 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAG or Learning? Understanding the Limits of LLM Adaptation under Continuous Knowledge Drift in the Real World
Apr 06, 2026Large language models (LLMs) acquire most of their knowledge during pretraining, which ties them to a fixed snapshot of the world and makes adaptation to continuously evolving knowledge challenging. As facts, entities, and events change over time, models may experience continuous knowledge drift, resulting not only in outdated predictions but also in temporally inconsistent reasoning. Although existing approaches, such as continual finetuning, knowledge editing, and retrieval-augmented generation (RAG), aim to update or supplement model knowledge, they are rarely evaluated in settings that reflect chronological, evolving, and real-world knowledge evolution. In this work, we introduce a new benchmark of real-world dynamic events, constructed from time-stamped evidence that captures how knowledge evolves over time, which enables systematic evaluation of model adaptation under continuous knowledge drift. The benchmark reveals that most existing methods, including vanilla RAG and several learning-based approaches, struggle under this setting, exposing critical limitations such as catastrophic forgetting and temporal inconsistency. To mitigate these limitations, we propose a time-aware retrieval baseline, Chronos, which progressively organizes retrieved evidence into an Event Evolution Graph to enable more temporally consistent understanding in LLMs without additional training. Overall, this work provides a foundation for analyzing and advancing LLM adaptation to continuous knowledge drift in realistic settings.
Budget-Constrained Agentic Large Language Models: Intention-Based Planning for Costly Tool Use
Feb 12, 2026We study budget-constrained tool-augmented agents, where a large language model must solve multi-step tasks by invoking external tools under a strict monetary budget. We formalize this setting as sequential decision making in context space with priced and stochastic tool executions, making direct planning intractable due to massive state-action spaces, high variance of outcomes and prohibitive exploration cost. To address these challenges, we propose INTENT, an inference-time planning framework that leverages an intention-aware hierarchical world model to anticipate future tool usage, risk-calibrated cost, and guide decisions online. Across cost-augmented StableToolBench, INTENT strictly enforces hard budget feasibility while substantially improving task success over baselines, and remains robust under dynamic market shifts such as tool price changes and varying budgets.
Bingo: Boosting Efficient Reasoning of LLMs via Dynamic and Significance-based Reinforcement Learning
Jun 09, 2025



Large language models have demonstrated impressive reasoning capabilities, yet they often suffer from inefficiencies due to unnecessarily verbose or redundant outputs. While many works have explored reinforcement learning (RL) to enhance reasoning abilities, most primarily focus on improving accuracy, with limited attention to reasoning efficiency. Some existing approaches introduce direct length-based rewards to encourage brevity, but this often leads to noticeable drops in accuracy. In this paper, we propose Bingo, an RL framework that advances length-based reward design to boost efficient reasoning. Bingo incorporates two key mechanisms: a significance-aware length reward, which gradually guides the model to reduce only insignificant tokens, and a dynamic length reward, which initially encourages elaborate reasoning for hard questions but decays over time to improve overall efficiency. Experiments across multiple reasoning benchmarks show that Bingo improves both accuracy and efficiency. It outperforms the vanilla reward and several other length-based reward baselines in RL, achieving a favorable trade-off between accuracy and efficiency. These results underscore the potential of training LLMs explicitly for efficient reasoning.
Fortune: Formula-Driven Reinforcement Learning for Symbolic Table Reasoning in Language Models
May 29, 2025



Tables are a fundamental structure for organizing and analyzing data, making effective table understanding a critical capability for intelligent systems. While large language models (LMs) demonstrate strong general reasoning abilities, they continue to struggle with accurate numerical or symbolic reasoning over tabular data, especially in complex scenarios. Spreadsheet formulas provide a powerful and expressive medium for representing executable symbolic operations, encoding rich reasoning patterns that remain largely underutilized. In this paper, we propose Formula Tuning (Fortune), a reinforcement learning (RL) framework that trains LMs to generate executable spreadsheet formulas for question answering over general tabular data. Formula Tuning reduces the reliance on supervised formula annotations by using binary answer correctness as a reward signal, guiding the model to learn formula derivation through reasoning. We provide a theoretical analysis of its advantages and demonstrate its effectiveness through extensive experiments on seven table reasoning benchmarks. Formula Tuning substantially enhances LM performance, particularly on multi-step numerical and symbolic reasoning tasks, enabling a 7B model to outperform O1 on table understanding. This highlights the potential of formula-driven RL to advance symbolic table reasoning in LMs.
TwT: Thinking without Tokens by Habitual Reasoning Distillation with Multi-Teachers' Guidance
Mar 31, 2025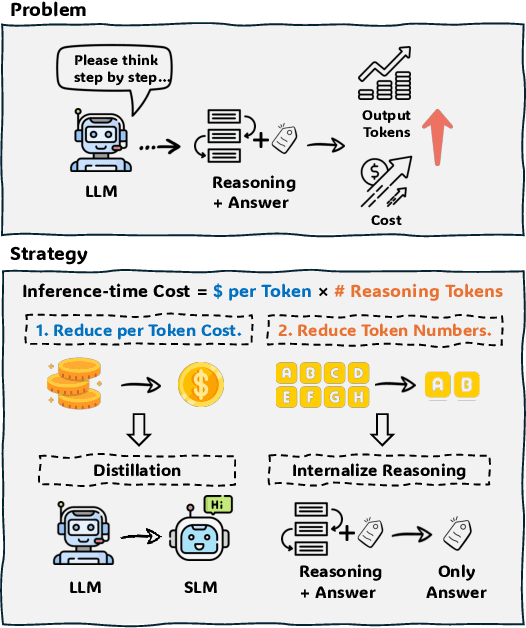
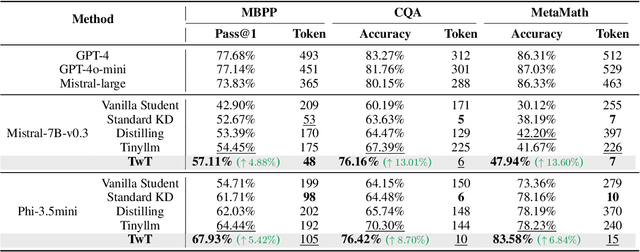
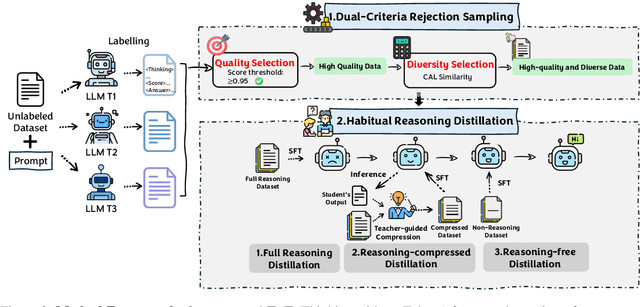
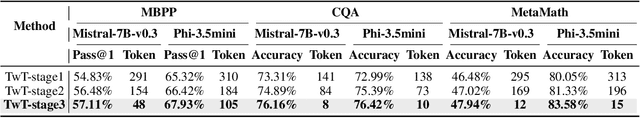
Large Language Models (LLMs) have made significant strides in problem-solving by incorporating reasoning processes. However, this enhanced reasoning capability results in an increased number of output tokens during inference, leading to higher computational costs. To address this challenge, we propose TwT (Thinking without Tokens), a method that reduces inference-time costs through habitual reasoning distillation with multi-teachers' guidance, while maintaining high performance. Our approach introduces a Habitual Reasoning Distillation method, which internalizes explicit reasoning into the model's habitual behavior through a Teacher-Guided compression strategy inspired by human cognition. Additionally, we propose Dual-Criteria Rejection Sampling (DCRS), a technique that generates a high-quality and diverse distillation dataset using multiple teacher models, making our method suitable for unsupervised scenarios. Experimental results demonstrate that TwT effectively reduces inference costs while preserving superior performance, achieving up to a 13.6% improvement in accuracy with fewer output tokens compared to other distillation methods, offering a highly practical solution for efficient LLM deployment.
Exploiting Task Relationships for Continual Learning Using Transferability-Aware Task Embeddings
Feb 17, 2025



Continual learning (CL) has been an essential topic in the contemporary application of deep neural networks, where catastrophic forgetting (CF) can impede a model's ability to acquire knowledge progressively. Existing CL strategies primarily address CF by regularizing model updates or separating task-specific and shared components. However, these methods focus on task model elements while overlooking the potential of leveraging inter-task relationships for learning enhancement. To address this, we propose a transferability-aware task embedding named H-embedding and train a hypernet under its guidance to learn task-conditioned model weights for CL tasks. Particularly, H-embedding is introduced based on an information theoretical transferability measure and is designed to be online and easy to compute. The framework is also characterized by notable practicality, which only requires storing a low-dimensional task embedding for each task, and can be efficiently trained in an end-to-end way. Extensive evaluations and experimental analyses on datasets including Permuted MNIST, Cifar10/100, and ImageNet-R demonstrate that our framework performs prominently compared to various baseline methods, displaying great potential in exploiting intrinsic task relationships.
Uncovering the Impact of Chain-of-Thought Reasoning for Direct Preference Optimization: Lessons from Text-to-SQL
Feb 17, 2025



Direct Preference Optimization (DPO) has proven effective in complex reasoning tasks like math word problems and code generation. However, when applied to Text-to-SQL datasets, it often fails to improve performance and can even degrade it. Our investigation reveals the root cause: unlike math and code tasks, which naturally integrate Chain-of-Thought (CoT) reasoning with DPO, Text-to-SQL datasets typically include only final answers (gold SQL queries) without detailed CoT solutions. By augmenting Text-to-SQL datasets with synthetic CoT solutions, we achieve, for the first time, consistent and significant performance improvements using DPO. Our analysis shows that CoT reasoning is crucial for unlocking DPO's potential, as it mitigates reward hacking, strengthens discriminative capabilities, and improves scalability. These findings offer valuable insights for building more robust Text-to-SQL models. To support further research, we publicly release the code and CoT-enhanced datasets.
CodeS: Towards Building Open-source Language Models for Text-to-SQL
Feb 26, 2024
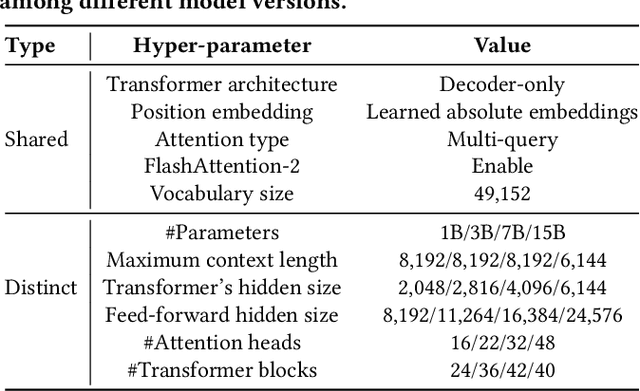

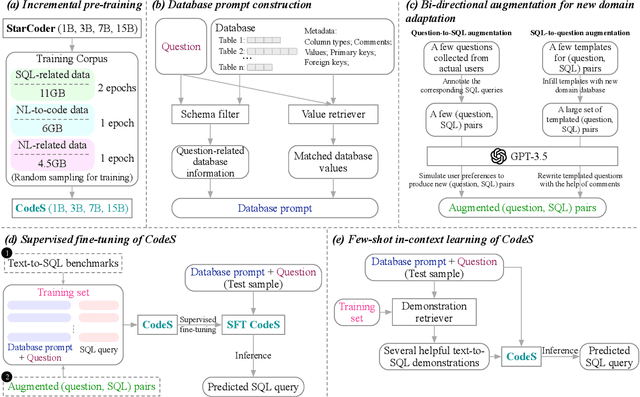
Language models have shown promising performance on the task of translating natural language questions into SQL queries (Text-to-SQL). However, most of the state-of-the-art (SOTA) approaches rely on powerful yet closed-source large language models (LLMs), such as ChatGPT and GPT-4, which may have the limitations of unclear model architectures, data privacy risks, and expensive inference overheads. To address the limitations, we introduce CodeS, a series of pre-trained language models with parameters ranging from 1B to 15B, specifically designed for the text-to-SQL task. CodeS is a fully open-source language model, which achieves superior accuracy with much smaller parameter sizes. This paper studies the research challenges in building CodeS. To enhance the SQL generation abilities of CodeS, we adopt an incremental pre-training approach using a specifically curated SQL-centric corpus. Based on this, we address the challenges of schema linking and rapid domain adaptation through strategic prompt construction and a bi-directional data augmentation technique. We conduct comprehensive evaluations on multiple datasets, including the widely used Spider benchmark, the newly released BIRD benchmark, robustness-diagnostic benchmarks such as Spider-DK, Spider-Syn, Spider-Realistic, and Dr.Spider, as well as two real-world datasets created for financial and academic applications. The experimental results show that our CodeS achieves new SOTA accuracy and robustness on nearly all challenging text-to-SQL benchmarks.
Enhancing Continuous Domain Adaptation with Multi-Path Transfer Curriculum
Feb 26, 2024Addressing the large distribution gap between training and testing data has long been a challenge in machine learning, giving rise to fields such as transfer learning and domain adaptation. Recently, Continuous Domain Adaptation (CDA) has emerged as an effective technique, closing this gap by utilizing a series of intermediate domains. This paper contributes a novel CDA method, W-MPOT, which rigorously addresses the domain ordering and error accumulation problems overlooked by previous studies. Specifically, we construct a transfer curriculum over the source and intermediate domains based on Wasserstein distance, motivated by theoretical analysis of CDA. Then we transfer the source model to the target domain through multiple valid paths in the curriculum using a modified version of continuous optimal transport. A bidirectional path consistency constraint is introduced to mitigate the impact of accumulated mapping errors during continuous transfer. We extensively evaluate W-MPOT on multiple datasets, achieving up to 54.1\% accuracy improvement on multi-session Alzheimer MR image classification and 94.7\% MSE reduction on battery capacity estimation.
Refined Temporal Pyramidal Compression-and-Amplification Transformer for 3D Human Pose Estimation
Sep 06, 2023Accurately estimating the 3D pose of humans in video sequences requires both accuracy and a well-structured architecture. With the success of transformers, we introduce the Refined Temporal Pyramidal Compression-and-Amplification (RTPCA) transformer. Exploiting the temporal dimension, RTPCA extends intra-block temporal modeling via its Temporal Pyramidal Compression-and-Amplification (TPCA) structure and refines inter-block feature interaction with a Cross-Layer Refinement (XLR) module. In particular, TPCA block exploits a temporal pyramid paradigm, reinforcing key and value representation capabilities and seamlessly extracting spatial semantics from motion sequences. We stitch these TPCA blocks with XLR that promotes rich semantic representation through continuous interaction of queries, keys, and values. This strategy embodies early-stage information with current flows, addressing typical deficits in detail and stability seen in other transformer-based methods. We demonstrate the effectiveness of RTPCA by achieving state-of-the-art results on Human3.6M, HumanEva-I, and MPI-INF-3DHP benchmarks with minimal computational overhead. The source code is available at https://github.com/hbing-l/RTPCA.