 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePinPoint: Prompting with Informative Interior Points
May 26, 2026Modern referring image segmentation pipelines couple a vision-language model (VLM) for grounding with a promptable segmenter such as the Segment Anything Model (SAM) for mask generation. Prior training-free instances of this recipe consistently trail fine-tuned and reinforcement-learning (RL)-tuned specialists, and it has been unclear whether the gap comes from the VLM's grounding, SAM's capacity, or the prompt. We show that the gap is dominated by prompt ambiguity: a VLM-proposed bounding box (bbox) leaves SAM to guess which pixels inside the bbox belong to the object the expression denotes. Interior points are the natural disambiguator, but where they fall matters; prior work relies on naively sampled points that land on boundaries, distractors, and background clutter, and can even hurt performance compared to the bbox alone. Supervised and RL-tuned methods close this gap by training a VLM to predict better points; we show that this training is unnecessary. At a matched budget of five interior points, replacing naive sampling with stable, informative point selection improves cumulative Intersection-over-Union (cIoU) by 12-18 points across RefCOCO/+/g, with every model fixed. We turn this observation into PinPoint, a deterministic, training-free point selector that fuses four visual cues into a consensus map, selects compact, spatially diverse points away from boundaries, and uses the frozen VLM to label each point. Without any task-specific training, PinPoint matches supervised and RL-tuned specialists on the same stack while issuing only two VLM calls per query.
Fisheye3R: Adapting Unified 3D Feed-Forward Foundation Models to Fisheye Lenses
Mar 30, 2026Feed-forward foundation models for multi-view 3-dimensional (3D) reconstruction have been trained on large-scale datasets of perspective images; when tested on wide field-of-view images, e.g., from a fisheye camera, their performance degrades. Their error arises from changes in spatial positions of pixels due to a non-linear projection model that maps 3D points onto the 2D image plane. While one may surmise that training on fisheye images would resolve this problem, there are far fewer fisheye images with ground truth than perspective images, which limit generalization. To enable inference on imagery exhibiting high radial distortion, we propose Fisheye3R, a novel adaptation framework that extends these multi-view 3D reconstruction foundation models to natively accommodate fisheye inputs without performance regression on perspective images. To address the scarcity of fisheye images and ground truth, we introduce flexible learning schemes that support self-supervised adaptation using only unlabeled perspective images and supervised adaptation without any fisheye training data. Extensive experiments across three foundation models, including VGGT, $π^3$, and MapAnything, demonstrate that our approach consistently improves camera pose, depth, point map, and field-of-view estimation on fisheye images.
SHOW3D: Capturing Scenes of 3D Hands and Objects in the Wild
Mar 30, 2026Accurate 3D understanding of human hands and objects during manipulation remains a significant challenge for egocentric computer vision. Existing hand-object interaction datasets are predominantly captured in controlled studio settings, which limits both environmental diversity and the ability of models trained on such data to generalize to real-world scenarios. To address this challenge, we introduce a novel marker-less multi-camera system that allows for nearly unconstrained mobility in genuinely in-the-wild conditions, while still having the ability to generate precise 3D annotations of hands and objects. The capture system consists of a lightweight, back-mounted, multi-camera rig that is synchronized and calibrated with a user-worn VR headset. For 3D ground-truth annotation of hands and objects, we develop an ego-exo tracking pipeline and rigorously evaluate its quality. Finally, we present SHOW3D, the first large-scale dataset with 3D annotations that show hands interacting with objects in diverse real-world environments, including outdoor settings. Our approach significantly reduces the fundamental trade-off between environmental realism and accuracy of 3D annotations, which we validate with experiments on several downstream tasks. show3d-dataset.github.io
Evidential Neural Radiance Fields
Feb 27, 2026Understanding sources of uncertainty is fundamental to trustworthy three-dimensional scene modeling. While recent advances in neural radiance fields (NeRFs) achieve impressive accuracy in scene reconstruction and novel view synthesis, the lack of uncertainty estimation significantly limits their deployment in safety-critical settings. Existing uncertainty quantification methods for NeRFs fail to capture both aleatoric and epistemic uncertainty. Among those that do quantify one or the other, many of them either compromise rendering quality or incur significant computational overhead to obtain uncertainty estimates. To address these issues, we introduce Evidential Neural Radiance Fields, a probabilistic approach that seamlessly integrates with the NeRF rendering process and enables direct quantification of both aleatoric and epistemic uncertainty from a single forward pass. We compare multiple uncertainty quantification methods on three standardized benchmarks, where our approach demonstrates state-of-the-art scene reconstruction fidelity and uncertainty estimation quality.
Tuning Out-of-Distribution (OOD) Detectors Without Given OOD Data
Feb 05, 2026Existing out-of-distribution (OOD) detectors are often tuned by a separate dataset deemed OOD with respect to the training distribution of a neural network (NN). OOD detectors process the activations of NN layers and score the output, where parameters of the detectors are determined by fitting to an in-distribution (training) set and the aforementioned dataset chosen adhocly. At detector training time, this adhoc dataset may not be available or difficult to obtain, and even when it's available, it may not be representative of actual OOD data, which is often ''unknown unknowns." Current benchmarks may specify some left-out set from test OOD sets. We show that there can be significant variance in performance of detectors based on the adhoc dataset chosen in current literature, and thus even if such a dataset can be collected, the performance of the detector may be highly dependent on the choice. In this paper, we introduce and formalize the often neglected problem of tuning OOD detectors without a given ``OOD'' dataset. To this end, we present strong baselines as an attempt to approach this problem. Furthermore, we propose a new generic approach to OOD detector tuning that does not require any extra data other than those used to train the NN. We show that our approach improves over baseline methods consistently across higher-parameter OOD detector families, while being comparable across lower-parameter families.
WorldBench: Disambiguating Physics for Diagnostic Evaluation of World Models
Jan 29, 2026Recent advances in generative foundational models, often termed "world models," have propelled interest in applying them to critical tasks like robotic planning and autonomous system training. For reliable deployment, these models must exhibit high physical fidelity, accurately simulating real-world dynamics. Existing physics-based video benchmarks, however, suffer from entanglement, where a single test simultaneously evaluates multiple physical laws and concepts, fundamentally limiting their diagnostic capability. We introduce WorldBench, a novel video-based benchmark specifically designed for concept-specific, disentangled evaluation, allowing us to rigorously isolate and assess understanding of a single physical concept or law at a time. To make WorldBench comprehensive, we design benchmarks at two different levels: 1) an evaluation of intuitive physical understanding with concepts such as object permanence or scale/perspective, and 2) an evaluation of low-level physical constants and material properties such as friction coefficients or fluid viscosity. When SOTA video-based world models are evaluated on WorldBench, we find specific patterns of failure in particular physics concepts, with all tested models lacking the physical consistency required to generate reliable real-world interactions. Through its concept-specific evaluation, WorldBench offers a more nuanced and scalable framework for rigorously evaluating the physical reasoning capabilities of video generation and world models, paving the way for more robust and generalizable world-model-driven learning.
Coffee: Controllable Diffusion Fine-tuning
Nov 18, 2025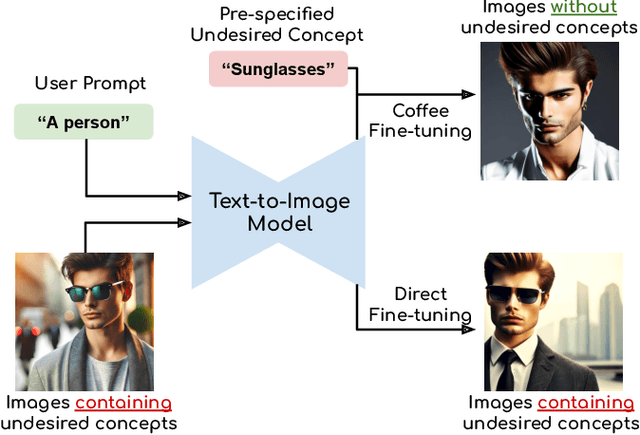
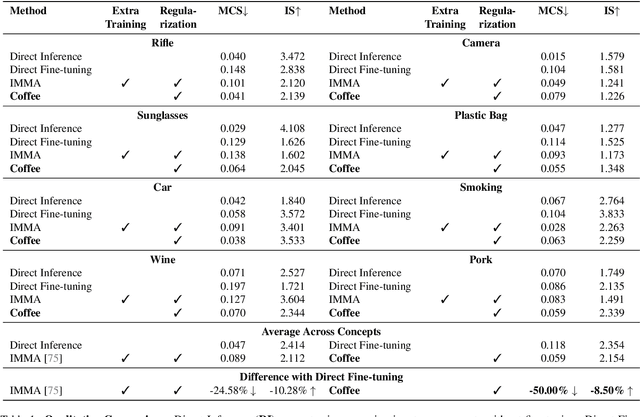

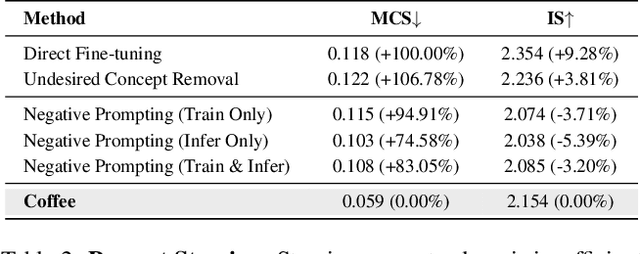
Text-to-image diffusion models can generate diverse content with flexible prompts, which makes them well-suited for customization through fine-tuning with a small amount of user-provided data. However, controllable fine-tuning that prevents models from learning undesired concepts present in the fine-tuning data, and from entangling those concepts with user prompts, remains an open challenge. It is crucial for downstream tasks like bias mitigation, preventing malicious adaptation, attribute disentanglement, and generalizable fine-tuning of diffusion policy. We propose Coffee that allows using language to specify undesired concepts to regularize the adaptation process. The crux of our method lies in keeping the embeddings of the user prompt from aligning with undesired concepts. Crucially, Coffee requires no additional training and enables flexible modification of undesired concepts by modifying textual descriptions. We evaluate Coffee by fine-tuning on images associated with user prompts paired with undesired concepts. Experimental results demonstrate that Coffee can prevent text-to-image models from learning specified undesired concepts during fine-tuning and outperforms existing methods. Code will be released upon acceptance.
Extending Foundational Monocular Depth Estimators to Fisheye Cameras with Calibration Tokens
Aug 06, 2025We propose a method to extend foundational monocular depth estimators (FMDEs), trained on perspective images, to fisheye images. Despite being trained on tens of millions of images, FMDEs are susceptible to the covariate shift introduced by changes in camera calibration (intrinsic, distortion) parameters, leading to erroneous depth estimates. Our method aligns the distribution of latent embeddings encoding fisheye images to those of perspective images, enabling the reuse of FMDEs for fisheye cameras without retraining or finetuning. To this end, we introduce a set of Calibration Tokens as a light-weight adaptation mechanism that modulates the latent embeddings for alignment. By exploiting the already expressive latent space of FMDEs, we posit that modulating their embeddings avoids the negative impact of artifacts and loss introduced in conventional recalibration or map projection to a canonical reference frame in the image space. Our method is self-supervised and does not require fisheye images but leverages publicly available large-scale perspective image datasets. This is done by recalibrating perspective images to fisheye images, and enforcing consistency between their estimates during training. We evaluate our approach with several FMDEs, on both indoors and outdoors, where we consistently improve over state-of-the-art methods using a single set of tokens for both. Code available at: https://github.com/JungHeeKim29/calibration-token.
ODE-GS: Latent ODEs for Dynamic Scene Extrapolation with 3D Gaussian Splatting
Jun 05, 2025We present ODE-GS, a novel method that unifies 3D Gaussian Splatting with latent neural ordinary differential equations (ODEs) to forecast dynamic 3D scenes far beyond the time span seen during training. Existing neural rendering systems - whether NeRF- or 3DGS-based - embed time directly in a deformation network and therefore excel at interpolation but collapse when asked to predict the future, where timestamps are strictly out-of-distribution. ODE-GS eliminates this dependency: after learning a high-fidelity, time-conditioned deformation model for the training window, we freeze it and train a Transformer encoder that summarizes past Gaussian trajectories into a latent state whose continuous evolution is governed by a neural ODE. Numerical integration of this latent flow yields smooth, physically plausible Gaussian trajectories that can be queried at any future instant and rendered in real time. Coupled with a variational objective and a lightweight second-derivative regularizer, ODE-GS attains state-of-the-art extrapolation on D-NeRF and NVFI benchmarks, improving PSNR by up to 10 dB and halving perceptual error (LPIPS) relative to the strongest baselines. Our results demonstrate that continuous-time latent dynamics are a powerful, practical route to photorealistic prediction of complex 3D scenes.
STree: Speculative Tree Decoding for Hybrid State-Space Models
May 20, 2025



Speculative decoding is a technique to leverage hardware concurrency to improve the efficiency of large-scale autoregressive (AR) Transformer models by enabling multiple steps of token generation in a single forward pass. State-space models (SSMs) are already more efficient than AR Transformers, since their state summarizes all past data with no need to cache or re-process tokens in the sliding window context. However, their state can also comprise thousands of tokens; so, speculative decoding has recently been extended to SSMs. Existing approaches, however, do not leverage the tree-based verification methods, since current SSMs lack the means to compute a token tree efficiently. We propose the first scalable algorithm to perform tree-based speculative decoding in state-space models (SSMs) and hybrid architectures of SSMs and Transformer layers. We exploit the structure of accumulated state transition matrices to facilitate tree-based speculative decoding with minimal overhead to current SSM state update implementations. With the algorithm, we describe a hardware-aware implementation that improves naive application of AR Transformer tree-based speculative decoding methods to SSMs. Furthermore, we outperform vanilla speculative decoding with SSMs even with a baseline drafting model and tree structure on three different benchmarks, opening up opportunities for further speed up with SSM and hybrid model inference. Code will be released upon paper acceptance.