 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Spectral Denoising with Global-Context Attention for Multi-Behavior Recommendation
Jun 01, 2026Multi-behavior recommendation improves target-behavior prediction by exploiting heterogeneous auxiliary feedback (e.g., view, collect, and cart), yet its robustness is undermined by behavior-dependent noise and inconsistency. We argue that the key bottleneck is a representation-level failure caused by two coupled heterogeneities. First, intra-behavior representation entanglement arises when multi-hop propagation blends incidental signals with true preferences in the embedding space, making coarse spatial denoising unable to suppress noise without sacrificing informative niche signals. Second, inter-behavior reliability heterogeneity complicates cross-behavior fusion because the predictive value of auxiliary behaviors varies across users and contexts. Without reliability calibration, frequent yet unreliable signals may dominate aggregation and cause target-intent drift. To address this bottleneck, we propose Dynamic Spectral Denoising with Global-Context Attention for Multi-Behavior Recommendation (SpectraMB), a target-oriented model that performs representation purification before reliability-aware fusion. SpectraMB introduces Dynamic Feature-Level Spectral Filtering, which re-parameterizes embeddings along the feature dimension into a feature-frequency space and learns view-adaptive spectral modulation under target supervision, enabling component-wise purification without hand-crafted frequency assumptions. It further proposes Global-Context Attention Fusion, which uses a purified global representation as a context anchor to assess view compatibility and perform reliability-aware aggregation, while a residual global backbone preserves collaborative structure. Extensive experiments on three real-world datasets show that SpectraMB achieves the best results in most evaluation settings and exhibits improved robustness under noisy interactions.
Urban Flood Observations (UFO): A hand-labeled training and validation dataset of post-flood inundation
Apr 24, 2026Urban flooding affects lives and infrastructure worldwide. Mapping inundation in complex urban environments from satellite imagery remains challenging due to limited spatial resolution, infrequent acquisitions, and cloud cover. We present Urban Flood Observations (UFO), a global, hand-labeled dataset of post-flood inundation in diverse urban settings. UFO comprises 215 image chips (1024 by 1024 pixels) from 14 flood events between 2017 and 2021, derived from 3 m PlanetScope imagery. Each chip is annotated with two classes: 'inundated' (all visible surface water, including floodwater and pre-existing water bodies (permanent or seasonal)) and 'non-inundated'. To demonstrate the dataset's utility, we trained a segmentation model using leave-one-event-out cross-validation, achieving a mean Intersection over Union (IoU) of 77.3. We also used UFO to evaluate two widely used surface water products, the Sentinel-1-based NASA IMPACT model and Google's 10 m Dynamic World water class, which yielded IoUs of 44.1 and 48.1, respectively. UFO is publicly available to support the development and validation of urban inundation mapping methods.
Modeling Stage-wise Evolution of User Interests for News Recommendation
Mar 11, 2026Personalized news recommendation is highly time-sensitive, as user interests are often driven by emerging events, trending topics, and shifting real-world contexts. These dynamics make it essential to model not only users' long-term preferences, which reflect stable reading habits and high-order collaborative patterns, but also their short-term, context-dependent interests that change rapidly over time. However, most existing approaches rely on a single static interaction graph, which struggles to capture both long-term preference patterns and short-term interest changes as user behavior evolves. To address this challenge, we propose a unified framework that learns user preferences from both global and local temporal perspectives. A global preference modeling component captures long-term collaborative signals from the overall interaction graph, while a local preference modeling component partitions historical interactions into stage-wise temporal subgraphs to represent short-term dynamics. Within this module, an LSTM branch models the progressive evolution of recent interests, and a self-attention branch captures long-range temporal dependencies. Extensive experiments on two large-scale real-world datasets show that our approach consistently outperforms strong baselines and delivers fresher and more relevant recommendations across diverse user behaviors and temporal settings.
* ACM Web Conference 2026 Accepted
RMBRec: Robust Multi-Behavior Recommendation towards Target Behaviors
Jan 13, 2026Multi-behavior recommendation faces a critical challenge in practice: auxiliary behaviors (e.g., clicks, carts) are often noisy, weakly correlated, or semantically misaligned with the target behavior (e.g., purchase), which leads to biased preference learning and suboptimal performance. While existing methods attempt to fuse these heterogeneous signals, they inherently lack a principled mechanism to ensure robustness against such behavioral inconsistency. In this work, we propose Robust Multi-Behavior Recommendation towards Target Behaviors (RMBRec), a robust multi-behavior recommendation framework grounded in an information-theoretic robustness principle. We interpret robustness as a joint process of maximizing predictive information while minimizing its variance across heterogeneous behavioral environments. Under this perspective, the Representation Robustness Module (RRM) enhances local semantic consistency by maximizing the mutual information between users' auxiliary and target representations, whereas the Optimization Robustness Module (ORM) enforces global stability by minimizing the variance of predictive risks across behaviors, which is an efficient approximation to invariant risk minimization. This local-global collaboration bridges representation purification and optimization invariance in a theoretically coherent way. Extensive experiments on three real-world datasets demonstrate that RMBRec not only outperforms state-of-the-art methods in accuracy but also maintains remarkable stability under various noise perturbations. For reproducibility, our code is available at https://github.com/miaomiao-cai2/RMBRec/.
LangGrasp: Leveraging Fine-Tuned LLMs for Language Interactive Robot Grasping with Ambiguous Instructions
Oct 02, 2025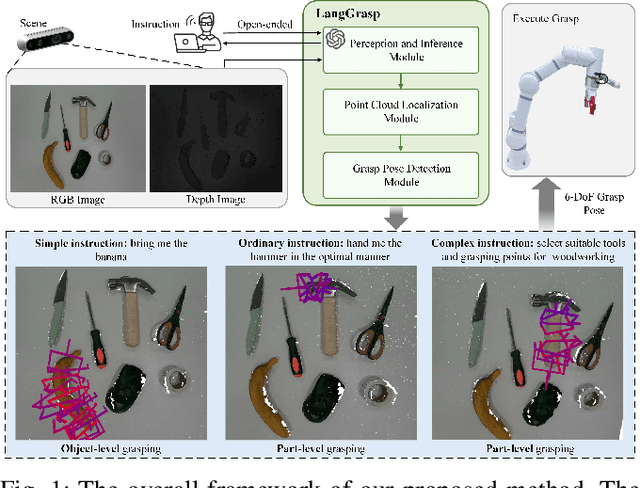
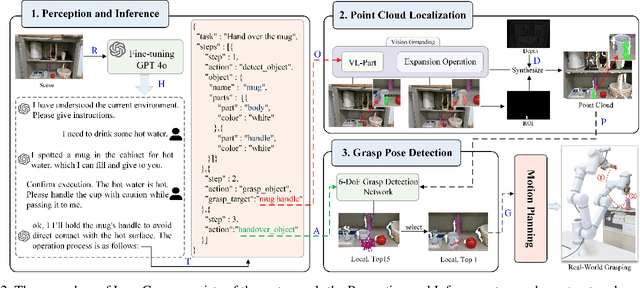

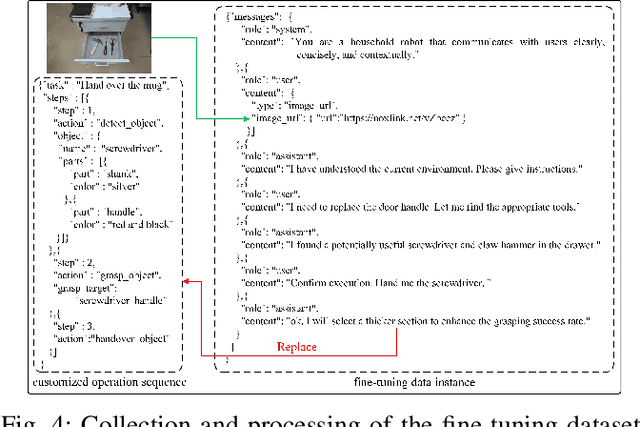
The existing language-driven grasping methods struggle to fully handle ambiguous instructions containing implicit intents. To tackle this challenge, we propose LangGrasp, a novel language-interactive robotic grasping framework. The framework integrates fine-tuned large language models (LLMs) to leverage their robust commonsense understanding and environmental perception capabilities, thereby deducing implicit intents from linguistic instructions and clarifying task requirements along with target manipulation objects. Furthermore, our designed point cloud localization module, guided by 2D part segmentation, enables partial point cloud localization in scenes, thereby extending grasping operations from coarse-grained object-level to fine-grained part-level manipulation. Experimental results show that the LangGrasp framework accurately resolves implicit intents in ambiguous instructions, identifying critical operations and target information that are unstated yet essential for task completion. Additionally, it dynamically selects optimal grasping poses by integrating environmental information. This enables high-precision grasping from object-level to part-level manipulation, significantly enhancing the adaptability and task execution efficiency of robots in unstructured environments. More information and code are available here: https://github.com/wu467/LangGrasp.
Pseudocode-Injection Magic: Enabling LLMs to Tackle Graph Computational Tasks
Jan 23, 2025Graph computational tasks are inherently challenging and often demand the development of advanced algorithms for effective solutions. With the emergence of large language models (LLMs), researchers have begun investigating their potential to address these tasks. However, existing approaches are constrained by LLMs' limited capability to comprehend complex graph structures and their high inference costs, rendering them impractical for handling large-scale graphs. Inspired by human approaches to graph problems, we introduce a novel framework, PIE (Pseudocode-Injection-Enhanced LLM Reasoning for Graph Computational Tasks), which consists of three key steps: problem understanding, prompt design, and code generation. In this framework, LLMs are tasked with understanding the problem and extracting relevant information to generate correct code. The responsibility for analyzing the graph structure and executing the code is delegated to the interpreter. We inject task-related pseudocodes into the prompts to further assist the LLMs in generating efficient code. We also employ cost-effective trial-and-error techniques to ensure that the LLM-generated code executes correctly. Unlike other methods that require invoking LLMs for each individual test case, PIE only calls the LLM during the code generation phase, allowing the generated code to be reused and significantly reducing inference costs. Extensive experiments demonstrate that PIE outperforms existing baselines in terms of both accuracy and computational efficiency.
A Correction of Pseudo Log-Likelihood Method
Mar 26, 2024Pseudo log-likelihood is a type of maximum likelihood estimation (MLE) method used in various fields including contextual bandits, influence maximization of social networks, and causal bandits. However, in previous literature \citep{li2017provably, zhang2022online, xiong2022combinatorial, feng2023combinatorial1, feng2023combinatorial2}, the log-likelihood function may not be bounded, which may result in the algorithm they proposed not well-defined. In this paper, we give a counterexample that the maximum pseudo log-likelihood estimation fails and then provide a solution to correct the algorithms in \citep{li2017provably, zhang2022online, xiong2022combinatorial, feng2023combinatorial1, feng2023combinatorial2}.
PIPO-Net: A Penalty-based Independent Parameters Optimization Deep Unfolding Network
Nov 04, 2023



Compressive sensing (CS) has been widely applied in signal and image processing fields. Traditional CS reconstruction algorithms have a complete theoretical foundation but suffer from the high computational complexity, while fashionable deep network-based methods can achieve high-accuracy reconstruction of CS but are short of interpretability. These facts motivate us to develop a deep unfolding network named the penalty-based independent parameters optimization network (PIPO-Net) to combine the merits of the above mentioned two kinds of CS methods. Each module of PIPO-Net can be viewed separately as an optimization problem with respective penalty function. The main characteristic of PIPO-Net is that, in each round of training, the learnable parameters in one module are updated independently from those of other modules. This makes the network more flexible to find the optimal solutions of the corresponding problems. Moreover, the mean-subtraction sampling and the high-frequency complementary blocks are developed to improve the performance of PIPO-Net. Experiments on reconstructing CS images demonstrate the effectiveness of the proposed PIPO-Net.
Bandit Multi-linear DR-Submodular Maximization and Its Applications on Adversarial Submodular Bandits
May 21, 2023
We investigate the online bandit learning of the monotone multi-linear DR-submodular functions, designing the algorithm $\mathtt{BanditMLSM}$ that attains $O(T^{2/3}\log T)$ of $(1-1/e)$-regret. Then we reduce submodular bandit with partition matroid constraint and bandit sequential monotone maximization to the online bandit learning of the monotone multi-linear DR-submodular functions, attaining $O(T^{2/3}\log T)$ of $(1-1/e)$-regret in both problems, which improve the existing results. To the best of our knowledge, we are the first to give a sublinear regret algorithm for the submodular bandit with partition matroid constraint. A special case of this problem is studied by Streeter et al.(2009). They prove a $O(T^{4/5})$ $(1-1/e)$-regret upper bound. For the bandit sequential submodular maximization, the existing work proves an $O(T^{2/3})$ regret with a suboptimal $1/2$ approximation ratio (Niazadeh et al. 2021).
Quantum Multi-Armed Bandits and Stochastic Linear Bandits Enjoy Logarithmic Regrets
May 30, 2022
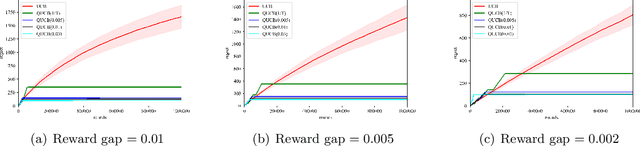
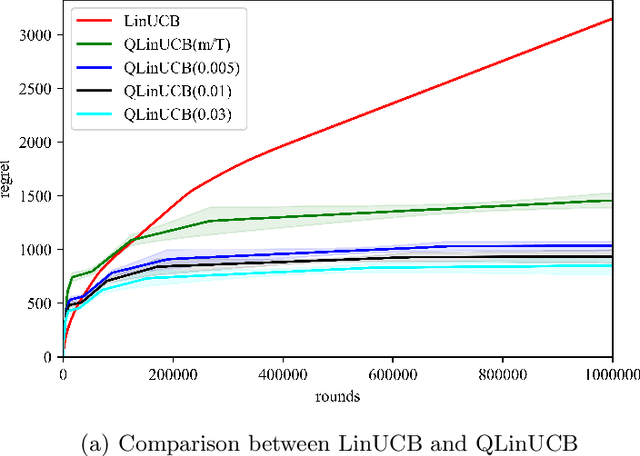
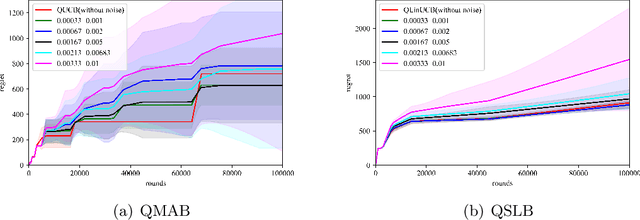
Multi-arm bandit (MAB) and stochastic linear bandit (SLB) are important models in reinforcement learning, and it is well-known that classical algorithms for bandits with time horizon $T$ suffer $\Omega(\sqrt{T})$ regret. In this paper, we study MAB and SLB with quantum reward oracles and propose quantum algorithms for both models with $O(\mbox{poly}(\log T))$ regrets, exponentially improving the dependence in terms of $T$. To the best of our knowledge, this is the first provable quantum speedup for regrets of bandit problems and in general exploitation in reinforcement learning. Compared to previous literature on quantum exploration algorithms for MAB and reinforcement learning, our quantum input model is simpler and only assumes quantum oracles for each individual arm.