 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering the Impact of Chain-of-Thought Reasoning for Direct Preference Optimization: Lessons from Text-to-SQL
Feb 17, 2025



Direct Preference Optimization (DPO) has proven effective in complex reasoning tasks like math word problems and code generation. However, when applied to Text-to-SQL datasets, it often fails to improve performance and can even degrade it. Our investigation reveals the root cause: unlike math and code tasks, which naturally integrate Chain-of-Thought (CoT) reasoning with DPO, Text-to-SQL datasets typically include only final answers (gold SQL queries) without detailed CoT solutions. By augmenting Text-to-SQL datasets with synthetic CoT solutions, we achieve, for the first time, consistent and significant performance improvements using DPO. Our analysis shows that CoT reasoning is crucial for unlocking DPO's potential, as it mitigates reward hacking, strengthens discriminative capabilities, and improves scalability. These findings offer valuable insights for building more robust Text-to-SQL models. To support further research, we publicly release the code and CoT-enhanced datasets.
WaterMamba: Visual State Space Model for Underwater Image Enhancement
May 14, 2024Underwater imaging often suffers from low quality due to factors affecting light propagation and absorption in water. To improve image quality, some underwater image enhancement (UIE) methods based on convolutional neural networks (CNN) and Transformer have been proposed. However, CNN-based UIE methods are limited in modeling long-range dependencies, and Transformer-based methods involve a large number of parameters and complex self-attention mechanisms, posing efficiency challenges. Considering computational complexity and severe underwater image degradation, a state space model (SSM) with linear computational complexity for UIE, named WaterMamba, is proposed. We propose spatial-channel omnidirectional selective scan (SCOSS) blocks comprising spatial-channel coordinate omnidirectional selective scan (SCCOSS) modules and a multi-scale feedforward network (MSFFN). The SCOSS block models pixel and channel information flow, addressing dependencies. The MSFFN facilitates information flow adjustment and promotes synchronized operations within SCCOSS modules. Extensive experiments showcase WaterMamba's cutting-edge performance with reduced parameters and computational resources, outperforming state-of-the-art methods on various datasets, validating its effectiveness and generalizability. The code will be released on GitHub after acceptance.
Reinforced Swin-Convs Transformer for Underwater Image Enhancement
May 01, 2022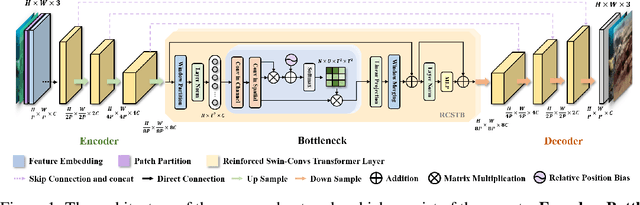
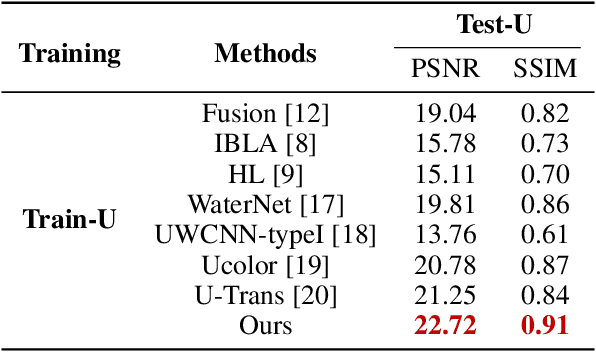
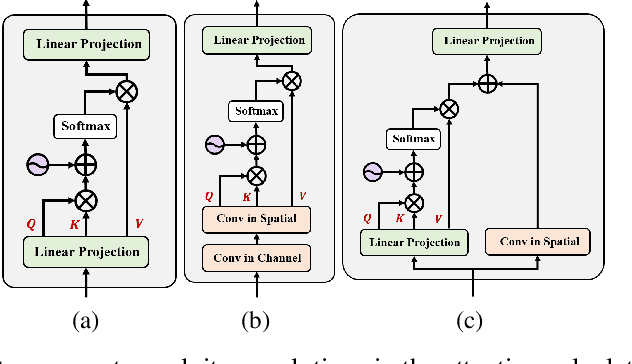
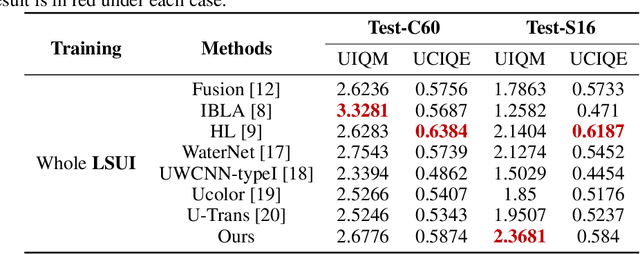
Underwater Image Enhancement (UIE) technology aims to tackle the challenge of restoring the degraded underwater images due to light absorption and scattering. To address problems, a novel U-Net based Reinforced Swin-Convs Transformer for the Underwater Image Enhancement method (URSCT-UIE) is proposed. Specifically, with the deficiency of U-Net based on pure convolutions, we embedded the Swin Transformer into U-Net for improving the ability to capture the global dependency. Then, given the inadequacy of the Swin Transformer capturing the local attention, the reintroduction of convolutions may capture more local attention. Thus, we provide an ingenious manner for the fusion of convolutions and the core attention mechanism to build a Reinforced Swin-Convs Transformer Block (RSCTB) for capturing more local attention, which is reinforced in the channel and the spatial attention of the Swin Transformer. Finally, the experimental results on available datasets demonstrate that the proposed URSCT-UIE achieves state-of-the-art performance compared with other methods in terms of both subjective and objective evaluations. The code will be released on GitHub after acceptance.