 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeatherProof: Leveraging Language Guidance for Semantic Segmentation in Adverse Weather
Mar 21, 2024
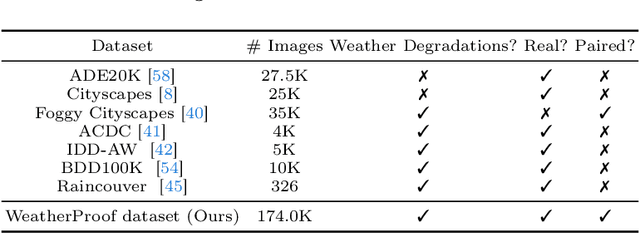


We propose a method to infer semantic segmentation maps from images captured under adverse weather conditions. We begin by examining existing models on images degraded by weather conditions such as rain, fog, or snow, and found that they exhibit a large performance drop as compared to those captured under clear weather. To control for changes in scene structures, we propose WeatherProof, the first semantic segmentation dataset with accurate clear and adverse weather image pairs that share an underlying scene. Through this dataset, we analyze the error modes in existing models and found that they were sensitive to the highly complex combination of different weather effects induced on the image during capture. To improve robustness, we propose a way to use language as guidance by identifying contributions of adverse weather conditions and injecting that as "side information". Models trained using our language guidance exhibit performance gains by up to 10.2% in mIoU on WeatherProof, up to 8.44% in mIoU on the widely used ACDC dataset compared to standard training techniques, and up to 6.21% in mIoU on the ACDC dataset as compared to previous SOTA methods.
WeatherProof: A Paired-Dataset Approach to Semantic Segmentation in Adverse Weather
Dec 15, 2023



The introduction of large, foundational models to computer vision has led to drastically improved performance on the task of semantic segmentation. However, these existing methods exhibit a large performance drop when testing on images degraded by weather conditions such as rain, fog, or snow. We introduce a general paired-training method that can be applied to all current foundational model architectures that leads to improved performance on images in adverse weather conditions. To this end, we create the WeatherProof Dataset, the first semantic segmentation dataset with accurate clear and adverse weather image pairs, which not only enables our new training paradigm, but also improves the evaluation of the performance gap between clear and degraded segmentation. We find that training on these paired clear and adverse weather frames which share an underlying scene results in improved performance on adverse weather data. With this knowledge, we propose a training pipeline which accentuates the advantages of paired-data training using consistency losses and language guidance, which leads to performance improvements by up to 18.4% as compared to standard training procedures.
Enhancing Diffusion Models with 3D Perspective Geometry Constraints
Dec 01, 2023While perspective is a well-studied topic in art, it is generally taken for granted in images. However, for the recent wave of high-quality image synthesis methods such as latent diffusion models, perspective accuracy is not an explicit requirement. Since these methods are capable of outputting a wide gamut of possible images, it is difficult for these synthesized images to adhere to the principles of linear perspective. We introduce a novel geometric constraint in the training process of generative models to enforce perspective accuracy. We show that outputs of models trained with this constraint both appear more realistic and improve performance of downstream models trained on generated images. Subjective human trials show that images generated with latent diffusion models trained with our constraint are preferred over images from the Stable Diffusion V2 model 70% of the time. SOTA monocular depth estimation models such as DPT and PixelFormer, fine-tuned on our images, outperform the original models trained on real images by up to 7.03% in RMSE and 19.3% in SqRel on the KITTI test set for zero-shot transfer.