 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudocode-Injection Magic: Enabling LLMs to Tackle Graph Computational Tasks
Jan 23, 2025Graph computational tasks are inherently challenging and often demand the development of advanced algorithms for effective solutions. With the emergence of large language models (LLMs), researchers have begun investigating their potential to address these tasks. However, existing approaches are constrained by LLMs' limited capability to comprehend complex graph structures and their high inference costs, rendering them impractical for handling large-scale graphs. Inspired by human approaches to graph problems, we introduce a novel framework, PIE (Pseudocode-Injection-Enhanced LLM Reasoning for Graph Computational Tasks), which consists of three key steps: problem understanding, prompt design, and code generation. In this framework, LLMs are tasked with understanding the problem and extracting relevant information to generate correct code. The responsibility for analyzing the graph structure and executing the code is delegated to the interpreter. We inject task-related pseudocodes into the prompts to further assist the LLMs in generating efficient code. We also employ cost-effective trial-and-error techniques to ensure that the LLM-generated code executes correctly. Unlike other methods that require invoking LLMs for each individual test case, PIE only calls the LLM during the code generation phase, allowing the generated code to be reused and significantly reducing inference costs. Extensive experiments demonstrate that PIE outperforms existing baselines in terms of both accuracy and computational efficiency.
SimGRAG: Leveraging Similar Subgraphs for Knowledge Graphs Driven Retrieval-Augmented Generation
Dec 17, 2024



Recent advancements in large language models (LLMs) have shown impressive versatility across various tasks. To eliminate its hallucinations, retrieval-augmented generation (RAG) has emerged as a powerful approach, leveraging external knowledge sources like knowledge graphs (KGs). In this paper, we study the task of KG-driven RAG and propose a novel Similar Graph Enhanced Retrieval-Augmented Generation (SimGRAG) method. It effectively addresses the challenge of aligning query texts and KG structures through a two-stage process: (1) query-to-pattern, which uses an LLM to transform queries into a desired graph pattern, and (2) pattern-to-subgraph, which quantifies the alignment between the pattern and candidate subgraphs using a graph semantic distance (GSD) metric. We also develop an optimized retrieval algorithm that efficiently identifies the top-$k$ subgraphs within 1-second latency on a 10-million-scale KG. Extensive experiments show that SimGRAG outperforms state-of-the-art KG-driven RAG methods in both question answering and fact verification, offering superior plug-and-play usability and scalability.
Results of the Big ANN: NeurIPS'23 competition
Sep 25, 2024

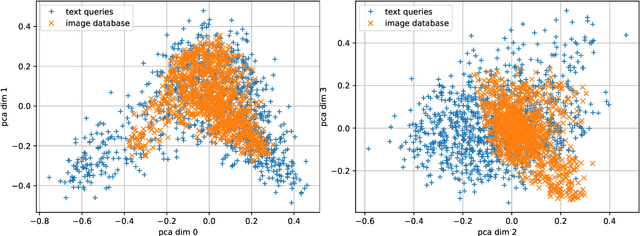

The 2023 Big ANN Challenge, held at NeurIPS 2023, focused on advancing the state-of-the-art in indexing data structures and search algorithms for practical variants of Approximate Nearest Neighbor (ANN) search that reflect the growing complexity and diversity of workloads. Unlike prior challenges that emphasized scaling up classical ANN search ~\cite{DBLP:conf/nips/SimhadriWADBBCH21}, this competition addressed filtered search, out-of-distribution data, sparse and streaming variants of ANNS. Participants developed and submitted innovative solutions that were evaluated on new standard datasets with constrained computational resources. The results showcased significant improvements in search accuracy and efficiency over industry-standard baselines, with notable contributions from both academic and industrial teams. This paper summarizes the competition tracks, datasets, evaluation metrics, and the innovative approaches of the top-performing submissions, providing insights into the current advancements and future directions in the field of approximate nearest neighbor search.
Xiezhi: An Ever-Updating Benchmark for Holistic Domain Knowledge Evaluation
Jun 15, 2023



New Natural Langauge Process~(NLP) benchmarks are urgently needed to align with the rapid development of large language models (LLMs). We present Xiezhi, the most comprehensive evaluation suite designed to assess holistic domain knowledge. Xiezhi comprises multiple-choice questions across 516 diverse disciplines ranging from 13 different subjects with 249,587 questions and accompanied by Xiezhi-Specialty and Xiezhi-Interdiscipline, both with 15k questions. We conduct evaluation of the 47 cutting-edge LLMs on Xiezhi. Results indicate that LLMs exceed average performance of humans in science, engineering, agronomy, medicine, and art, but fall short in economics, jurisprudence, pedagogy, literature, history, and management. We anticipate Xiezhi will help analyze important strengths and shortcomings of LLMs, and the benchmark is released in~\url{https://github.com/MikeGu721/XiezhiBenchmark}.
Controlling Styles in Neural Machine Translation with Activation Prompt
Dec 17, 2022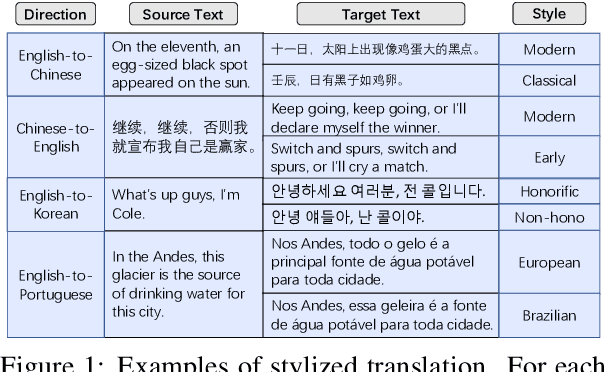

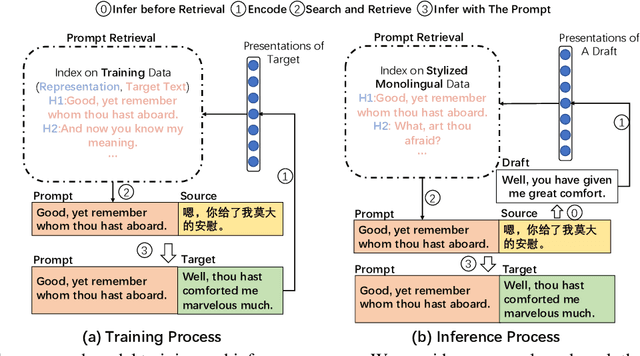

Neural machine translation(NMT) has aroused wide attention due to its impressive quality. Beyond quality, controlling translation styles is also an important demand for many languages. Previous related studies mainly focus on controlling formality and gain some improvements. However, they still face two challenges. The first is the evaluation limitation. Style contains abundant information including lexis, syntax, etc. But only formality is well studied. The second is the heavy reliance on iterative fine-tuning when new styles are required. Correspondingly, this paper contributes in terms of the benchmark and approach. First, we re-visit this task and propose a multiway stylized machine translation (MSMT) benchmark, which includes multiple categories of styles in four language directions to push the boundary of this task. Second, we propose a method named style activation prompt (StyleAP) by retrieving prompts from stylized monolingual corpus, which needs no extra fine-tuning. Experiments show that StyleAP could effectively control the style of translation and achieve remarkable performance. All of our data and code are released at https://github.com/IvanWang0730/StyleAP.
Question Answering over Knowledge Graphs via Structural Query Patterns
Oct 24, 2019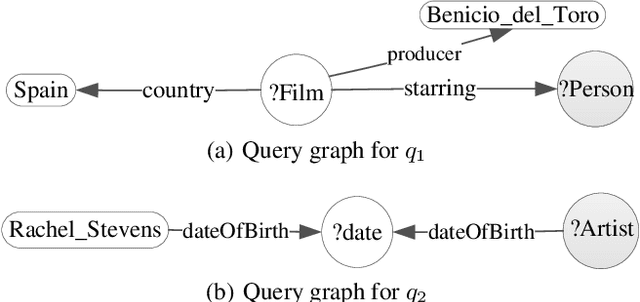

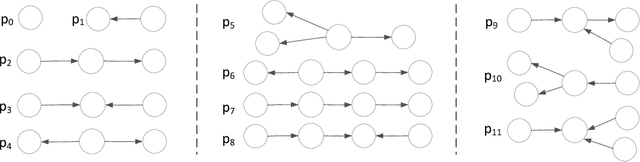
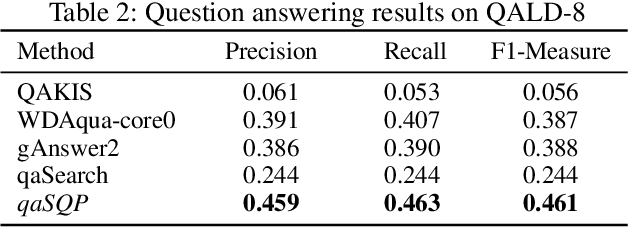
Natural language question answering over knowledge graphs is an important and interesting task as it enables common users to gain accurate answers in an easy and intuitive manner. However, it remains a challenge to bridge the gap between unstructured questions and structured knowledge graphs. To address the problem, a natural discipline is building a structured query to represent the input question. Searching the structured query over the knowledge graph can produce answers to the question. Distinct from the existing methods that are based on semantic parsing or templates, we propose an effective approach powered by a novel notion, structural query pattern, in this paper. Given an input question, we first generate its query sketch that is compatible with the underlying structure of the knowledge graph. Then, we complete the query graph by labeling the nodes and edges under the guidance of the structural query pattern. Finally, answers can be retrieved by executing the constructed query graph over the knowledge graph. Evaluations on three question answering benchmarks show that our proposed approach outperforms state-of-the-art methods significantly.
Towards Combinational Relation Linking over Knowledge Graphs
Oct 24, 2019

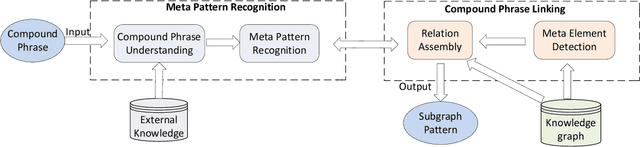
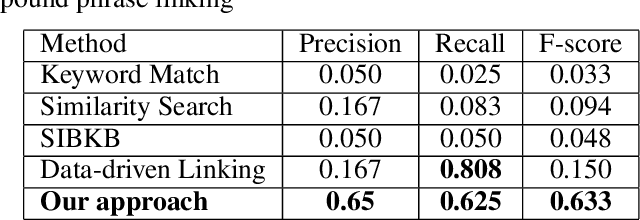
Given a natural language phrase, relation linking aims to find a relation (predicate or property) from the underlying knowledge graph to match the phrase. It is very useful in many applications, such as natural language question answering, personalized recommendation and text summarization. However, the previous relation linking algorithms usually produce a single relation for the input phrase and pay little attention to a more general and challenging problem, i.e., combinational relation linking that extracts a subgraph pattern to match the compound phrase (e.g. mother-in-law). In this paper, we focus on the task of combinational relation linking over knowledge graphs. To resolve the problem, we design a systematic method based on the data-driven relation assembly technique, which is performed under the guidance of meta patterns. We also introduce external knowledge to enhance the system understanding ability. Finally, we conduct extensive experiments over the real knowledge graph to study the performance of the proposed method.