 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFPQVAR: Floating Point Quantization for Visual Autoregressive Model with FPGA Hardware Co-design
May 22, 2025Visual autoregressive (VAR) modeling has marked a paradigm shift in image generation from next-token prediction to next-scale prediction. VAR predicts a set of tokens at each step from coarse to fine scale, leading to better image quality and faster inference speed compared to existing diffusion models. However, the large parameter size and computation cost hinder its deployment on edge devices. To reduce the memory and computation cost, we propose FPQVAR, an efficient post-training floating-point (FP) quantization framework for VAR featuring algorithm and hardware co-design. At the algorithm level, we first identify the challenges of quantizing VAR. To address them, we propose Dual Format Quantization for the highly imbalanced input activation. We further propose Group-wise Hadamard Transformation and GHT-Aware Learnable Transformation to address the time-varying outlier channels. At the hardware level, we design the first low-bit FP quantizer and multiplier with lookup tables on FPGA and propose the first FPGA-based VAR accelerator featuring low-bit FP computation and an elaborate two-level pipeline. Extensive experiments show that compared to the state-of-the-art quantization method, our proposed FPQVAR significantly improves Fr\'echet Inception Distance (FID) from 10.83 to 3.58, Inception Score (IS) from 175.9 to 241.5 under 4-bit quantization. FPQVAR also significantly improves the performance of 6-bit quantized VAR, bringing it on par with the FP16 model. Our accelerator on AMD-Xilinx VCK190 FPGA achieves a throughput of 1.1 image/s, which is 3.1x higher than the integer-based accelerator. It also demonstrates 3.6x and 2.8x higher energy efficiency compared to the integer-based accelerator and GPU baseline, respectively.
LightMamba: Efficient Mamba Acceleration on FPGA with Quantization and Hardware Co-design
Feb 21, 2025State space models (SSMs) like Mamba have recently attracted much attention. Compared to Transformer-based large language models (LLMs), Mamba achieves linear computation complexity with the sequence length and demonstrates superior performance. However, Mamba is hard to accelerate due to the scattered activation outliers and the complex computation dependency, rendering existing LLM accelerators inefficient. In this paper, we propose LightMamba that co-designs the quantization algorithm and FPGA accelerator architecture for efficient Mamba inference. We first propose an FPGA-friendly post-training quantization algorithm that features rotation-assisted quantization and power-of-two SSM quantization to reduce the majority of computation to 4-bit. We further design an FPGA accelerator that partially unrolls the Mamba computation to balance the efficiency and hardware costs. Through computation reordering as well as fine-grained tiling and fusion, the hardware utilization and memory efficiency of the accelerator get drastically improved. We implement LightMamba on Xilinx Versal VCK190 FPGA and achieve 4.65x to 6.06x higher energy efficiency over the GPU baseline. When evaluated on Alveo U280 FPGA, LightMamba reaches 93 tokens/s, which is 1.43x that of the GPU baseline.
CodeS: Towards Building Open-source Language Models for Text-to-SQL
Feb 26, 2024
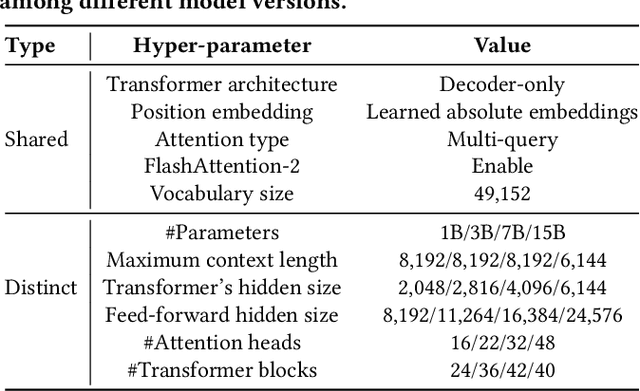

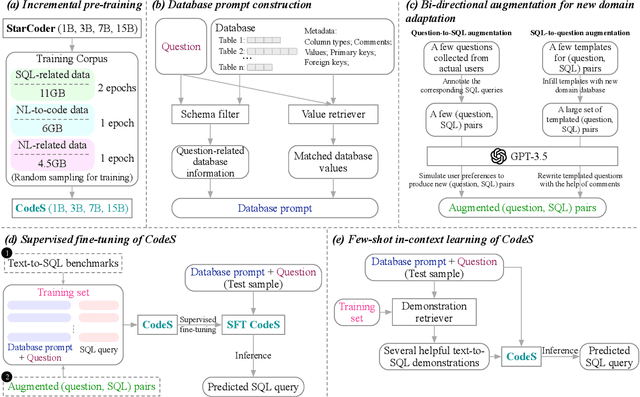
Language models have shown promising performance on the task of translating natural language questions into SQL queries (Text-to-SQL). However, most of the state-of-the-art (SOTA) approaches rely on powerful yet closed-source large language models (LLMs), such as ChatGPT and GPT-4, which may have the limitations of unclear model architectures, data privacy risks, and expensive inference overheads. To address the limitations, we introduce CodeS, a series of pre-trained language models with parameters ranging from 1B to 15B, specifically designed for the text-to-SQL task. CodeS is a fully open-source language model, which achieves superior accuracy with much smaller parameter sizes. This paper studies the research challenges in building CodeS. To enhance the SQL generation abilities of CodeS, we adopt an incremental pre-training approach using a specifically curated SQL-centric corpus. Based on this, we address the challenges of schema linking and rapid domain adaptation through strategic prompt construction and a bi-directional data augmentation technique. We conduct comprehensive evaluations on multiple datasets, including the widely used Spider benchmark, the newly released BIRD benchmark, robustness-diagnostic benchmarks such as Spider-DK, Spider-Syn, Spider-Realistic, and Dr.Spider, as well as two real-world datasets created for financial and academic applications. The experimental results show that our CodeS achieves new SOTA accuracy and robustness on nearly all challenging text-to-SQL benchmarks.
EBSR: Enhanced Binary Neural Network for Image Super-Resolution
Mar 22, 2023While the performance of deep convolutional neural networks for image super-resolution (SR) has improved significantly, the rapid increase of memory and computation requirements hinders their deployment on resource-constrained devices. Quantized networks, especially binary neural networks (BNN) for SR have been proposed to significantly improve the model inference efficiency but suffer from large performance degradation. We observe the activation distribution of SR networks demonstrates very large pixel-to-pixel, channel-to-channel, and image-to-image variation, which is important for high performance SR but gets lost during binarization. To address the problem, we propose two effective methods, including the spatial re-scaling as well as channel-wise shifting and re-scaling, which augments binary convolutions by retaining more spatial and channel-wise information. Our proposed models, dubbed EBSR, demonstrate superior performance over prior art methods both quantitatively and qualitatively across different datasets and different model sizes. Specifically, for x4 SR on Set5 and Urban100, EBSRlight improves the PSNR by 0.31 dB and 0.28 dB compared to SRResNet-E2FIF, respectively, while EBSR outperforms EDSR-E2FIF by 0.29 dB and 0.32 dB PSNR, respectively.