 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaxonomy, Evaluation and Exploitation of IPI-Centric LLM Agent Defense Frameworks
Nov 19, 2025Large Language Model (LLM)-based agents with function-calling capabilities are increasingly deployed, but remain vulnerable to Indirect Prompt Injection (IPI) attacks that hijack their tool calls. In response, numerous IPI-centric defense frameworks have emerged. However, these defenses are fragmented, lacking a unified taxonomy and comprehensive evaluation. In this Systematization of Knowledge (SoK), we present the first comprehensive analysis of IPI-centric defense frameworks. We introduce a comprehensive taxonomy of these defenses, classifying them along five dimensions. We then thoroughly assess the security and usability of representative defense frameworks. Through analysis of defensive failures in the assessment, we identify six root causes of defense circumvention. Based on these findings, we design three novel adaptive attacks that significantly improve attack success rates targeting specific frameworks, demonstrating the severity of the flaws in these defenses. Our paper provides a foundation and critical insights for the future development of more secure and usable IPI-centric agent defense frameworks.
Modeling Uncertainty Trends for Timely Retrieval in Dynamic RAG
Nov 13, 2025Dynamic retrieval-augmented generation (RAG) allows large language models (LLMs) to fetch external knowledge on demand, offering greater adaptability than static RAG. A central challenge in this setting lies in determining the optimal timing for retrieval. Existing methods often trigger retrieval based on low token-level confidence, which may lead to delayed intervention after errors have already propagated. We introduce Entropy-Trend Constraint (ETC), a training-free method that determines optimal retrieval timing by modeling the dynamics of token-level uncertainty. Specifically, ETC utilizes first- and second-order differences of the entropy sequence to detect emerging uncertainty trends, enabling earlier and more precise retrieval. Experiments on six QA benchmarks with three LLM backbones demonstrate that ETC consistently outperforms strong baselines while reducing retrieval frequency. ETC is particularly effective in domain-specific scenarios, exhibiting robust generalization capabilities. Ablation studies and qualitative analyses further confirm that trend-aware uncertainty modeling yields more effective retrieval timing. The method is plug-and-play, model-agnostic, and readily integrable into existing decoding pipelines. Implementation code is included in the supplementary materials.
ODE-GS: Latent ODEs for Dynamic Scene Extrapolation with 3D Gaussian Splatting
Jun 05, 2025We present ODE-GS, a novel method that unifies 3D Gaussian Splatting with latent neural ordinary differential equations (ODEs) to forecast dynamic 3D scenes far beyond the time span seen during training. Existing neural rendering systems - whether NeRF- or 3DGS-based - embed time directly in a deformation network and therefore excel at interpolation but collapse when asked to predict the future, where timestamps are strictly out-of-distribution. ODE-GS eliminates this dependency: after learning a high-fidelity, time-conditioned deformation model for the training window, we freeze it and train a Transformer encoder that summarizes past Gaussian trajectories into a latent state whose continuous evolution is governed by a neural ODE. Numerical integration of this latent flow yields smooth, physically plausible Gaussian trajectories that can be queried at any future instant and rendered in real time. Coupled with a variational objective and a lightweight second-derivative regularizer, ODE-GS attains state-of-the-art extrapolation on D-NeRF and NVFI benchmarks, improving PSNR by up to 10 dB and halving perceptual error (LPIPS) relative to the strongest baselines. Our results demonstrate that continuous-time latent dynamics are a powerful, practical route to photorealistic prediction of complex 3D scenes.
FreRA: A Frequency-Refined Augmentation for Contrastive Learning on Time Series Classification
May 29, 2025Contrastive learning has emerged as a competent approach for unsupervised representation learning. However, the design of an optimal augmentation strategy, although crucial for contrastive learning, is less explored for time series classification tasks. Existing predefined time-domain augmentation methods are primarily adopted from vision and are not specific to time series data. Consequently, this cross-modality incompatibility may distort the semantically relevant information of time series by introducing mismatched patterns into the data. To address this limitation, we present a novel perspective from the frequency domain and identify three advantages for downstream classification: global, independent, and compact. To fully utilize the three properties, we propose the lightweight yet effective Frequency Refined Augmentation (FreRA) tailored for time series contrastive learning on classification tasks, which can be seamlessly integrated with contrastive learning frameworks in a plug-and-play manner. Specifically, FreRA automatically separates critical and unimportant frequency components. Accordingly, we propose semantic-aware Identity Modification and semantic-agnostic Self-adaptive Modification to protect semantically relevant information in the critical frequency components and infuse variance into the unimportant ones respectively. Theoretically, we prove that FreRA generates semantic-preserving views. Empirically, we conduct extensive experiments on two benchmark datasets, including UCR and UEA archives, as well as five large-scale datasets on diverse applications. FreRA consistently outperforms ten leading baselines on time series classification, anomaly detection, and transfer learning tasks, demonstrating superior capabilities in contrastive representation learning and generalization in transfer learning scenarios across diverse datasets.
Uncovering the Impact of Chain-of-Thought Reasoning for Direct Preference Optimization: Lessons from Text-to-SQL
Feb 17, 2025



Direct Preference Optimization (DPO) has proven effective in complex reasoning tasks like math word problems and code generation. However, when applied to Text-to-SQL datasets, it often fails to improve performance and can even degrade it. Our investigation reveals the root cause: unlike math and code tasks, which naturally integrate Chain-of-Thought (CoT) reasoning with DPO, Text-to-SQL datasets typically include only final answers (gold SQL queries) without detailed CoT solutions. By augmenting Text-to-SQL datasets with synthetic CoT solutions, we achieve, for the first time, consistent and significant performance improvements using DPO. Our analysis shows that CoT reasoning is crucial for unlocking DPO's potential, as it mitigates reward hacking, strengthens discriminative capabilities, and improves scalability. These findings offer valuable insights for building more robust Text-to-SQL models. To support further research, we publicly release the code and CoT-enhanced datasets.
Confident Natural Policy Gradient for Local Planning in $q_π$-realizable Constrained MDPs
Jun 26, 2024The constrained Markov decision process (CMDP) framework emerges as an important reinforcement learning approach for imposing safety or other critical objectives while maximizing cumulative reward. However, the current understanding of how to learn efficiently in a CMDP environment with a potentially infinite number of states remains under investigation, particularly when function approximation is applied to the value functions. In this paper, we address the learning problem given linear function approximation with $q_{\pi}$-realizability, where the value functions of all policies are linearly representable with a known feature map, a setting known to be more general and challenging than other linear settings. Utilizing a local-access model, we propose a novel primal-dual algorithm that, after $\tilde{O}(\text{poly}(d) \epsilon^{-3})$ queries, outputs with high probability a policy that strictly satisfies the constraints while nearly optimizing the value with respect to a reward function. Here, $d$ is the feature dimension and $\epsilon > 0$ is a given error. The algorithm relies on a carefully crafted off-policy evaluation procedure to evaluate the policy using historical data, which informs policy updates through policy gradients and conserves samples. To our knowledge, this is the first result achieving polynomial sample complexity for CMDP in the $q_{\pi}$-realizable setting.
Versatile Teacher: A Class-aware Teacher-student Framework for Cross-domain Adaptation
May 20, 2024



Addressing the challenge of domain shift between datasets is vital in maintaining model performance. In the context of cross-domain object detection, the teacher-student framework, a widely-used semi-supervised model, has shown significant accuracy improvements. However, existing methods often overlook class differences, treating all classes equally, resulting in suboptimal results. Furthermore, the integration of instance-level alignment with a one-stage detector, essential due to the absence of a Region Proposal Network (RPN), remains unexplored in this framework. In response to these shortcomings, we introduce a novel teacher-student model named Versatile Teacher (VT). VT differs from previous works by considering class-specific detection difficulty and employing a two-step pseudo-label selection mechanism, referred to as Class-aware Pseudo-label Adaptive Selection (CAPS), to generate more reliable pseudo labels. These labels are leveraged as saliency matrices to guide the discriminator for targeted instance-level alignment. Our method demonstrates promising results on three benchmark datasets, and extends the alignment methods for widely-used one-stage detectors, presenting significant potential for practical applications. Code is available at https://github.com/RicardooYoung/VersatileTeacher.
A Robust ADMM-Based Optimization Algorithm For Underwater Acoustic Channel Estimation
Aug 24, 2023Accurate estimation of the Underwater acoustic (UWA) is a key part of underwater communications, especially for coherent systems. The severe multipath effects and large delay spreads make the estimation problem large-scale. The non-stationary, non-Gaussian, and impulsive nature of ocean ambient noise poses further obstacles to the design of estimation algorithms. Under the framework of compressed sensing (CS), this work addresses the issue of robust channel estimation when measurements are contaminated by impulsive noise. A first-order algorithm based on alternating direction method of multipliers (ADMM) is proposed. Numerical simulations of time-varying channel estimation are performed to show its improved performance in highly impulsive noise environments.
Doubly-Asynchronous Value Iteration: Making Value Iteration Asynchronous in Actions
Jul 04, 2022
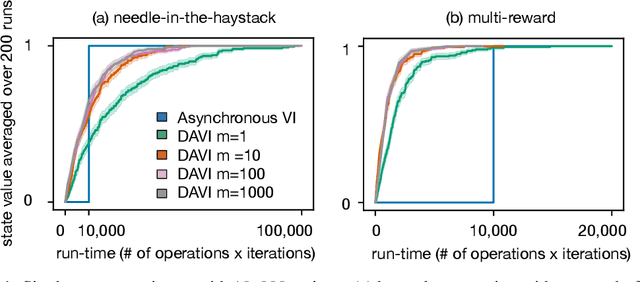
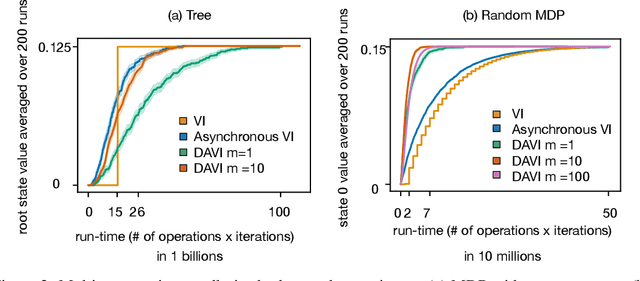
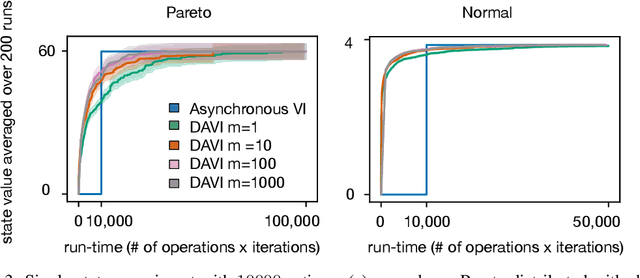
Value iteration (VI) is a foundational dynamic programming method, important for learning and planning in optimal control and reinforcement learning. VI proceeds in batches, where the update to the value of each state must be completed before the next batch of updates can begin. Completing a single batch is prohibitively expensive if the state space is large, rendering VI impractical for many applications. Asynchronous VI helps to address the large state space problem by updating one state at a time, in-place and in an arbitrary order. However, Asynchronous VI still requires a maximization over the entire action space, making it impractical for domains with large action space. To address this issue, we propose doubly-asynchronous value iteration (DAVI), a new algorithm that generalizes the idea of asynchrony from states to states and actions. More concretely, DAVI maximizes over a sampled subset of actions that can be of any user-defined size. This simple approach of using sampling to reduce computation maintains similarly appealing theoretical properties to VI without the need to wait for a full sweep through the entire action space in each update. In this paper, we show DAVI converges to the optimal value function with probability one, converges at a near-geometric rate with probability 1-delta, and returns a near-optimal policy in computation time that nearly matches a previously established bound for VI. We also empirically demonstrate DAVI's effectiveness in several experiments.
Joint Adversarial Learning for Cross-domain Fair Classification
Jun 08, 2022



Modern machine learning (ML) models are becoming increasingly popular and are widely used in decision-making systems. However, studies have shown critical issues of ML discrimination and unfairness, which hinder their adoption on high-stake applications. Recent research on fair classifiers has drawn significant attention to develop effective algorithms to achieve fairness and good classification performance. Despite the great success of these fairness-aware machine learning models, most of the existing models require sensitive attributes to preprocess the data, regularize the model learning or postprocess the prediction to have fair predictions. However, sensitive attributes are often incomplete or even unavailable due to privacy, legal or regulation restrictions. Though we lack the sensitive attribute for training a fair model in the target domain, there might exist a similar domain that has sensitive attributes. Thus, it is important to exploit auxiliary information from the similar domain to help improve fair classification in the target domain. Therefore, in this paper, we study a novel problem of exploring domain adaptation for fair classification. We propose a new framework that can simultaneously estimate the sensitive attributes while learning a fair classifier in the target domain. Extensive experiments on real-world datasets illustrate the effectiveness of the proposed model for fair classification, even when no sensitive attributes are available in the target domain.