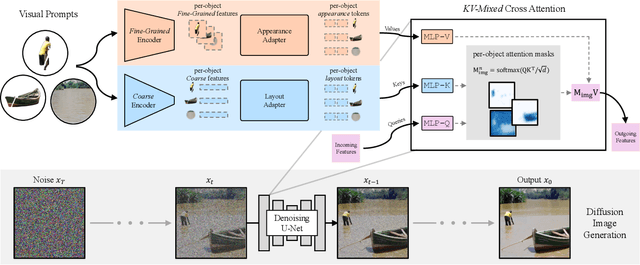
We introduce a method for composing object-level visual prompts within a text-to-image diffusion model. Our approach addresses the task of generating semantically coherent compositions across diverse scenes and styles, similar to the versatility and expressiveness offered by text prompts. A key challenge in this task is to preserve the identity of the objects depicted in the input visual prompts, while also generating diverse compositions across different images. To address this challenge, we introduce a new KV-mixed cross-attention mechanism, in which keys and values are learned from distinct visual representations. The keys are derived from an encoder with a small bottleneck for layout control, whereas the values come from a larger bottleneck encoder that captures fine-grained appearance details. By mixing keys and values from these complementary sources, our model preserves the identity of the visual prompts while supporting flexible variations in object arrangement, pose, and composition. During inference, we further propose object-level compositional guidance to improve the method's identity preservation and layout correctness. Results show that our technique produces diverse scene compositions that preserve the unique characteristics of each visual prompt, expanding the creative potential of text-to-image generation.
Incorporating dense metric depth into neural 3D representations for view synthesis and relighting
Sep 04, 2024



Synthesizing accurate geometry and photo-realistic appearance of small scenes is an active area of research with compelling use cases in gaming, virtual reality, robotic-manipulation, autonomous driving, convenient product capture, and consumer-level photography. When applying scene geometry and appearance estimation techniques to robotics, we found that the narrow cone of possible viewpoints due to the limited range of robot motion and scene clutter caused current estimation techniques to produce poor quality estimates or even fail. On the other hand, in robotic applications, dense metric depth can often be measured directly using stereo and illumination can be controlled. Depth can provide a good initial estimate of the object geometry to improve reconstruction, while multi-illumination images can facilitate relighting. In this work we demonstrate a method to incorporate dense metric depth into the training of neural 3D representations and address an artifact observed while jointly refining geometry and appearance by disambiguating between texture and geometry edges. We also discuss a multi-flash stereo camera system developed to capture the necessary data for our pipeline and show results on relighting and view synthesis with a few training views.
Robot Safety Monitoring using Programmable Light Curtains
Apr 04, 2024As factories continue to evolve into collaborative spaces with multiple robots working together with human supervisors in the loop, ensuring safety for all actors involved becomes critical. Currently, laser-based light curtain sensors are widely used in factories for safety monitoring. While these conventional safety sensors meet high accuracy standards, they are difficult to reconfigure and can only monitor a fixed user-defined region of space. Furthermore, they are typically expensive. Instead, we leverage a controllable depth sensor, programmable light curtains (PLC), to develop an inexpensive and flexible real-time safety monitoring system for collaborative robot workspaces. Our system projects virtual dynamic safety envelopes that tightly envelop the moving robot at all times and detect any objects that intrude the envelope. Furthermore, we develop an instrumentation algorithm that optimally places (multiple) PLCs in a workspace to maximize the visibility coverage of robots. Our work enables fence-less human-robot collaboration, while scaling to monitor multiple robots with few sensors. We analyze our system in a real manufacturing testbed with four robot arms and demonstrate its capabilities as a fast, accurate, and inexpensive safety monitoring solution.