 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Calibrated Automated Testing and Validation of Generative Language Models
Nov 25, 2024This paper introduces a comprehensive framework for the evaluation and validation of generative language models (GLMs), with a focus on Retrieval-Augmented Generation (RAG) systems deployed in high-stakes domains such as banking. GLM evaluation is challenging due to open-ended outputs and subjective quality assessments. Leveraging the structured nature of RAG systems, where generated responses are grounded in a predefined document collection, we propose the Human-Calibrated Automated Testing (HCAT) framework. HCAT integrates a) automated test generation using stratified sampling, b) embedding-based metrics for explainable assessment of functionality, risk and safety attributes, and c) a two-stage calibration approach that aligns machine-generated evaluations with human judgments through probability calibration and conformal prediction. In addition, the framework includes robustness testing to evaluate model performance against adversarial, out-of-distribution, and varied input conditions, as well as targeted weakness identification using marginal and bivariate analysis to pinpoint specific areas for improvement. This human-calibrated, multi-layered evaluation framework offers a scalable, transparent, and interpretable approach to GLM assessment, providing a practical and reliable solution for deploying GLMs in applications where accuracy, transparency, and regulatory compliance are paramount.
Less Discriminatory Alternative and Interpretable XGBoost Framework for Binary Classification
Oct 24, 2024



Fair lending practices and model interpretability are crucial concerns in the financial industry, especially given the increasing use of complex machine learning models. In response to the Consumer Financial Protection Bureau's (CFPB) requirement to protect consumers against unlawful discrimination, we introduce LDA-XGB1, a novel less discriminatory alternative (LDA) machine learning model for fair and interpretable binary classification. LDA-XGB1 is developed through biobjective optimization that balances accuracy and fairness, with both objectives formulated using binning and information value. It leverages the predictive power and computational efficiency of XGBoost while ensuring inherent model interpretability, including the enforcement of monotonic constraints. We evaluate LDA-XGB1 on two datasets: SimuCredit, a simulated credit approval dataset, and COMPAS, a real-world recidivism prediction dataset. Our results demonstrate that LDA-XGB1 achieves an effective balance between predictive accuracy, fairness, and interpretability, often outperforming traditional fair lending models. This approach equips financial institutions with a powerful tool to meet regulatory requirements for fair lending while maintaining the advantages of advanced machine learning techniques.
Inherently Interpretable Tree Ensemble Learning
Oct 24, 2024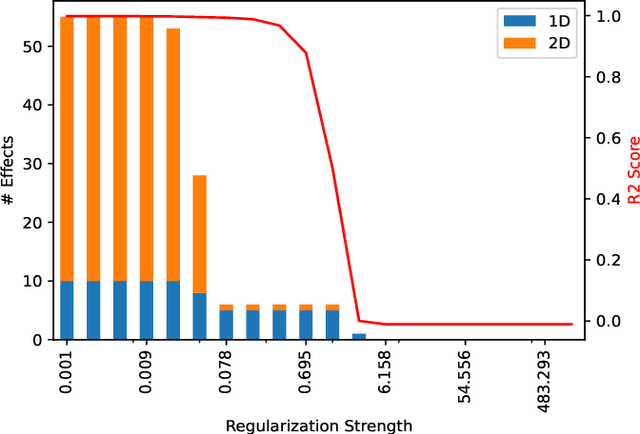
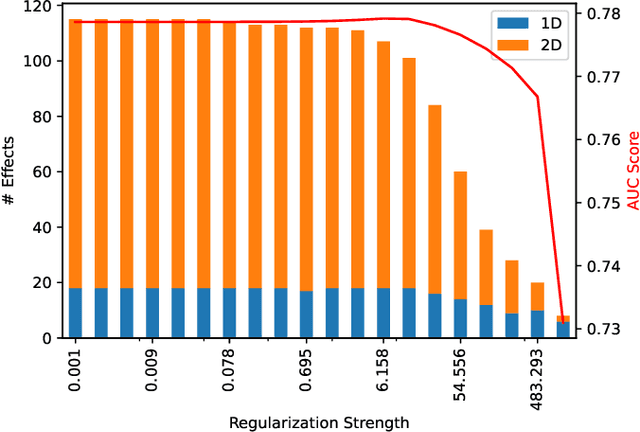
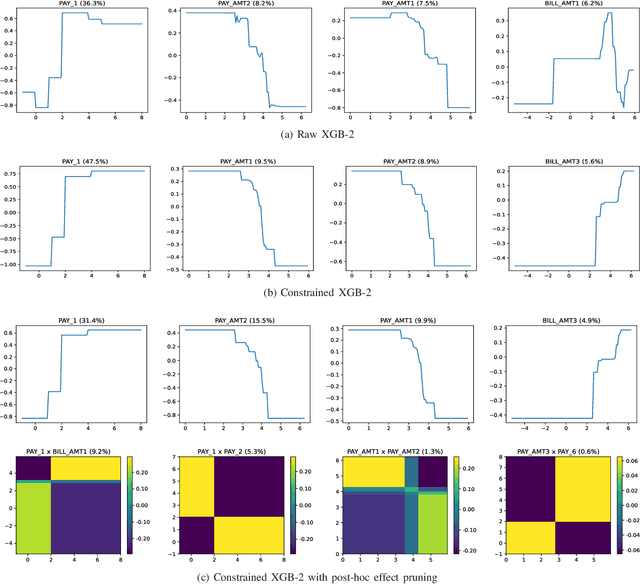
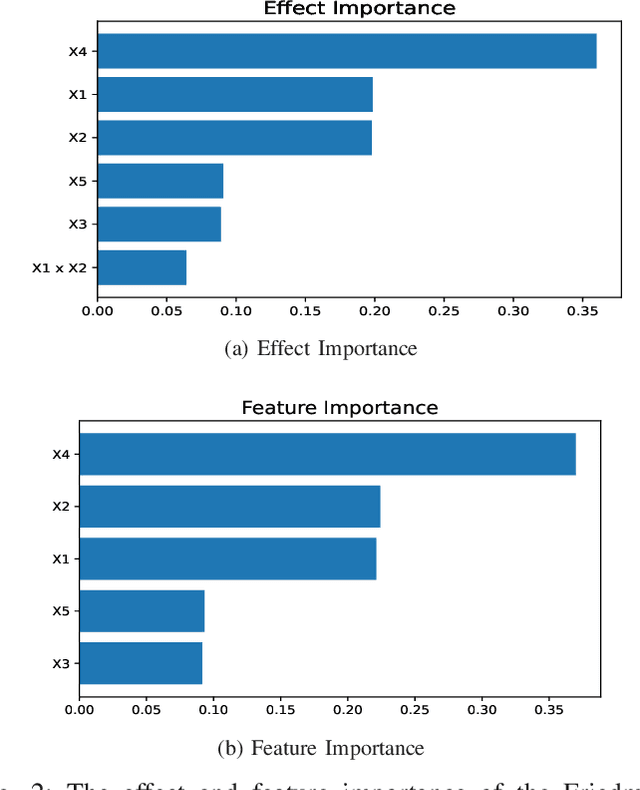
Tree ensemble models like random forests and gradient boosting machines are widely used in machine learning due to their excellent predictive performance. However, a high-performance ensemble consisting of a large number of decision trees lacks sufficient transparency and explainability. In this paper, we demonstrate that when shallow decision trees are used as base learners, the ensemble learning algorithms can not only become inherently interpretable subject to an equivalent representation as the generalized additive models but also sometimes lead to better generalization performance. First, an interpretation algorithm is developed that converts the tree ensemble into the functional ANOVA representation with inherent interpretability. Second, two strategies are proposed to further enhance the model interpretability, i.e., by adding constraints in the model training stage and post-hoc effect pruning. Experiments on simulations and real-world datasets show that our proposed methods offer a better trade-off between model interpretation and predictive performance, compared with its counterpart benchmarks.
Interpretable Machine Learning based on Functional ANOVA Framework: Algorithms and Comparisons
May 25, 2023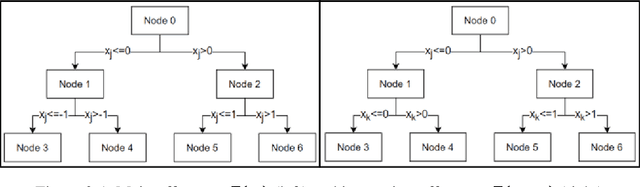
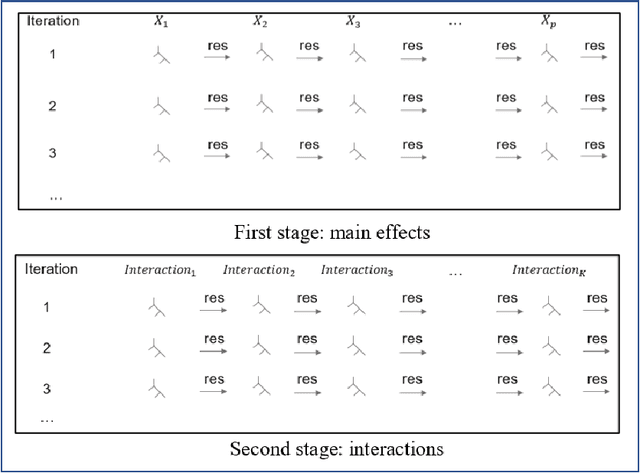
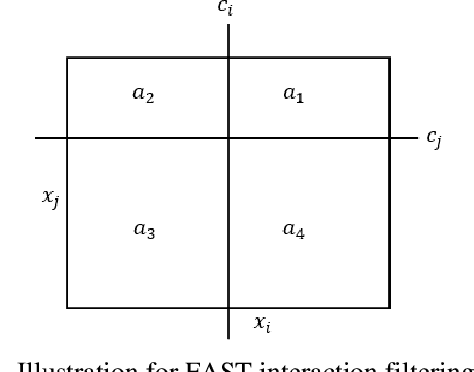
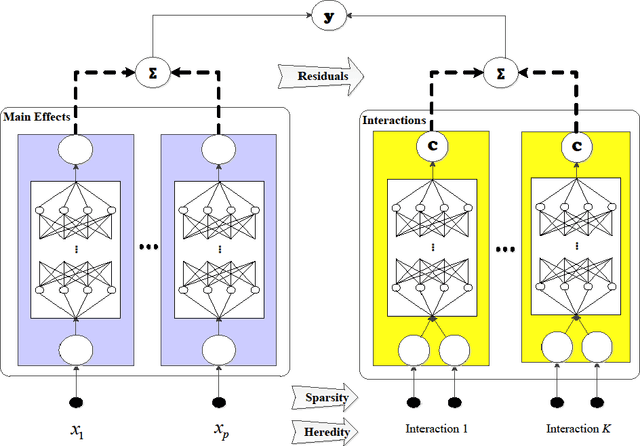
In the early days of machine learning (ML), the emphasis was on developing complex algorithms to achieve best predictive performance. To understand and explain the model results, one had to rely on post hoc explainability techniques, which are known to have limitations. Recently, with the recognition that interpretability is just as important, researchers are compromising on small increases in predictive performance to develop algorithms that are inherently interpretable. While doing so, the ML community has rediscovered the use of low-order functional ANOVA (fANOVA) models that have been known in the statistical literature for some time. This paper starts with a description of challenges with post hoc explainability and reviews the fANOVA framework with a focus on main effects and second-order interactions. This is followed by an overview of two recently developed techniques: Explainable Boosting Machines or EBM (Lou et al., 2013) and GAMI-Net (Yang et al., 2021b). The paper proposes a new algorithm, called GAMI-Lin-T, that also uses trees like EBM, but it does linear fits instead of piecewise constants within the partitions. There are many other differences, including the development of a new interaction filtering algorithm. Finally, the paper uses simulated and real datasets to compare selected ML algorithms. The results show that GAMI-Lin-T and GAMI-Net have comparable performances, and both are generally better than EBM.
Enhancing Robustness of Gradient-Boosted Decision Trees through One-Hot Encoding and Regularization
May 11, 2023Gradient-boosted decision trees (GBDT) are widely used and highly effective machine learning approach for tabular data modeling. However, their complex structure may lead to low robustness against small covariate perturbation in unseen data. In this study, we apply one-hot encoding to convert a GBDT model into a linear framework, through encoding of each tree leaf to one dummy variable. This allows for the use of linear regression techniques, plus a novel risk decomposition for assessing the robustness of a GBDT model against covariate perturbations. We propose to enhance the robustness of GBDT models by refitting their linear regression forms with $L_1$ or $L_2$ regularization. Theoretical results are obtained about the effect of regularization on the model performance and robustness. It is demonstrated through numerical experiments that the proposed regularization approach can enhance the robustness of the one-hot-encoded GBDT models.
PiML Toolbox for Interpretable Machine Learning Model Development and Validation
May 07, 2023PiML (read $\pi$-ML, /`pai.`em.`el/) is an integrated and open-access Python toolbox for interpretable machine learning model development and model diagnostics. It is designed with machine learning workflows in both low-code and high-code modes, including data pipeline, model training, model interpretation and explanation, and model diagnostics and comparison. The toolbox supports a growing list of interpretable models (e.g. GAM, GAMI-Net, XGB2) with inherent local and/or global interpretability. It also supports model-agnostic explainability tools (e.g. PFI, PDP, LIME, SHAP) and a powerful suite of model-agnostic diagnostics (e.g. weakness, uncertainty, robustness, fairness). Integration of PiML models and tests to existing MLOps platforms for quality assurance are enabled by flexible high-code APIs. Furthermore, PiML toolbox comes with a comprehensive user guide and hands-on examples, including the applications for model development and validation in banking. The project is available at https://github.com/SelfExplainML/PiML-Toolbox.
Model-free Subsampling Method Based on Uniform Designs
Sep 08, 2022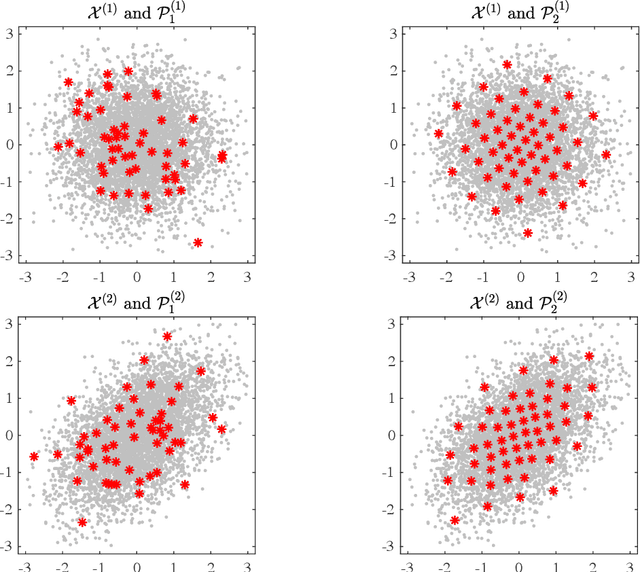
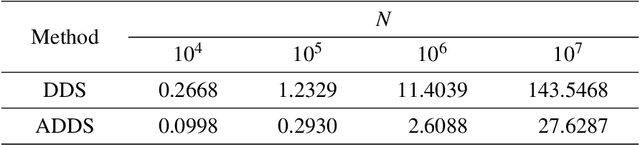
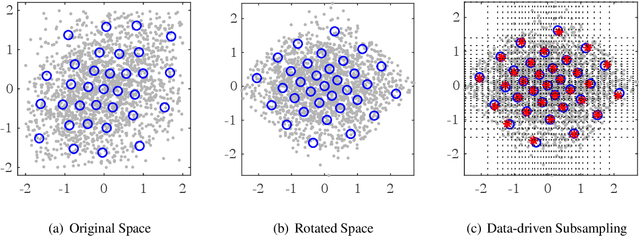
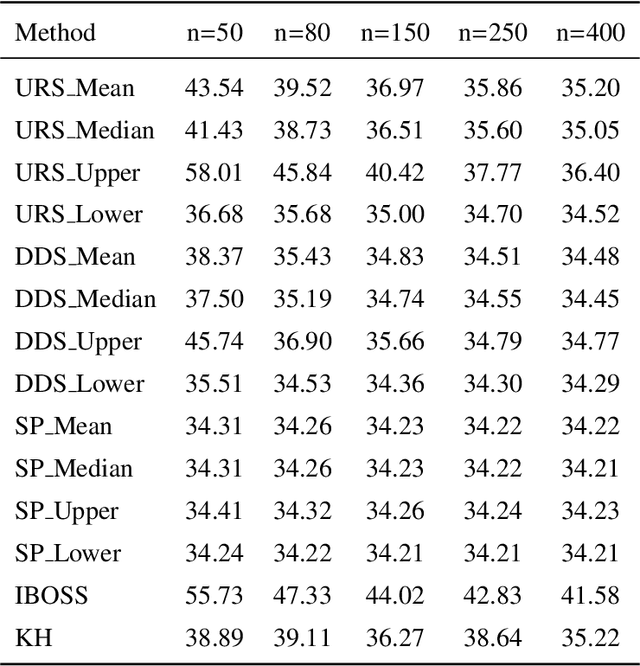
Subsampling or subdata selection is a useful approach in large-scale statistical learning. Most existing studies focus on model-based subsampling methods which significantly depend on the model assumption. In this paper, we consider the model-free subsampling strategy for generating subdata from the original full data. In order to measure the goodness of representation of a subdata with respect to the original data, we propose a criterion, generalized empirical F-discrepancy (GEFD), and study its theoretical properties in connection with the classical generalized L2-discrepancy in the theory of uniform designs. These properties allow us to develop a kind of low-GEFD data-driven subsampling method based on the existing uniform designs. By simulation examples and a real case study, we show that the proposed subsampling method is superior to the random sampling method. Moreover, our method keeps robust under diverse model specifications while other popular subsampling methods are under-performing. In practice, such a model-free property is more appealing than the model-based subsampling methods, where the latter may have poor performance when the model is misspecified, as demonstrated in our simulation studies.
Traversing the Local Polytopes of ReLU Neural Networks: A Unified Approach for Network Verification
Nov 17, 2021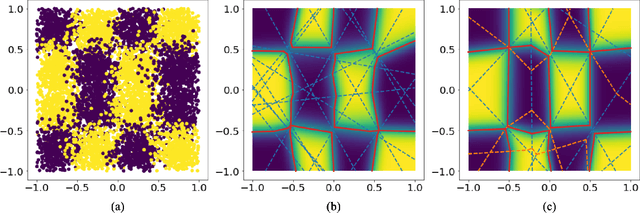
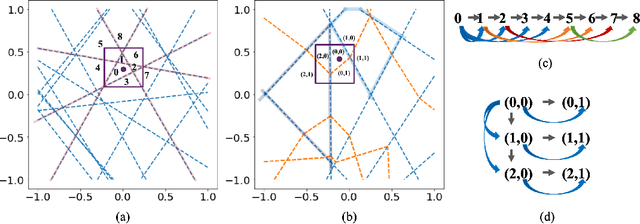
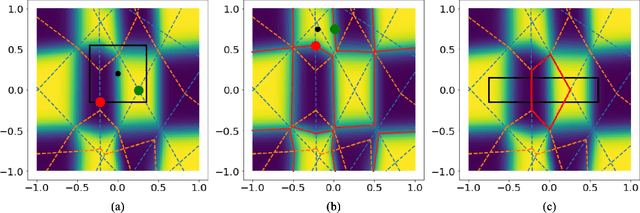
Although neural networks (NNs) with ReLU activation functions have found success in a wide range of applications, their adoption in risk-sensitive settings has been limited by the concerns on robustness and interpretability. Previous works to examine robustness and to improve interpretability partially exploited the piecewise linear function form of ReLU NNs. In this paper, we explore the unique topological structure that ReLU NNs create in the input space, identifying the adjacency among the partitioned local polytopes and developing a traversing algorithm based on this adjacency. Our polytope traversing algorithm can be adapted to verify a wide range of network properties related to robustness and interpretability, providing an unified approach to examine the network behavior. As the traversing algorithm explicitly visits all local polytopes, it returns a clear and full picture of the network behavior within the traversed region. The time and space complexity of the traversing algorithm is determined by the number of a ReLU NN's partitioning hyperplanes passing through the traversing region.
Designing Inherently Interpretable Machine Learning Models
Nov 02, 2021
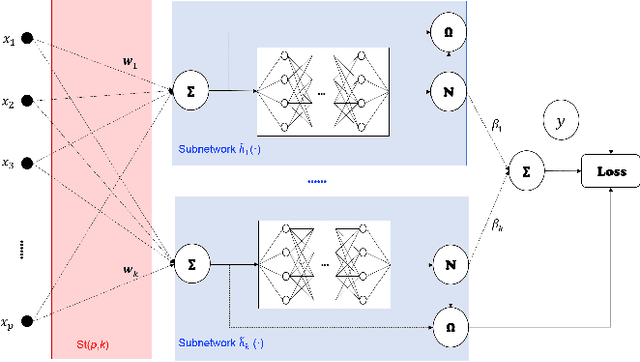

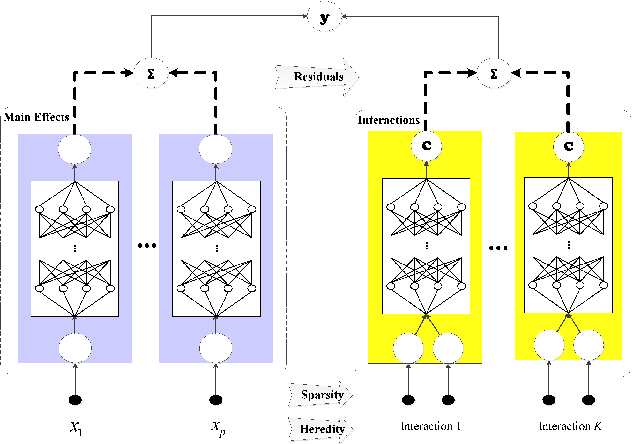
Interpretable machine learning (IML) becomes increasingly important in highly regulated industry sectors related to the health and safety or fundamental rights of human beings. In general, the inherently IML models should be adopted because of their transparency and explainability, while black-box models with model-agnostic explainability can be more difficult to defend under regulatory scrutiny. For assessing inherent interpretability of a machine learning model, we propose a qualitative template based on feature effects and model architecture constraints. It provides the design principles for high-performance IML model development, with examples given by reviewing our recent works on ExNN, GAMI-Net, SIMTree, and the Aletheia toolkit for local linear interpretability of deep ReLU networks. We further demonstrate how to design an interpretable ReLU DNN model with evaluation of conceptual soundness for a real case study of predicting credit default in home lending. We hope that this work will provide a practical guide of developing inherently IML models in high risk applications in banking industry, as well as other sectors.
Explainable Recommendation Systems by Generalized Additive Models with Manifest and Latent Interactions
Dec 15, 2020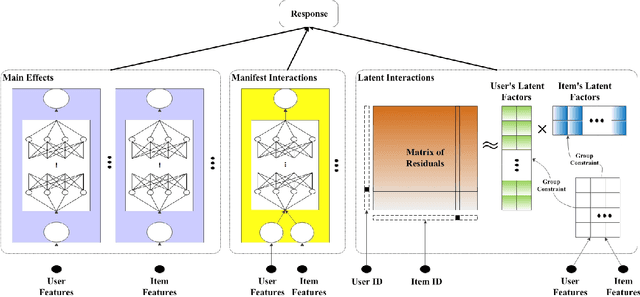
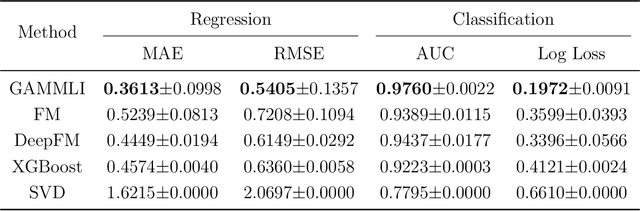
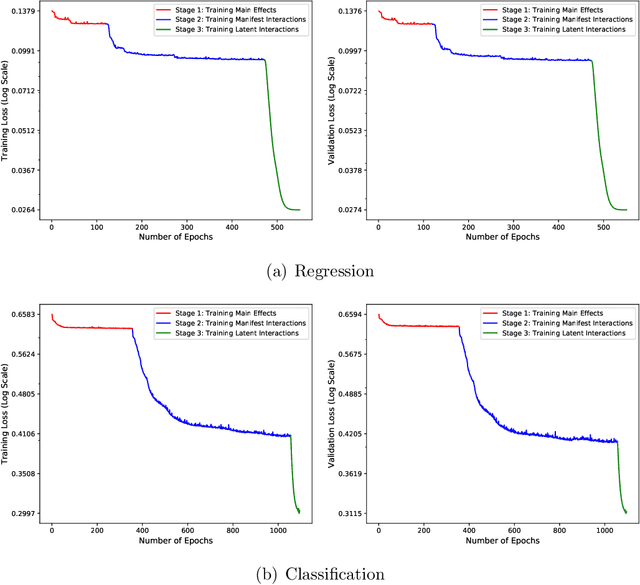
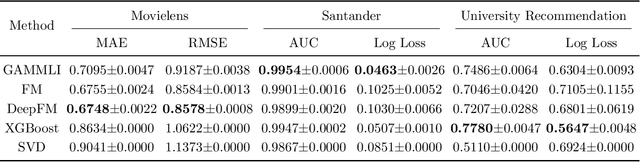
In recent years, the field of recommendation systems has attracted increasing attention to developing predictive models that provide explanations of why an item is recommended to a user. The explanations can be either obtained by post-hoc diagnostics after fitting a relatively complex model or embedded into an intrinsically interpretable model. In this paper, we propose the explainable recommendation systems based on a generalized additive model with manifest and latent interactions (GAMMLI). This model architecture is intrinsically interpretable, as it additively consists of the user and item main effects, the manifest user-item interactions based on observed features, and the latent interaction effects from residuals. Unlike conventional collaborative filtering methods, the group effect of users and items are considered in GAMMLI. It is beneficial for enhancing the model interpretability, and can also facilitate the cold-start recommendation problem. A new Python package GAMMLI is developed for efficient model training and visualized interpretation of the results. By numerical experiments based on simulation data and real-world cases, the proposed method is shown to have advantages in both predictive performance and explainable recommendation.