 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayerComposer: Interactive Personalized T2I via Spatially-Aware Layered Canvas
Oct 23, 2025Despite their impressive visual fidelity, existing personalized generative models lack interactive control over spatial composition and scale poorly to multiple subjects. To address these limitations, we present LayerComposer, an interactive framework for personalized, multi-subject text-to-image generation. Our approach introduces two main contributions: (1) a layered canvas, a novel representation in which each subject is placed on a distinct layer, enabling occlusion-free composition; and (2) a locking mechanism that preserves selected layers with high fidelity while allowing the remaining layers to adapt flexibly to the surrounding context. Similar to professional image-editing software, the proposed layered canvas allows users to place, resize, or lock input subjects through intuitive layer manipulation. Our versatile locking mechanism requires no architectural changes, relying instead on inherent positional embeddings combined with a new complementary data sampling strategy. Extensive experiments demonstrate that LayerComposer achieves superior spatial control and identity preservation compared to the state-of-the-art methods in multi-subject personalized image generation.
Scaling Group Inference for Diverse and High-Quality Generation
Aug 21, 2025Generative models typically sample outputs independently, and recent inference-time guidance and scaling algorithms focus on improving the quality of individual samples. However, in real-world applications, users are often presented with a set of multiple images (e.g., 4-8) for each prompt, where independent sampling tends to lead to redundant results, limiting user choices and hindering idea exploration. In this work, we introduce a scalable group inference method that improves both the diversity and quality of a group of samples. We formulate group inference as a quadratic integer assignment problem: candidate outputs are modeled as graph nodes, and a subset is selected to optimize sample quality (unary term) while maximizing group diversity (binary term). To substantially improve runtime efficiency, we progressively prune the candidate set using intermediate predictions, allowing our method to scale up to large candidate sets. Extensive experiments show that our method significantly improves group diversity and quality compared to independent sampling baselines and recent inference algorithms. Our framework generalizes across a wide range of tasks, including text-to-image, image-to-image, image prompting, and video generation, enabling generative models to treat multiple outputs as cohesive groups rather than independent samples.
Nested Attention: Semantic-aware Attention Values for Concept Personalization
Jan 02, 2025Personalizing text-to-image models to generate images of specific subjects across diverse scenes and styles is a rapidly advancing field. Current approaches often face challenges in maintaining a balance between identity preservation and alignment with the input text prompt. Some methods rely on a single textual token to represent a subject, which limits expressiveness, while others employ richer representations but disrupt the model's prior, diminishing prompt alignment. In this work, we introduce Nested Attention, a novel mechanism that injects a rich and expressive image representation into the model's existing cross-attention layers. Our key idea is to generate query-dependent subject values, derived from nested attention layers that learn to select relevant subject features for each region in the generated image. We integrate these nested layers into an encoder-based personalization method, and show that they enable high identity preservation while adhering to input text prompts. Our approach is general and can be trained on various domains. Additionally, its prior preservation allows us to combine multiple personalized subjects from different domains in a single image.
Object-level Visual Prompts for Compositional Image Generation
Jan 02, 2025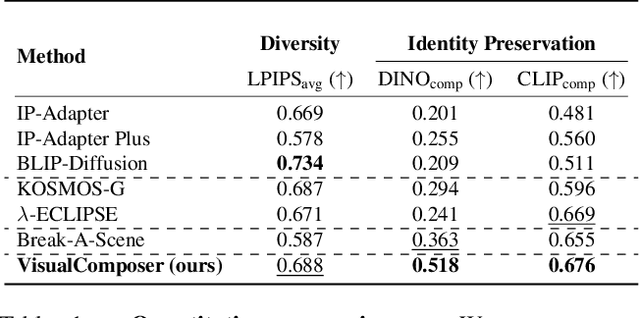


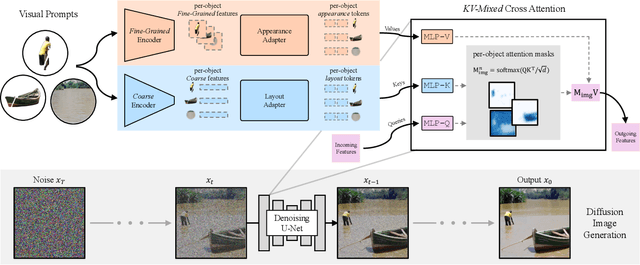
We introduce a method for composing object-level visual prompts within a text-to-image diffusion model. Our approach addresses the task of generating semantically coherent compositions across diverse scenes and styles, similar to the versatility and expressiveness offered by text prompts. A key challenge in this task is to preserve the identity of the objects depicted in the input visual prompts, while also generating diverse compositions across different images. To address this challenge, we introduce a new KV-mixed cross-attention mechanism, in which keys and values are learned from distinct visual representations. The keys are derived from an encoder with a small bottleneck for layout control, whereas the values come from a larger bottleneck encoder that captures fine-grained appearance details. By mixing keys and values from these complementary sources, our model preserves the identity of the visual prompts while supporting flexible variations in object arrangement, pose, and composition. During inference, we further propose object-level compositional guidance to improve the method's identity preservation and layout correctness. Results show that our technique produces diverse scene compositions that preserve the unique characteristics of each visual prompt, expanding the creative potential of text-to-image generation.
Omni-ID: Holistic Identity Representation Designed for Generative Tasks
Dec 12, 2024We introduce Omni-ID, a novel facial representation designed specifically for generative tasks. Omni-ID encodes holistic information about an individual's appearance across diverse expressions and poses within a fixed-size representation. It consolidates information from a varied number of unstructured input images into a structured representation, where each entry represents certain global or local identity features. Our approach uses a few-to-many identity reconstruction training paradigm, where a limited set of input images is used to reconstruct multiple target images of the same individual in various poses and expressions. A multi-decoder framework is further employed to leverage the complementary strengths of diverse decoders during training. Unlike conventional representations, such as CLIP and ArcFace, which are typically learned through discriminative or contrastive objectives, Omni-ID is optimized with a generative objective, resulting in a more comprehensive and nuanced identity capture for generative tasks. Trained on our MFHQ dataset -- a multi-view facial image collection, Omni-ID demonstrates substantial improvements over conventional representations across various generative tasks.
MoA: Mixture-of-Attention for Subject-Context Disentanglement in Personalized Image Generation
Apr 17, 2024We introduce a new architecture for personalization of text-to-image diffusion models, coined Mixture-of-Attention (MoA). Inspired by the Mixture-of-Experts mechanism utilized in large language models (LLMs), MoA distributes the generation workload between two attention pathways: a personalized branch and a non-personalized prior branch. MoA is designed to retain the original model's prior by fixing its attention layers in the prior branch, while minimally intervening in the generation process with the personalized branch that learns to embed subjects in the layout and context generated by the prior branch. A novel routing mechanism manages the distribution of pixels in each layer across these branches to optimize the blend of personalized and generic content creation. Once trained, MoA facilitates the creation of high-quality, personalized images featuring multiple subjects with compositions and interactions as diverse as those generated by the original model. Crucially, MoA enhances the distinction between the model's pre-existing capability and the newly augmented personalized intervention, thereby offering a more disentangled subject-context control that was previously unattainable. Project page: https://snap-research.github.io/mixture-of-attention
Personalized Restoration via Dual-Pivot Tuning
Dec 28, 2023Generative diffusion models can serve as a prior which ensures that solutions of image restoration systems adhere to the manifold of natural images. However, for restoring facial images, a personalized prior is necessary to accurately represent and reconstruct unique facial features of a given individual. In this paper, we propose a simple, yet effective, method for personalized restoration, called Dual-Pivot Tuning - a two-stage approach that personalize a blind restoration system while maintaining the integrity of the general prior and the distinct role of each component. Our key observation is that for optimal personalization, the generative model should be tuned around a fixed text pivot, while the guiding network should be tuned in a generic (non-personalized) manner, using the personalized generative model as a fixed ``pivot". This approach ensures that personalization does not interfere with the restoration process, resulting in a natural appearance with high fidelity to the person's identity and the attributes of the degraded image. We evaluated our approach both qualitatively and quantitatively through extensive experiments with images of widely recognized individuals, comparing it against relevant baselines. Surprisingly, we found that our personalized prior not only achieves higher fidelity to identity with respect to the person's identity, but also outperforms state-of-the-art generic priors in terms of general image quality. Project webpage: https://personalized-restoration.github.io