 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialStack: Layered Geometry-Language Fusion for 3D VLM Spatial Reasoning
Mar 28, 2026Large vision-language models (VLMs) still struggle with reliable 3D spatial reasoning, a core capability for embodied and physical AI systems. This limitation arises from their inability to capture fine-grained 3D geometry and spatial relationships. While recent efforts have introduced multi-view geometry transformers into VLMs, they typically fuse only the deep-layer features from vision and geometry encoders, discarding rich hierarchical signals and creating a fundamental bottleneck for spatial understanding. To overcome this, we propose SpatialStack, a general hierarchical fusion framework that progressively aligns vision, geometry, and language representations across the model hierarchy. Moving beyond conventional late-stage vision-geometry fusion, SpatialStack stacks and synchronizes multi-level geometric features with the language backbone, enabling the model to capture both local geometric precision and global contextual semantics. Building upon this framework, we develop VLM-SpatialStack, a model that achieves state-of-the-art performance on multiple 3D spatial reasoning benchmarks. Extensive experiments and ablations demonstrate that our multi-level fusion strategy consistently enhances 3D understanding and generalizes robustly across diverse spatial reasoning tasks, establishing SpatialStack as an effective and extensible design paradigm for vision-language-geometry integration in next-generation multimodal physical AI systems.
MoCA3D: Monocular 3D Bounding Box Prediction in the Image Plane
Mar 20, 2026Monocular 3D object understanding has largely been cast as a 2D RoI-to-3D box lifting problem. However, emerging downstream applications require image-plane geometry (e.g., projected 3D box corners) which cannot be easily obtained without known intrinsics, a problem for object detection in the wild. We introduce MoCA3D, a Monocular, Class-Agnostic 3D model that predicts projected 3D bounding box corners and per-corner depths without requiring camera intrinsics at inference time. MoCA3D formulates pixel-space localization and depth assignment as dense prediction via corner heatmaps and depth maps. To evaluate image-plane geometric fidelity, we propose Pixel-Aligned Geometry (PAG), which directly measures image-plane corner and depth consistency. Extensive experiments demonstrate that MoCA3D achieves state-of-the-art performance, improving image-plane corner PAG by 22.8% while remaining comparable on 3D IoU, using up to 57 times fewer trainable parameters. Finally, we apply MoCA3D to downstream tasks which were previously impractical under unknown intrinsics, highlighting its utility beyond standard baseline models.
WorldBench: Disambiguating Physics for Diagnostic Evaluation of World Models
Jan 29, 2026Recent advances in generative foundational models, often termed "world models," have propelled interest in applying them to critical tasks like robotic planning and autonomous system training. For reliable deployment, these models must exhibit high physical fidelity, accurately simulating real-world dynamics. Existing physics-based video benchmarks, however, suffer from entanglement, where a single test simultaneously evaluates multiple physical laws and concepts, fundamentally limiting their diagnostic capability. We introduce WorldBench, a novel video-based benchmark specifically designed for concept-specific, disentangled evaluation, allowing us to rigorously isolate and assess understanding of a single physical concept or law at a time. To make WorldBench comprehensive, we design benchmarks at two different levels: 1) an evaluation of intuitive physical understanding with concepts such as object permanence or scale/perspective, and 2) an evaluation of low-level physical constants and material properties such as friction coefficients or fluid viscosity. When SOTA video-based world models are evaluated on WorldBench, we find specific patterns of failure in particular physics concepts, with all tested models lacking the physical consistency required to generate reliable real-world interactions. Through its concept-specific evaluation, WorldBench offers a more nuanced and scalable framework for rigorously evaluating the physical reasoning capabilities of video generation and world models, paving the way for more robust and generalizable world-model-driven learning.
MorphoSim: An Interactive, Controllable, and Editable Language-guided 4D World Simulator
Oct 05, 2025



World models that support controllable and editable spatiotemporal environments are valuable for robotics, enabling scalable training data, repro ducible evaluation, and flexible task design. While recent text-to-video models generate realistic dynam ics, they are constrained to 2D views and offer limited interaction. We introduce MorphoSim, a language guided framework that generates 4D scenes with multi-view consistency and object-level controls. From natural language instructions, MorphoSim produces dynamic environments where objects can be directed, recolored, or removed, and scenes can be observed from arbitrary viewpoints. The framework integrates trajectory-guided generation with feature field dis tillation, allowing edits to be applied interactively without full re-generation. Experiments show that Mor phoSim maintains high scene fidelity while enabling controllability and editability. The code is available at https://github.com/eric-ai-lab/Morph4D.
Feature4X: Bridging Any Monocular Video to 4D Agentic AI with Versatile Gaussian Feature Fields
Mar 26, 2025Recent advancements in 2D and multimodal models have achieved remarkable success by leveraging large-scale training on extensive datasets. However, extending these achievements to enable free-form interactions and high-level semantic operations with complex 3D/4D scenes remains challenging. This difficulty stems from the limited availability of large-scale, annotated 3D/4D or multi-view datasets, which are crucial for generalizable vision and language tasks such as open-vocabulary and prompt-based segmentation, language-guided editing, and visual question answering (VQA). In this paper, we introduce Feature4X, a universal framework designed to extend any functionality from 2D vision foundation model into the 4D realm, using only monocular video input, which is widely available from user-generated content. The "X" in Feature4X represents its versatility, enabling any task through adaptable, model-conditioned 4D feature field distillation. At the core of our framework is a dynamic optimization strategy that unifies multiple model capabilities into a single representation. Additionally, to the best of our knowledge, Feature4X is the first method to distill and lift the features of video foundation models (e.g. SAM2, InternVideo2) into an explicit 4D feature field using Gaussian Splatting. Our experiments showcase novel view segment anything, geometric and appearance scene editing, and free-form VQA across all time steps, empowered by LLMs in feedback loops. These advancements broaden the scope of agentic AI applications by providing a foundation for scalable, contextually and spatiotemporally aware systems capable of immersive dynamic 4D scene interaction.
InstantRestore: Single-Step Personalized Face Restoration with Shared-Image Attention
Dec 09, 2024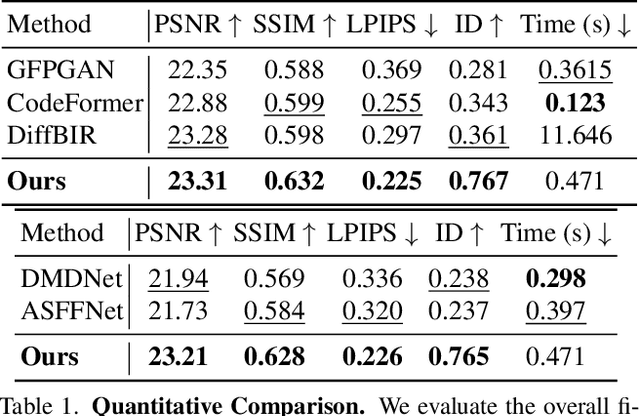
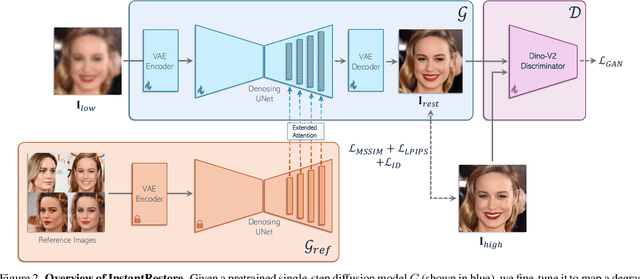
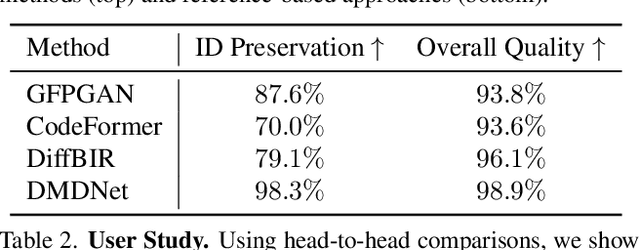
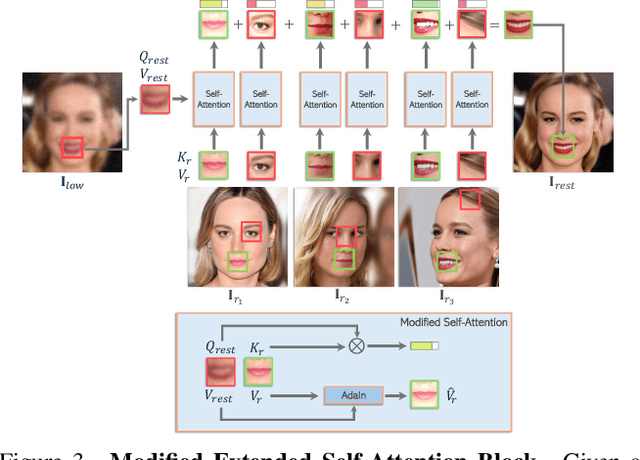
Face image restoration aims to enhance degraded facial images while addressing challenges such as diverse degradation types, real-time processing demands, and, most crucially, the preservation of identity-specific features. Existing methods often struggle with slow processing times and suboptimal restoration, especially under severe degradation, failing to accurately reconstruct finer-level identity details. To address these issues, we introduce InstantRestore, a novel framework that leverages a single-step image diffusion model and an attention-sharing mechanism for fast and personalized face restoration. Additionally, InstantRestore incorporates a novel landmark attention loss, aligning key facial landmarks to refine the attention maps, enhancing identity preservation. At inference time, given a degraded input and a small (~4) set of reference images, InstantRestore performs a single forward pass through the network to achieve near real-time performance. Unlike prior approaches that rely on full diffusion processes or per-identity model tuning, InstantRestore offers a scalable solution suitable for large-scale applications. Extensive experiments demonstrate that InstantRestore outperforms existing methods in quality and speed, making it an appealing choice for identity-preserving face restoration.
2-Factor Retrieval for Improved Human-AI Decision Making in Radiology
Nov 30, 2024Human-machine teaming in medical AI requires us to understand to what degree a trained clinician should weigh AI predictions. While previous work has shown the potential of AI assistance at improving clinical predictions, existing clinical decision support systems either provide no explainability of their predictions or use techniques like saliency and Shapley values, which do not allow for physician-based verification. To address this gap, this study compares previously used explainable AI techniques with a newly proposed technique termed '2-factor retrieval (2FR)', which is a combination of interface design and search retrieval that returns similarly labeled data without processing this data. This results in a 2-factor security blanket where: (a) correct images need to be retrieved by the AI; and (b) humans should associate the retrieved images with the current pathology under test. We find that when tested on chest X-ray diagnoses, 2FR leads to increases in clinician accuracy, with particular improvements when clinicians are radiologists and have low confidence in their decision. Our results highlight the importance of understanding how different modes of human-AI decision making may impact clinician accuracy in clinical decision support systems.
Large Spatial Model: End-to-end Unposed Images to Semantic 3D
Oct 24, 2024



Reconstructing and understanding 3D structures from a limited number of images is a well-established problem in computer vision. Traditional methods usually break this task into multiple subtasks, each requiring complex transformations between different data representations. For instance, dense reconstruction through Structure-from-Motion (SfM) involves converting images into key points, optimizing camera parameters, and estimating structures. Afterward, accurate sparse reconstructions are required for further dense modeling, which is subsequently fed into task-specific neural networks. This multi-step process results in considerable processing time and increased engineering complexity. In this work, we present the Large Spatial Model (LSM), which processes unposed RGB images directly into semantic radiance fields. LSM simultaneously estimates geometry, appearance, and semantics in a single feed-forward operation, and it can generate versatile label maps by interacting with language at novel viewpoints. Leveraging a Transformer-based architecture, LSM integrates global geometry through pixel-aligned point maps. To enhance spatial attribute regression, we incorporate local context aggregation with multi-scale fusion, improving the accuracy of fine local details. To tackle the scarcity of labeled 3D semantic data and enable natural language-driven scene manipulation, we incorporate a pre-trained 2D language-based segmentation model into a 3D-consistent semantic feature field. An efficient decoder then parameterizes a set of semantic anisotropic Gaussians, facilitating supervised end-to-end learning. Extensive experiments across various tasks show that LSM unifies multiple 3D vision tasks directly from unposed images, achieving real-time semantic 3D reconstruction for the first time.
Thermal Imaging and Radar for Remote Sleep Monitoring of Breathing and Apnea
Jul 16, 2024Polysomnography (PSG), the current gold standard method for monitoring and detecting sleep disorders, is cumbersome and costly. At-home testing solutions, known as home sleep apnea testing (HSAT), exist. However, they are contact-based, a feature which limits the ability of some patient populations to tolerate testing and discourages widespread deployment. Previous work on non-contact sleep monitoring for sleep apnea detection either estimates respiratory effort using radar or nasal airflow using a thermal camera, but has not compared the two or used them together. We conducted a study on 10 participants, ages 34 - 78, with suspected sleep disorders using a hardware setup with a synchronized radar and thermal camera. We show the first comparison of radar and thermal imaging for sleep monitoring, and find that our thermal imaging method outperforms radar significantly. Our thermal imaging method detects apneas with an accuracy of 0.99, a precision of 0.68, a recall of 0.74, an F1 score of 0.71, and an intra-class correlation of 0.70; our radar method detects apneas with an accuracy of 0.83, a precision of 0.13, a recall of 0.86, an F1 score of 0.22, and an intra-class correlation of 0.13. We also present a novel proposal for classifying obstructive and central sleep apnea by leveraging a multimodal setup. This method could be used accurately detect and classify apneas during sleep with non-contact sensors, thereby improving diagnostic capacities in patient populations unable to tolerate current technology.
Solutions to Deepfakes: Can Camera Hardware, Cryptography, and Deep Learning Verify Real Images?
Jul 04, 2024


The exponential progress in generative AI poses serious implications for the credibility of all real images and videos. There will exist a point in the future where 1) digital content produced by generative AI will be indistinguishable from those created by cameras, 2) high-quality generative algorithms will be accessible to anyone, and 3) the ratio of all synthetic to real images will be large. It is imperative to establish methods that can separate real data from synthetic data with high confidence. We define real images as those that were produced by the camera hardware, capturing a real-world scene. Any synthetic generation of an image or alteration of a real image through generative AI or computer graphics techniques is labeled as a synthetic image. To this end, this document aims to: present known strategies in detection and cryptography that can be employed to verify which images are real, weight the strengths and weaknesses of these strategies, and suggest additional improvements to alleviate shortcomings.