 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-free Subsampling Method Based on Uniform Designs
Sep 08, 2022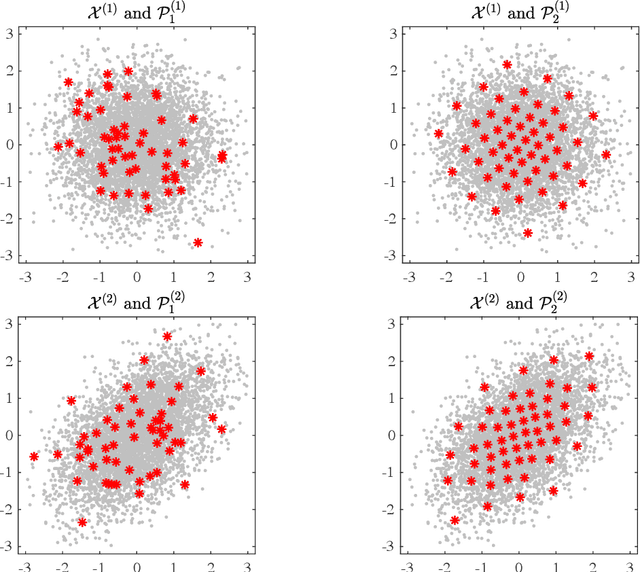
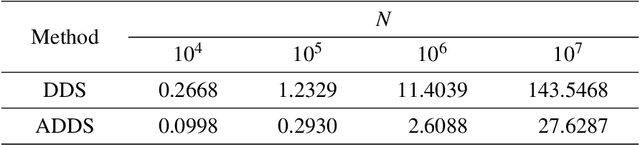
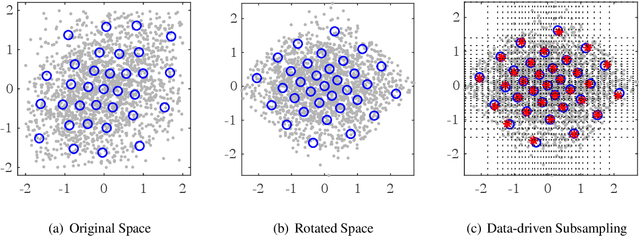
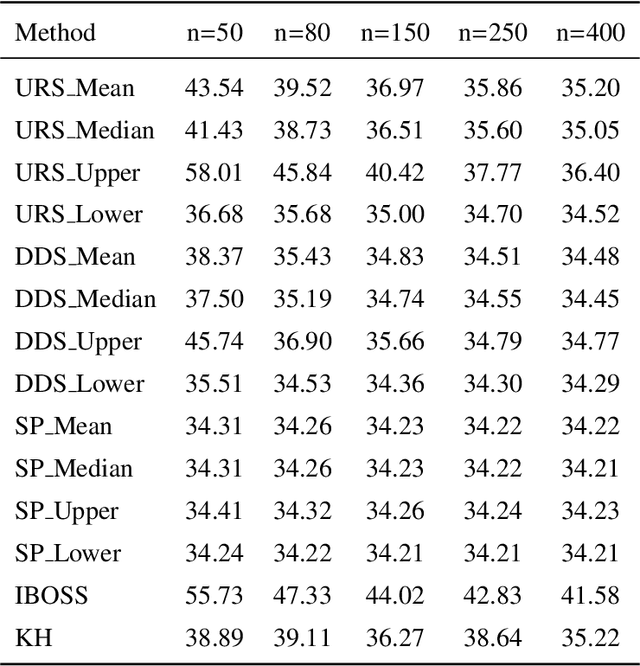
Subsampling or subdata selection is a useful approach in large-scale statistical learning. Most existing studies focus on model-based subsampling methods which significantly depend on the model assumption. In this paper, we consider the model-free subsampling strategy for generating subdata from the original full data. In order to measure the goodness of representation of a subdata with respect to the original data, we propose a criterion, generalized empirical F-discrepancy (GEFD), and study its theoretical properties in connection with the classical generalized L2-discrepancy in the theory of uniform designs. These properties allow us to develop a kind of low-GEFD data-driven subsampling method based on the existing uniform designs. By simulation examples and a real case study, we show that the proposed subsampling method is superior to the random sampling method. Moreover, our method keeps robust under diverse model specifications while other popular subsampling methods are under-performing. In practice, such a model-free property is more appealing than the model-based subsampling methods, where the latter may have poor performance when the model is misspecified, as demonstrated in our simulation studies.
Question Answering over Knowledge Graphs via Structural Query Patterns
Oct 24, 2019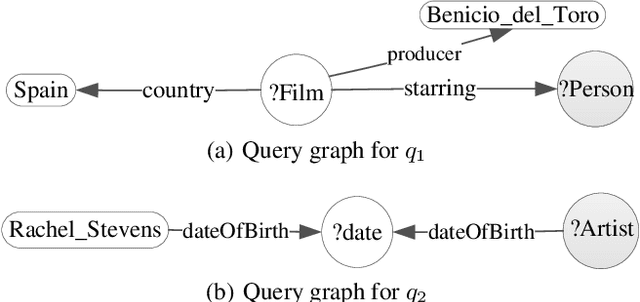

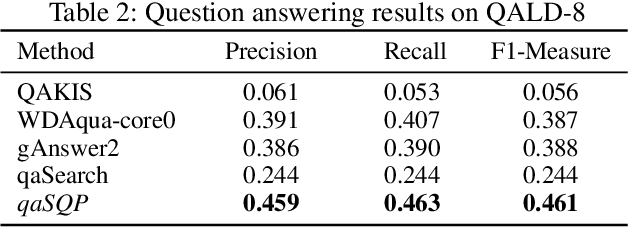
Natural language question answering over knowledge graphs is an important and interesting task as it enables common users to gain accurate answers in an easy and intuitive manner. However, it remains a challenge to bridge the gap between unstructured questions and structured knowledge graphs. To address the problem, a natural discipline is building a structured query to represent the input question. Searching the structured query over the knowledge graph can produce answers to the question. Distinct from the existing methods that are based on semantic parsing or templates, we propose an effective approach powered by a novel notion, structural query pattern, in this paper. Given an input question, we first generate its query sketch that is compatible with the underlying structure of the knowledge graph. Then, we complete the query graph by labeling the nodes and edges under the guidance of the structural query pattern. Finally, answers can be retrieved by executing the constructed query graph over the knowledge graph. Evaluations on three question answering benchmarks show that our proposed approach outperforms state-of-the-art methods significantly.
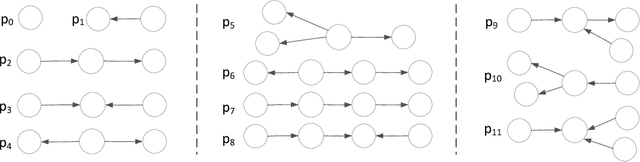
Towards Combinational Relation Linking over Knowledge Graphs
Oct 24, 2019

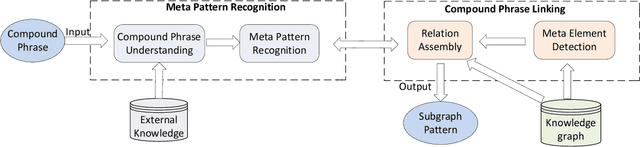
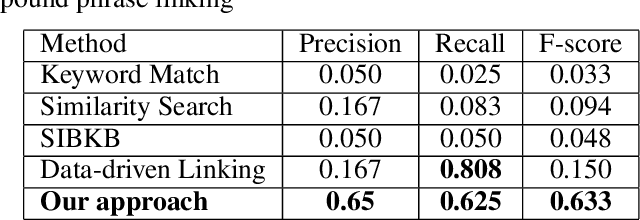
Given a natural language phrase, relation linking aims to find a relation (predicate or property) from the underlying knowledge graph to match the phrase. It is very useful in many applications, such as natural language question answering, personalized recommendation and text summarization. However, the previous relation linking algorithms usually produce a single relation for the input phrase and pay little attention to a more general and challenging problem, i.e., combinational relation linking that extracts a subgraph pattern to match the compound phrase (e.g. mother-in-law). In this paper, we focus on the task of combinational relation linking over knowledge graphs. To resolve the problem, we design a systematic method based on the data-driven relation assembly technique, which is performed under the guidance of meta patterns. We also introduce external knowledge to enhance the system understanding ability. Finally, we conduct extensive experiments over the real knowledge graph to study the performance of the proposed method.