 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvo-ViT: Slow-Fast Token Evolution for Dynamic Vision Transformer
Paper and Code
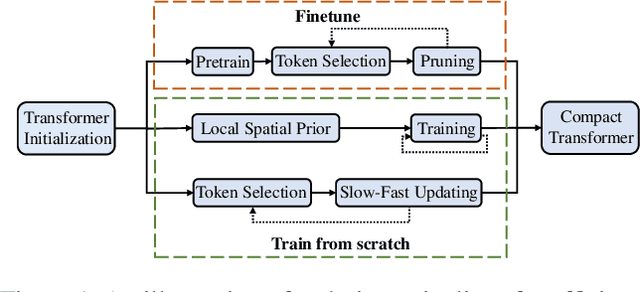
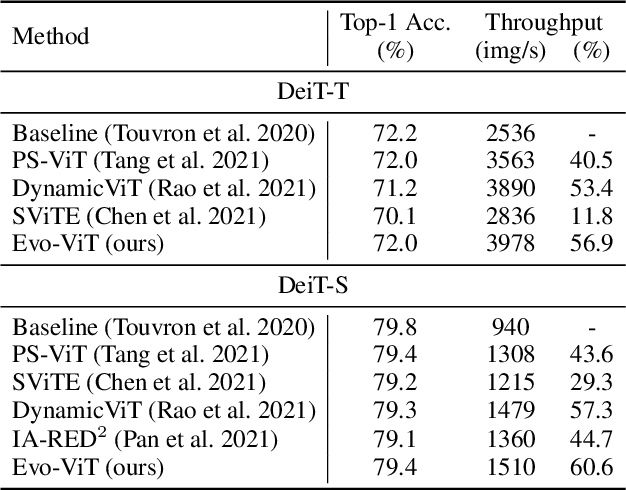
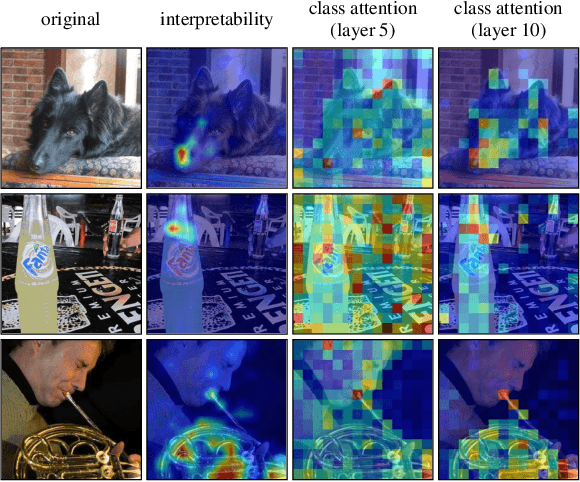
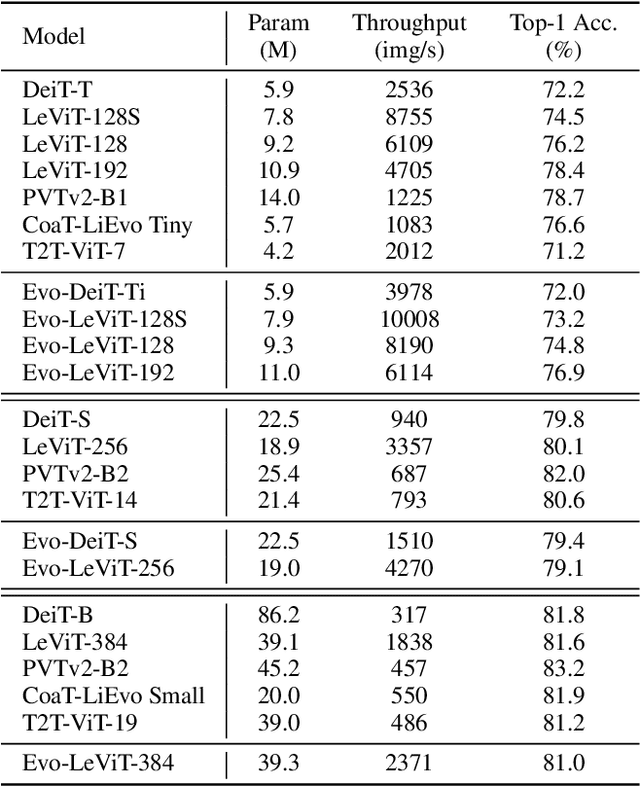
Vision transformers have recently received explosive popularity, but the huge computational cost is still a severe issue. Recent efficient designs for vision transformers follow two pipelines, namely, structural compression based on local spatial prior and non-structural token pruning. However, token pruning breaks the spatial structure that is indispensable for local spatial prior. To take advantage of both two pipelines, this work seeks to dynamically identify uninformative tokens for each instance and trim down both the training and inference complexity while maintaining complete spatial structure and information flow. To achieve this goal, we propose Evo-ViT, a self-motivated slow-fast token evolution method for vision transformers. Specifically, we conduct unstructured instance-wise token selection by taking advantage of the global class attention that is unique to vision transformers. Then, we propose to update informative tokens and placeholder tokens that contribute little to the final prediction with different computational priorities, namely, slow-fast updating. Thanks to the slow-fast updating mechanism that guarantees information flow and spatial structure, our Evo-ViT can accelerate vanilla transformers of both flat and deep-narrow structures from the very beginning of the training process. Experimental results demonstrate that the proposed method can significantly reduce the computational costs of vision transformers while maintaining comparable performance on image classification. For example, our method accelerates DeiTS by over 60% throughput while only sacrificing 0.4% top-1 accuracy.