 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKEEP: A KV-Cache-Centric Memory Management System for Efficient Embodied Planning
Feb 27, 2026Memory-augmented Large Language Models (LLMs) have demonstrated remarkable capability for complex and long-horizon embodied planning. By keeping track of past experiences and environmental states, memory enables LLMs to maintain a global view, thereby avoiding repetitive exploration. However, existing approaches often store the memory as raw text, leading to excessively long prompts and high prefill latency. While it is possible to store and reuse the KV caches, the efficiency benefits are greatly undermined due to frequent KV cache updates. In this paper, we propose KEEP, a KV-cache-centric memory management system for efficient embodied planning. KEEP features 3 key innovations: (1) a Static-Dynamic Memory Construction algorithm that reduces KV cache recomputation by mixed-granularity memory group; (2) a Multi-hop Memory Re-computation algorithm that dynamically identifies important cross-attention among different memory groups and reconstructs memory interactions iteratively; (3) a Layer-balanced Memory Loading that eliminates unbalanced KV cache loading and cross-attention computation across different layers. Extensive experimental results have demonstrated that KEEP achieves 2.68x speedup with negligible accuracy loss compared with text-based memory methods on ALFRED dataset. Compared with the KV re-computation method CacheBlend (EuroSys'25), KEEP shows 4.13% success rate improvement and 1.90x time-to-first-token (TTFT) reduction. Our code is available on https://github.com/PKU-SEC-Lab/KEEP_Embodied_Memory.
DySL-VLA: Efficient Vision-Language-Action Model Inference via Dynamic-Static Layer-Skipping for Robot Manipulation
Feb 26, 2026Vision-Language-Action (VLA) models have shown remarkable success in robotic tasks like manipulation by fusing a language model's reasoning with a vision model's 3D understanding. However, their high computational cost remains a major obstacle for real-world applications that require real-time performance. We observe that the actions within a task have varying levels of importance: critical steps demand high precision, while less important ones can tolerate more variance. Leveraging this insight, we propose DySL-VLA, a novel framework that addresses computational cost by dynamically skipping VLA layers based on each action's importance. DySL-VLA categorizes its layers into two types: informative layers, which are consistently executed, and incremental layers, which can be selectively skipped. To intelligently skip layers without sacrificing accuracy, we invent a prior-post skipping guidance mechanism to determine when to initiate layer-skipping. We also propose a skip-aware two-stage knowledge distillation algorithm to efficiently train a standard VLA into a DySL-VLA. Our experiments indicate that DySL-VLA achieves 2.1% improvement in success length over Deer-VLA on the Calvin dataset, while simultaneously reducing trainable parameters by a factor of 85.7 and providing a 3.75x speedup relative to the RoboFlamingo baseline at iso-accuracy. Our code is available on https://github.com/PKU-SEC-Lab/DYSL_VLA.
LightMamba: Efficient Mamba Acceleration on FPGA with Quantization and Hardware Co-design
Feb 21, 2025State space models (SSMs) like Mamba have recently attracted much attention. Compared to Transformer-based large language models (LLMs), Mamba achieves linear computation complexity with the sequence length and demonstrates superior performance. However, Mamba is hard to accelerate due to the scattered activation outliers and the complex computation dependency, rendering existing LLM accelerators inefficient. In this paper, we propose LightMamba that co-designs the quantization algorithm and FPGA accelerator architecture for efficient Mamba inference. We first propose an FPGA-friendly post-training quantization algorithm that features rotation-assisted quantization and power-of-two SSM quantization to reduce the majority of computation to 4-bit. We further design an FPGA accelerator that partially unrolls the Mamba computation to balance the efficiency and hardware costs. Through computation reordering as well as fine-grained tiling and fusion, the hardware utilization and memory efficiency of the accelerator get drastically improved. We implement LightMamba on Xilinx Versal VCK190 FPGA and achieve 4.65x to 6.06x higher energy efficiency over the GPU baseline. When evaluated on Alveo U280 FPGA, LightMamba reaches 93 tokens/s, which is 1.43x that of the GPU baseline.
Inherently Interpretable Tree Ensemble Learning
Oct 24, 2024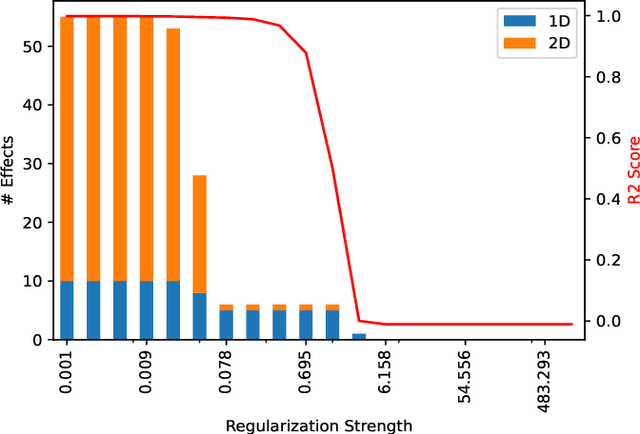
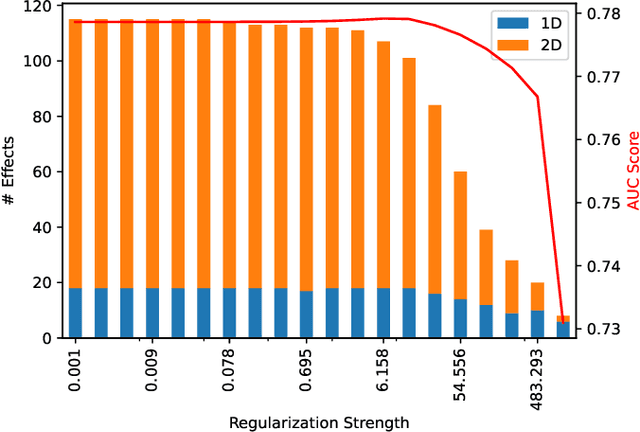
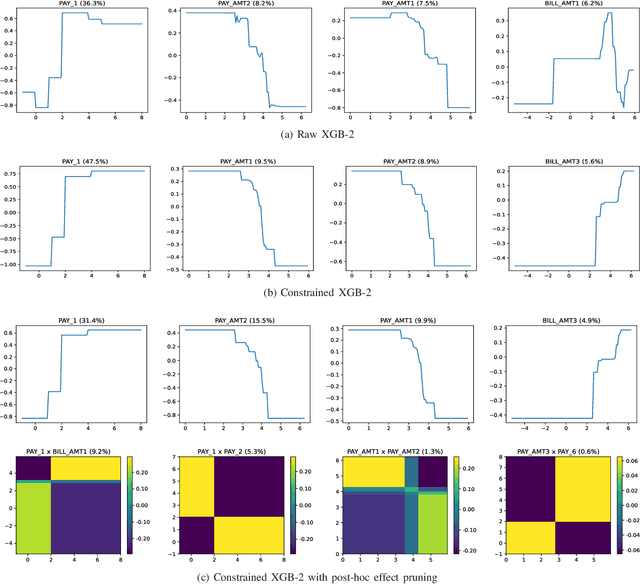
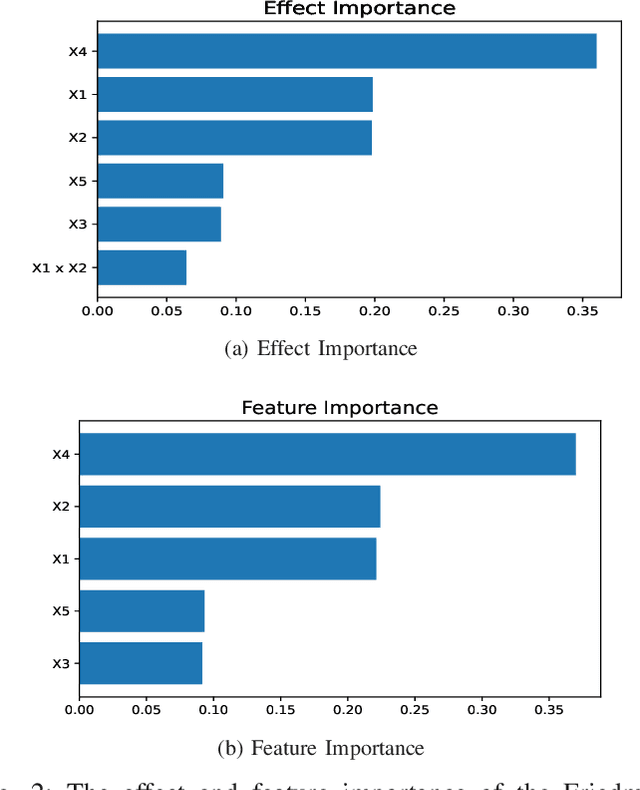
Tree ensemble models like random forests and gradient boosting machines are widely used in machine learning due to their excellent predictive performance. However, a high-performance ensemble consisting of a large number of decision trees lacks sufficient transparency and explainability. In this paper, we demonstrate that when shallow decision trees are used as base learners, the ensemble learning algorithms can not only become inherently interpretable subject to an equivalent representation as the generalized additive models but also sometimes lead to better generalization performance. First, an interpretation algorithm is developed that converts the tree ensemble into the functional ANOVA representation with inherent interpretability. Second, two strategies are proposed to further enhance the model interpretability, i.e., by adding constraints in the model training stage and post-hoc effect pruning. Experiments on simulations and real-world datasets show that our proposed methods offer a better trade-off between model interpretation and predictive performance, compared with its counterpart benchmarks.
MCUBERT: Memory-Efficient BERT Inference on Commodity Microcontrollers
Oct 23, 2024



In this paper, we propose MCUBERT to enable language models like BERT on tiny microcontroller units (MCUs) through network and scheduling co-optimization. We observe the embedding table contributes to the major storage bottleneck for tiny BERT models. Hence, at the network level, we propose an MCU-aware two-stage neural architecture search algorithm based on clustered low-rank approximation for embedding compression. To reduce the inference memory requirements, we further propose a novel fine-grained MCU-friendly scheduling strategy. Through careful computation tiling and re-ordering as well as kernel design, we drastically increase the input sequence lengths supported on MCUs without any latency or accuracy penalty. MCUBERT reduces the parameter size of BERT-tiny and BERT-mini by 5.7$\times$ and 3.0$\times$ and the execution memory by 3.5$\times$ and 4.3$\times$, respectively. MCUBERT also achieves 1.5$\times$ latency reduction. For the first time, MCUBERT enables lightweight BERT models on commodity MCUs and processing more than 512 tokens with less than 256KB of memory.
FastQuery: Communication-efficient Embedding Table Query for Private LLM Inference
May 25, 2024With the fast evolution of large language models (LLMs), privacy concerns with user queries arise as they may contain sensitive information. Private inference based on homomorphic encryption (HE) has been proposed to protect user query privacy. However, a private embedding table query has to be formulated as a HE-based matrix-vector multiplication problem and suffers from enormous computation and communication overhead. We observe the overhead mainly comes from the neglect of 1) the one-hot nature of user queries and 2) the robustness of the embedding table to low bit-width quantization noise. Hence, in this paper, we propose a private embedding table query optimization framework, dubbed FastQuery. FastQuery features a communication-aware embedding table quantization algorithm and a one-hot-aware dense packing algorithm to simultaneously reduce both the computation and communication costs. Compared to prior-art HE-based frameworks, e.g., Cheetah, Iron, and Bumblebee, FastQuery achieves more than $4.3\times$, $2.7\times$, $1.3\times$ latency reduction, respectively and more than $75.7\times$, $60.2\times$, $20.2\times$ communication reduction, respectively, on both LLAMA-7B and LLAMA-30B.
ProPD: Dynamic Token Tree Pruning and Generation for LLM Parallel Decoding
Feb 21, 2024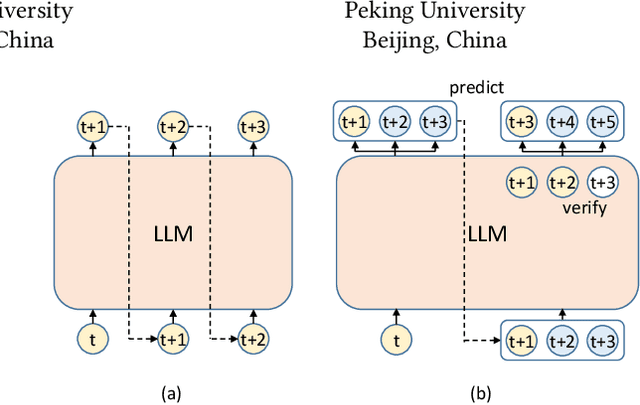
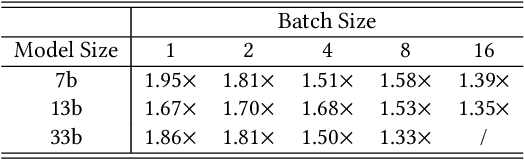
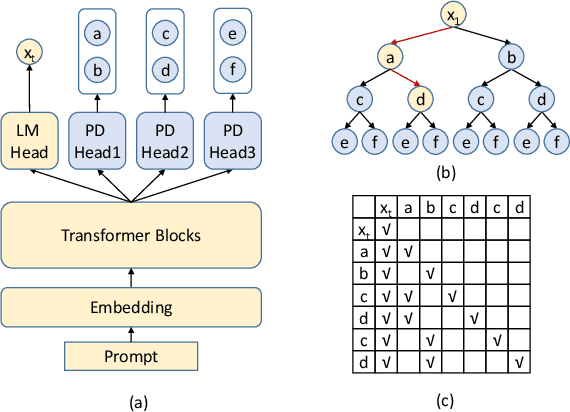
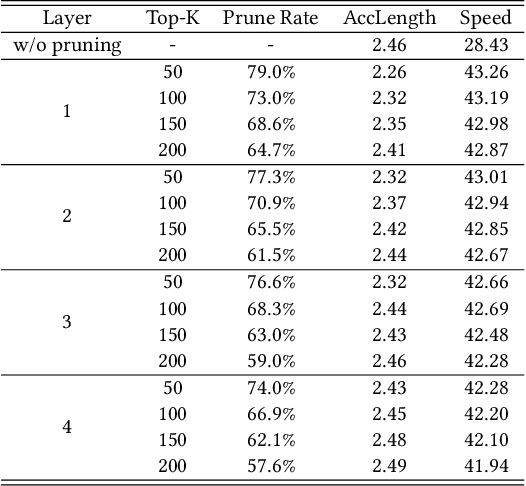
Recent advancements in generative large language models (LLMs) have significantly boosted the performance in natural language processing tasks. However, their efficiency is hampered by the inherent limitations in autoregressive token generation. While parallel decoding with token tree verification, e.g., Medusa, has been proposed to improve decoding parallelism and efficiency, it often struggles with maintaining contextual relationships due to its independent token prediction approach and incurs significant verification overhead, especially with large tree sizes and batch processing. In this paper, we propose ProPD, an efficient LLM parallel decoding framework based on dynamic token tree pruning and generation. ProPD features an advanced early pruning mechanism to efficiently eliminate unpromising token sequences to improve verification efficiency. Additionally, it introduces a dynamic token tree generation algorithm to balance the computation and parallelism of the verification phase in real-time and maximize the overall efficiency across different batch sizes, sequence lengths, and tasks, etc. We verify ProPD across a diverse set of datasets, LLMs, and batch sizes and demonstrate ProPD consistently outperforms existing decoding algorithms by 1.1-3.2x.
AttentionLego: An Open-Source Building Block For Spatially-Scalable Large Language Model Accelerator With Processing-In-Memory Technology
Jan 21, 2024Large language models (LLMs) with Transformer architectures have become phenomenal in natural language processing, multimodal generative artificial intelligence, and agent-oriented artificial intelligence. The self-attention module is the most dominating sub-structure inside Transformer-based LLMs. Computation using general-purpose graphics processing units (GPUs) inflicts reckless demand for I/O bandwidth for transferring intermediate calculation results between memories and processing units. To tackle this challenge, this work develops a fully customized vanilla self-attention accelerator, AttentionLego, as the basic building block for constructing spatially expandable LLM processors. AttentionLego provides basic implementation with fully-customized digital logic incorporating Processing-In-Memory (PIM) technology. It is based on PIM-based matrix-vector multiplication and look-up table-based Softmax design. The open-source code is available online: https://bonany.cc/attentionleg.
PiML Toolbox for Interpretable Machine Learning Model Development and Validation
May 07, 2023PiML (read $\pi$-ML, /`pai.`em.`el/) is an integrated and open-access Python toolbox for interpretable machine learning model development and model diagnostics. It is designed with machine learning workflows in both low-code and high-code modes, including data pipeline, model training, model interpretation and explanation, and model diagnostics and comparison. The toolbox supports a growing list of interpretable models (e.g. GAM, GAMI-Net, XGB2) with inherent local and/or global interpretability. It also supports model-agnostic explainability tools (e.g. PFI, PDP, LIME, SHAP) and a powerful suite of model-agnostic diagnostics (e.g. weakness, uncertainty, robustness, fairness). Integration of PiML models and tests to existing MLOps platforms for quality assurance are enabled by flexible high-code APIs. Furthermore, PiML toolbox comes with a comprehensive user guide and hands-on examples, including the applications for model development and validation in banking. The project is available at https://github.com/SelfExplainML/PiML-Toolbox.
Explainable Recommendation Systems by Generalized Additive Models with Manifest and Latent Interactions
Dec 15, 2020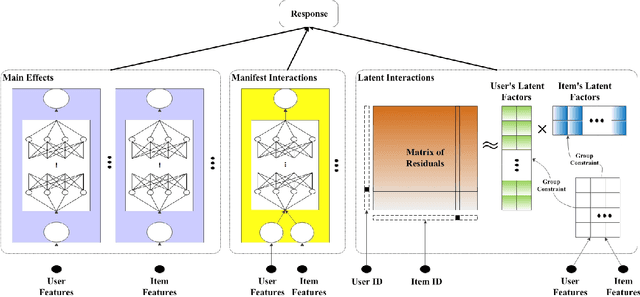
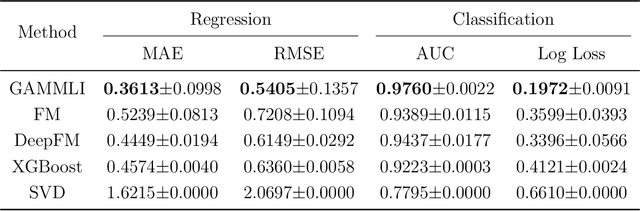
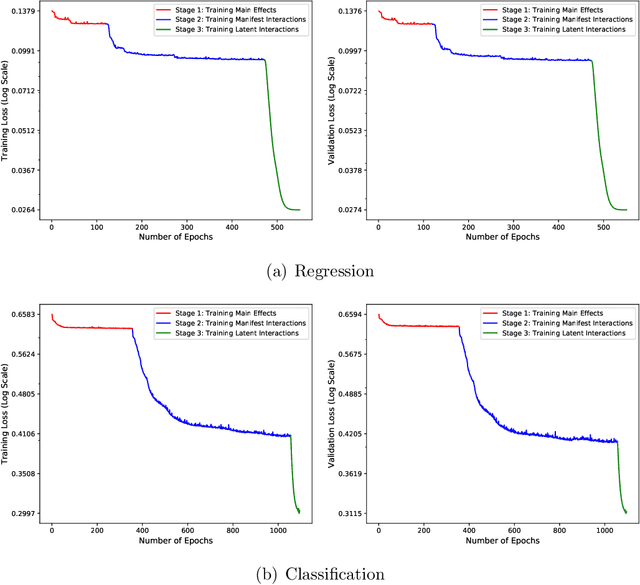
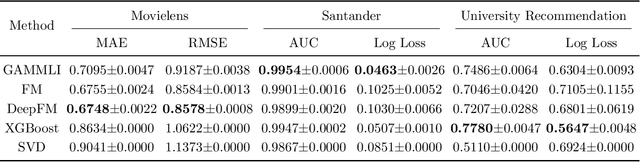
In recent years, the field of recommendation systems has attracted increasing attention to developing predictive models that provide explanations of why an item is recommended to a user. The explanations can be either obtained by post-hoc diagnostics after fitting a relatively complex model or embedded into an intrinsically interpretable model. In this paper, we propose the explainable recommendation systems based on a generalized additive model with manifest and latent interactions (GAMMLI). This model architecture is intrinsically interpretable, as it additively consists of the user and item main effects, the manifest user-item interactions based on observed features, and the latent interaction effects from residuals. Unlike conventional collaborative filtering methods, the group effect of users and items are considered in GAMMLI. It is beneficial for enhancing the model interpretability, and can also facilitate the cold-start recommendation problem. A new Python package GAMMLI is developed for efficient model training and visualized interpretation of the results. By numerical experiments based on simulation data and real-world cases, the proposed method is shown to have advantages in both predictive performance and explainable recommendation.